求问各位大佬,flink1.14.5我用table api从mysql写入es,mysql源中有一个字段通过collect聚合函数默认得到了MULTISET类型,该字段需要对应输出到es的array类型中,但是报错:Exception in thread "main" java.lang.UnsupportedOperationException: JSON format doesn't support non-string as key type of map. The type is: MULTISET?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
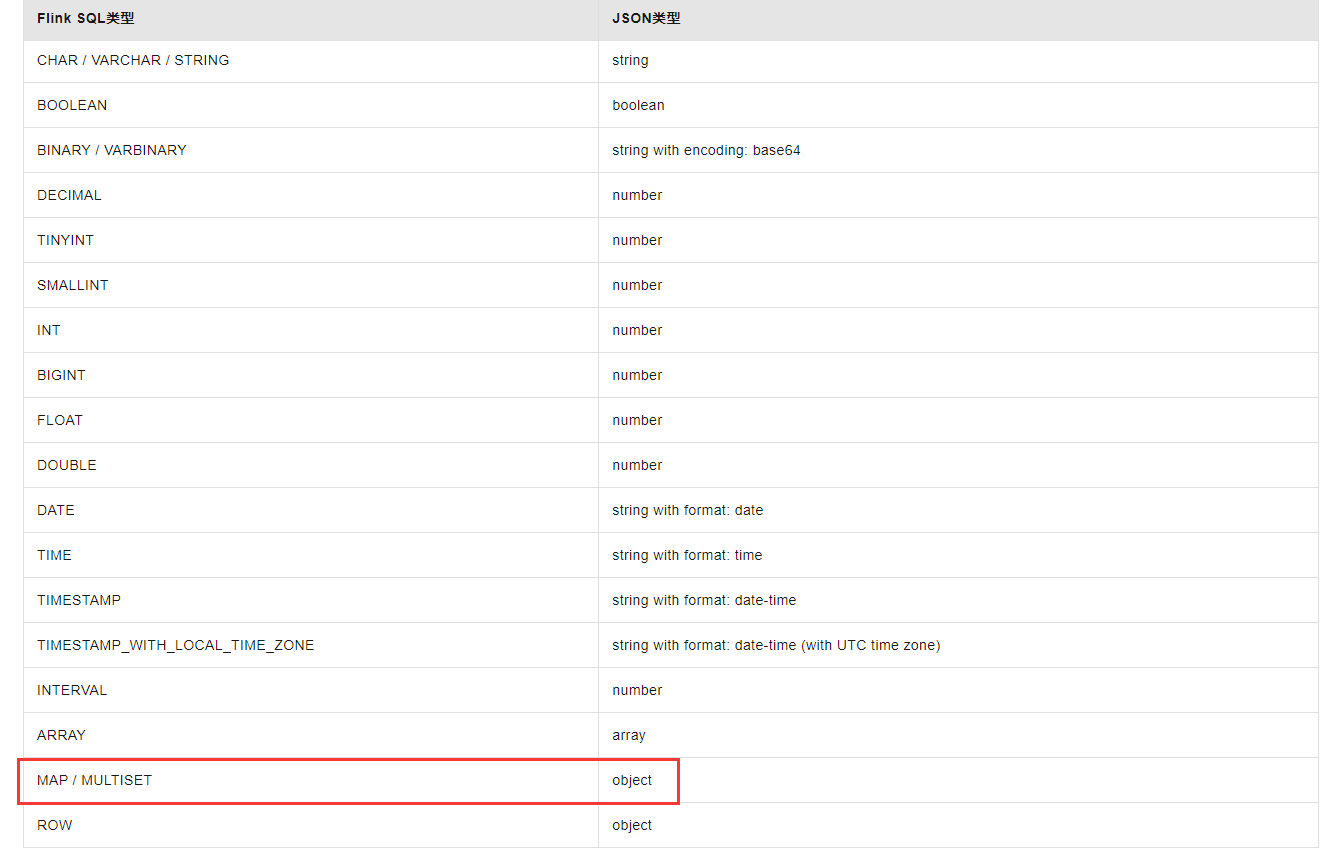
JSON 格式不支持。MULTISET类型在 MySQL中是一个集合型,包含多个值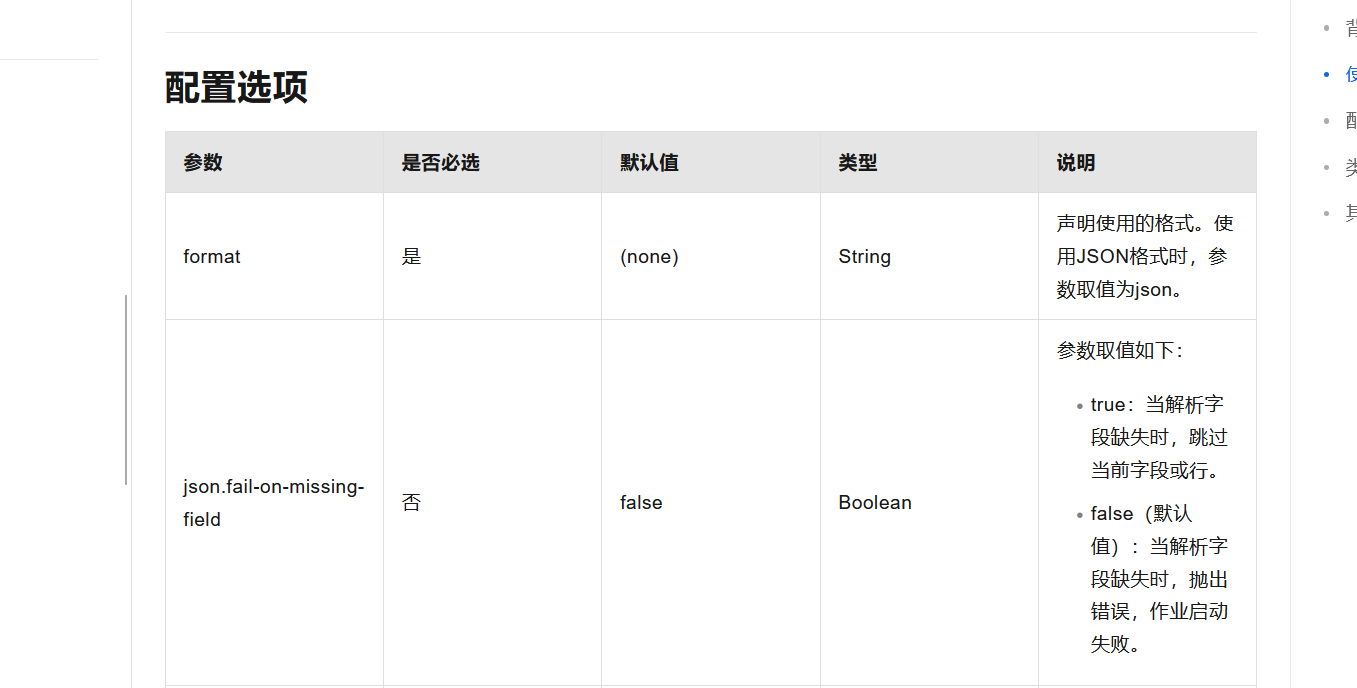
https://help.aliyun.com/zh/flink/developer-reference/json-602268?spm=a2c6h.13066369.question.13.5e0e4a01Jckwtf
你遇到的问题是由于 Flink JSON 格式不支持将非字符串类型作为 Map 的键类型导致的。根据你的描述,MULTISET 类型无法直接映射到 Elasticsearch 的 array 类型。
要解决这个问题,你可以考虑对该字段进行转换,将其转换为字符串类型或其他 Elasticsearch 支持的数据类型。以下是一种可能的解决方案:
import org.apache.flink.table.api.Types;
import org.apache.flink.table.expressions.Expression;
// 定义字段转换表达式
Expression fieldCastExpr = $("field").cast(Types.STRING);
// 在查询中使用字段转换表达式
Table resultTable = sourceTable
.select($("id"), fieldCastExpr.as("field"))
.groupBy($("id"))
.select($("id"), $("field").agg(collect(fieldCastExpr).as("field")));
// 将结果写入 Elasticsearch
resultTable.executeInsert("your_es_table");
import org.apache.flink.table.descriptors.*;
// 定义 Elasticsearch 连接器
Elasticsearch elasticsearch = new Elasticsearch()
.version("7")
.host("localhost", 9200, "http")
.index("your_index")
.documentType("_doc")
.bulkFlushMaxActions(1);
// 定义 Schema
Schema schema = new Schema()
.field("id", DataTypes.INT())
.field("field", DataTypes.ARRAY(DataTypes.STRING()));
// 定义 Elasticsearch 连接器的输出格式
elasticsearch
.inAppendMode()
.tableSchema(schema);
// 将结果写入 Elasticsearch
TableEnvironment tEnv = ...
tEnv.connect(elasticsearch)
.withFormat(new Json().deriveSchema())
.inUpsertMode()
.registerTableSink("your_sink_table");
Table resultTable = ... // 在前面的代码中定义
resultTable.insertInto("your_sink_table");
使用上述方法,你可以将 MULTISET 类型字段转换为字符串类型,并将其作为数组类型写入 Elasticsearch,避免了 JSON 格式不支持非字符串类型作为 Map 键的问题。
这个问题是因为 Flink 在处理 JSON 格式数据时,不支持非字符串类型作为 Map 的键。而你提到的 MULTISET 类型在 MySQL 中是一个集合类型,它包含多个值,但不是所有的值都是字符串类型。
解决这个问题的一种方式是在写入 Elasticsearch 之前,先将这个 MULTISET 类型的字段转换成字符串或者数组类型。这需要你在 SQL 查询中使用适当的函数或者表达式。
如果你正在使用 Flink Table API,你可以在 SQL 查询中添加一个转换函数,例如在 MySQL 中使用 CAST 函数将 MULTISET 转换为字符串,或者使用 JSON_ARRAY 函数将 MULTISET 转换为 JSON 数组。
例如,如果你的原始查询是这样的:
SELECT * FROM your_table;
你可以修改为:
SELECT CAST(your_multiset_column AS CHAR) AS your_multiset_column, * FROM your_table;
或者:
SELECT JSON_ARRAY(your_multiset_column) AS your_multiset_column, * FROM your_table;
这样,your_multiset_column 将被转换为字符串或 JSON 数组,然后再写入 Elasticsearch,就不会出现错误了。这个转换可能在某些情况下会丢失一些信息,所以你需要根据你的具体需求来选择合适的转换方式。
在 Apache Flink 1.14 版本中,当你从 MySQL 读取数据并通过 Table API 进行处理,然后将数据写入 Elasticsearch 时,遇到 MULTISET 类型字段无法正确映射至 Elasticsearch 的数组类型,这是因为 JSON 格式本身不支持非字符串类型的键作为 Map 的键,而 Flink 的 MULTISET 类型会被视为 Map-like 结构,即每个元素都有一个键和一个值,即使在您的场景中键可能隐含且统一。
为了将 MULTISET 类型的数据转换为 Elasticsearch 可以接受的数组格式,你需要显式地将 MULTISET 转换为数组。在 Flink SQL 中,你可以尝试使用 flatten 函数配合其他集合函数(如 array_agg)来完成这一转换。
假设你有一个名为 items 的 MULTISET<ANY> 字段,可以尝试如下方式:
SELECT
-- 其他字段...
ARRAY_AGG(item) AS items_array
FROM (
SELECT
-- 其他字段...
UNNEST(items) AS item
FROM your_mysql_table
) AS unnested_table
GROUP BY
-- 相应的分组条件...
这里 UNNEST 函数将 MULTISET 解构成行集合,之后 ARRAY_AGG 函数将这些行集合中的 item 字段聚合成为一个数组。
请根据实际情况调整上述 SQL 语句,以适应你的表结构和需求。如果 MULTISET 中包含嵌套结构,可能还需要进一步解构和转换。
确保你的 Elasticsearch sink connector 已经配置正确,能够接受数组类型的字段。并且注意 Flink Elasticsearch connector 对于不同数据类型的映射规则,确保目标 ES 映射(mapping)兼容转换后的数据类型。
这个问题是因为在 Flink 1.14.5 中,Table API 使用的 JSON 格式不支持将非字符串类型作为 Map 中的 key。在这种情况下,您尝试将 Flink 中的 MULTISET 类型字段写入 ES,但是失败了。
要解决这个问题,您可以尝试以下方法:
DataTypes dataTypes = new DataTypes();
dataTypes.field("multisetField", DataTypes.FIELD_TYPE_MULTISET);
// 假设您的 RowData 对象包含 multisetField 字段
RowData rowData = new RowData();
rowData.field("multisetField", new Multiset<>(List.of(1, 2, 3)));
// 使用 toJson() 方法将 Multiset 转换为 JSON 格式
String jsonString = Json.toJson(rowData.toJson(dataTypes));
// 现在,您可以将 jsonString 作为 Map 的 value 写入 ES
JSON格式不支持非字符串类型的键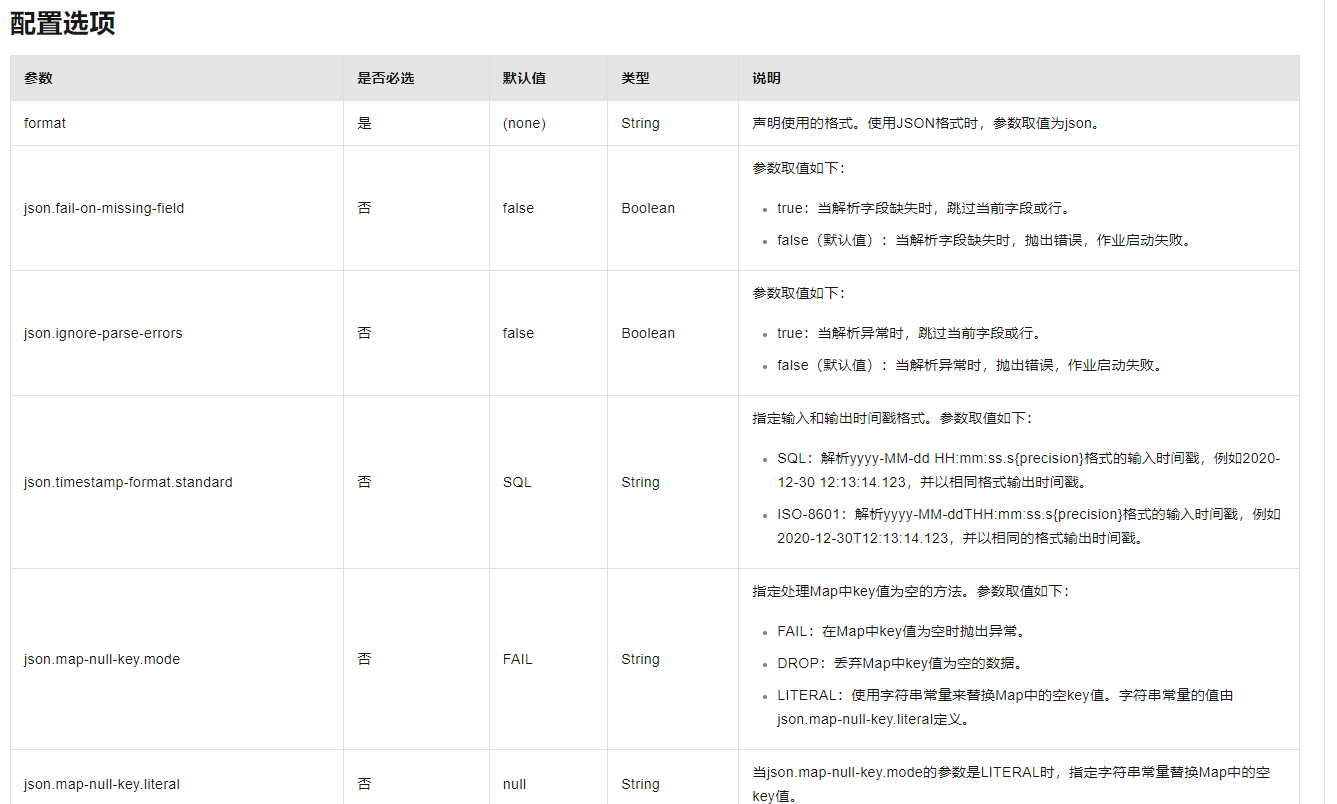
https://help.aliyun.com/zh/flink/developer-reference/json-602268?spm=a2c4g.11186623.0.i60
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。