
flinkcdc 能通过快照id 去消费吗?
flinkcdc 能通过快照id 去消费吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
是的,Flink CDC可以通过快照ID去消费数据。在Flink CDC中,我们可以使用enableSnapshotMode()方法开启快照模式,这样就可以通过指定的快照ID来消费数据。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<Row> source = env.addSource(new FlinkKafkaConsumer09("topic", new RowSchema(), props)); source.print(); // 开启快照模式 source.enableCheckpointing(1000); // 设置checkpoint间隔为1秒 source.disableChaining(); // 禁用数据流链式执行 source.uid("MyJob"); // 为数据流分配唯一的job ID // 提交任务 env.execute("Flink CDC Example");将数据源添加到Flink应用程序中,并为其分配了一个唯一的job ID。然后,我们使用enableCheckpointing()方法来开启checkpoint功能,并将checkpoint间隔设置为1秒。最后,我们使用uid()方法为数据流分配一个唯一的ID,以便我们在需要回滚到某个快照时能够唯一标识该数据流
2023-08-22 23:35:34赞同 展开评论 -
十分耕耘,一定会有一分收获!
楼主你好,阿里云 Flink CDC 支持使用快照 ID 来消费数据。
在 Flink CDC 中,你可以使用快照 ID 来指定起始的消费位置,然后从该位置开始消费数据。具体方法如下:
使用命令
SHOW SNAPSHOTS;来查看所有可用的快照 ID。选择一个合适的快照 ID,然后使用以下命令来创建一个新的 CDC 消费任务,并指定快照 ID:
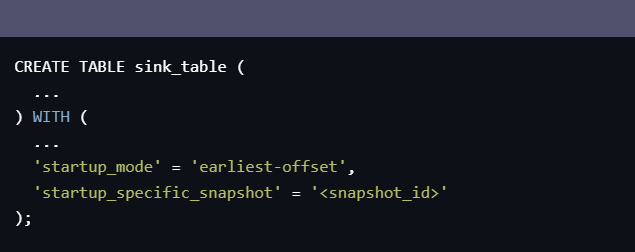
CREATE TABLE sink_table ( ... ) WITH ( ... 'startup_mode' = 'earliest-offset', 'startup_specific_snapshot' = '<snapshot_id>' );在上面的命令中,将
'startup_mode'参数设置为'earliest-offset',表示从指定的快照 ID 开始消费数据。同时,将'startup_specific_snapshot'参数设置为你选择的快照 ID。- 启动 CDC 消费任务后,它会从指定的快照 ID 开始消费数据。最后再来看一下这个:

注意,如果指定的快照 ID 已经被删除,或者 CDC 日志中没有该快照 ID 的信息,则启动任务时会失败。因此,建议在选择快照 ID 时,先使用
SHOW SNAPSHOTS;命令来查看所有可用的快照 ID,并根据实际情况进行选择。2023-08-21 12:42:48赞同 展开评论 -
Flink CDC 支持通过快照 ID 来消费数据。在 Flink CDC 中,每个表都有一个快照 ID,表示当前表的状态。当您启动 Flink CDC 时,可以指定一个快照 ID,Flink CDC 将从该快照 ID 开始消费数据。使用快照 ID 消费数据的步骤如下:
- 获取表的当前快照 ID。您可以使用 Flink CDC 的命令行工具或者 API 来获取表的当前快照 ID。
- 启动 Flink CDC 并指定要从哪个快照 ID 开始消费数据。您可以使用 Flink CDC 的命令行参数或者配置文件来指定要从哪个快照 ID 开始消费数据。
例如,在命令行中启动 Flink CDC 并从快照 ID 为 100 的位置开始消费数据,可以使用以下命令:
./bin/flink run -c com.alibaba.ververica.cdc.debezium.task.DebeziumTask \ -p 1 \ -yid <yarn-session-id> \ -ys <yarn-session-conf-dir> \ -Dcdc.snapshot.id=100 \ /path/to/cdc.jar在配置文件中指定从快照 ID 为 100 的位置开始消费数据,可以在配置文件中添加以下配置项:
cdc.snapshot.id=100使用快照 ID 消费数据时,如果快照 ID 对应的数据已经被删除或者过期,可能会导致消费失败。因此,在使用快照 ID 消费数据时,需要确保快照 ID 对应的数据仍然存在。
2023-08-16 10:00:38赞同 1 展开评论 -
北京阿里云ACE会长
Apache Flink的CDC(Change Data Capture)库不直接支持通过快照ID进行消费。CDC库主要用于捕获和处理数据源中的变化,并将这些变化作为数据流发送到Flink作业中进行处理。
快照ID通常用于标识数据源中的某个特定时间点的快照状态。在Flink中,快照ID通常与状态后端(如RocksDB)相关联,用于管理和恢复作业的状态。
如果您希望基于特定快照ID来消费数据,您可能需要考虑以下方法之一:
使用Flink的状态后端:如果您使用的是支持快照的状态后端(如RocksDB),您可以将快照ID与作业的状态相关联。然后,您可以在作业中自定义处理逻辑,使其在特定快照ID的基础上消费数据。
扩展Flink CDC库:如果您有特定的需求,您可以考虑扩展Flink的CDC库以支持通过快照ID进行消费。这将涉及修改CDC库的源代码,并实现您自己的消费逻辑。
2023-08-14 18:34:14赞同 展开评论 -
全栈JAVA领域创作者
是的,Flink CDC可以通过快照ID去消费快照信息。在Flink CDC中,您可以使用Snapshot功能,对整个数据源表进行快照,并将快照信息写入目标数据库中。每个快照都会有一个唯一的快照ID,您可以使用该快照ID,去消费快照信息。
需要注意的是,如果您使用Flink CDC消费快照信息,那么您需要注意以下几点:在启动Flink CDC任务时,需要指定snapshot参数和snapshotPath参数,以启用Snapshot功能。
在配置文件中,需要指定snapshot参数和snapshotPath参数,以指定Snapshot功能的参数。
在配置文件中,需要指定fetchInterval参数,以指定从数据源表中读取数据的时间间隔。如果您的数据源表中存在大量数据,那么可以适当增加fetchInterval参数的值,以提高数据同步速度。
在配置文件中,需要指定fetchTimeout参数,以指定从数据源表中读取数据的超时时间。如果您的数据源表中存在大量数据,那么可以适当增加fetchTimeout参数的值,以提高数据同步速度。
需要注意的是,如果您在生产环境中使用Flink CDC消费快照信息,那么您需要考虑Flink CDC的资源使用情况。例如,您需要确保Flink CDC有足够的内存和CPU资源,以保证数据处理和同步的效率和稳定性。同时,您还需要确保Flink CDC的数据备份和恢复机制,以保证数据的安全性和可靠性。2023-08-14 13:37:04赞同 展开评论 -
是的,Flink CDC可以通过快照ID去消费。在Flink CDC中,我们可以使用
enableSnapshotMode()方法来开启快照模式,这样就可以通过指定的快照ID来消费数据。以下是一个简单的示例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<Row> source = env.addSource(new FlinkKafkaConsumer09("topic", new RowSchema(), props)); source.print(); // 开启快照模式 source.enableCheckpointing(1000); // 设置checkpoint间隔为1秒 source.disableChaining(); // 禁用数据流链式执行 source.uid("MyJob"); // 为数据流分配唯一的job ID // 提交任务 env.execute("Flink CDC Example");
在这个示例中,我们将数据源添加到Flink应用程序中,并为其分配了一个唯一的job ID。然后,我们使用
enableCheckpointing()方法来开启checkpoint功能,并将checkpoint间隔设置为1秒。最后,我们使用uid()方法为数据流分配一个唯一的ID,以便我们在需要回滚到某个快照时能够唯一标识该数据流。
当我们想要回滚到某个特定的快照时,我们可以使用
setRestorePoint()方法来设置我们要回滚到的快照ID。例如:```java
// 设置回滚点
final long checkpointId = 4L;
final long timestamp = 1587433595000L;
final String savepointPath = "/path/to/savepoint";
final List allVertices = getAllVertices();
final Execution execution = getCurrentExecutionAttempt();
execution.getJobClient().get().requestCheckpoint(checkpointId, timestamp);
execution.getJobClient().get().notifyCheckpointComplete(checkpointId, timestamp);
List keyGroupsToRestore = KeyGroupRangeAssignment.assignKeyGroupsToOperators(allVertices, jobConfiguration.getMaxParallelism());
Set stateHandles = StatefulOperatorStateBackend.loadSavedState(keyGroupsToRestore, operatorStates, fileSystemsProvider, savedpointDirectoryServiceLoader::createSavedpointDirectoryForKeygroupMappingFileAndReturnTheAbsolutePathOnSuccess, null, false, true);
for (Map.Entry> e : partitionsPerChannel.entrySet()) {
int channelIndex = e.getKey();
if ((stateHandles == null || stateHandles.isEmpty()) && isLocalRecoverySupportedByKeygroupsInChannel(channelIndex)) {
throw new IllegalStateException("No states found for channels " + Arrays.toString(channels[channelIndex]));
}
statesManager.recoverFromLocalState(e.getValue(), localRecoveryDelegateFactoryFunction.apply(operator), recoveryTarget -> handleRecoveredInputChannel(inputChannel, inputSerializer, outputSerializer, serializationSchema, deserializationSchema, target, context, streamMetrics, metricsListenerRegistry, timeCharacteristicMonitor, taskName, tupleTimestampWatermarks, watermarkGeneratorSupplier, windowAssigner, processingTimeService, clock, maxOutstandingRequestSize, outgoingEdgesOfThisSubtask, globalModifiedOffsets, modifiedOffsetsBeforeFirstElement, subtaskIndex, numNonInterruptibleActionsBeforeCutback, cutbackTrigger, sideOutputTagExtractors, internalTimerService, userCodeClassLoader, customMetricUpdates, metricQueryService, queryableStateUtil, resultIterationPointerResolver, iterationPointerCompareResultComparator, restartStrategy, restorePoint, restorationTarget, executor, loggerContext, errorReporter, defaultRuntimeContext, sqlMetricContainer, dataViewMetricsProducer, rowtimeAttributeDescriptor, lateDataOutputTag, eventTimeExtractor, currentProcessingTime, progressBarrierHandler, barrierCleanerTask, cleanShutdownBehavior, resourceManagerEndpoint, applicationStatus, slot2023-08-14 11:08:29赞同 展开评论


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。