
想问下各位大佬,使用FlinkCDC采集到Blob数据之后怎么处理,比如说我从Oracle采集,再写入到另一个Oracle?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink CDC采集到Blob数据后,可以使用以下步骤进行处理:
1、获取Blob数据:在Flink中,可以使用Flink CDC获取Blob数据流。Flink CDC是一个用于捕获MySQL或PostgreSQL数据库的变化数据的组件,可以将数据库中的变化数据作为流式数据进行处理。
2、解析Blob数据:Blob数据通常是二进制数据,需要根据具体的业务逻辑进行解析。可以根据Blob数据的格式和内容,使用适当的解析器或转换器将Blob数据转换为可处理的格式,例如JSON、CSV等。
3、数据处理:一旦Blob数据被解析为可处理的格式,可以使用Flink提供的各种算子来对数据进行处理。例如,可以使用Map、Filter、Reduce等算子对数据进行转换、过滤、聚合等操作。
4、结果输出:根据具体的需求,可以选择将处理后的数据输出到不同的目标。可以将结果写入文件、发送到消息队列、存储到数据库等。Flink提供了丰富的Sink算子用于将结果输出到不同的目标。
总结:Flink CDC采集到Blob数据后,需要对Blob数据进行解析,然后使用Flink提供的算子对数据进行处理,最后将处理结果输出到目标位置。具体的处理和输出方式取决于业务需求和数据格式。
楼主你好,使用阿里云FlinkCDC采集到Blob数据之后,可以通过以下步骤来将数据写入到另一个Oracle中:
1、使用FlinkCDC将Blob数据采集到Flink中,可以通过以下代码来实现: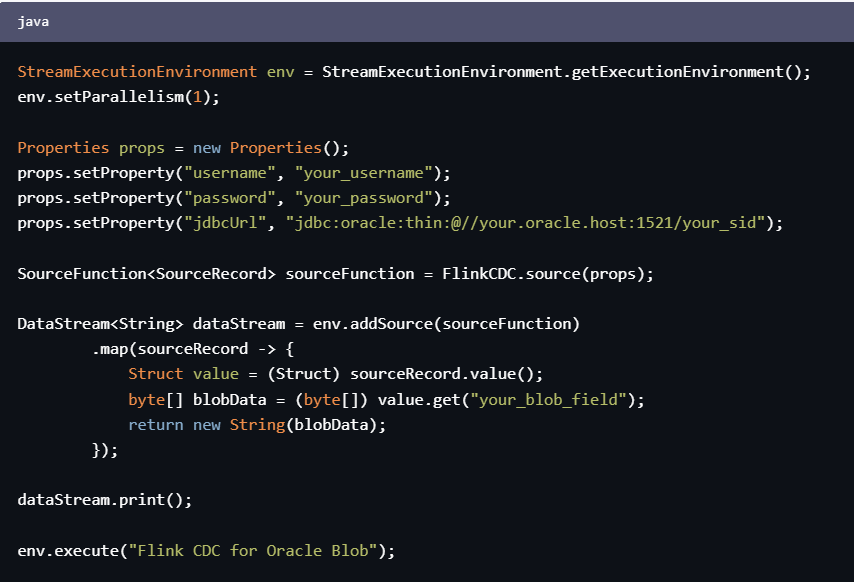
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties props = new Properties();
props.setProperty("username", "your_username");
props.setProperty("password", "your_password");
props.setProperty("jdbcUrl", "jdbc:oracle:thin:@//your.oracle.host:1521/your_sid");
SourceFunction<SourceRecord> sourceFunction = FlinkCDC.source(props);
DataStream<String> dataStream = env.addSource(sourceFunction)
.map(sourceRecord -> {
Struct value = (Struct) sourceRecord.value();
byte[] blobData = (byte[]) value.get("your_blob_field");
return new String(blobData);
});
dataStream.print();
env.execute("Flink CDC for Oracle Blob");
2、 将Blob数据转换为文本数据,并使用Flink JDBC Sink写入到另一个Oracle中,可以通过以下代码来实现: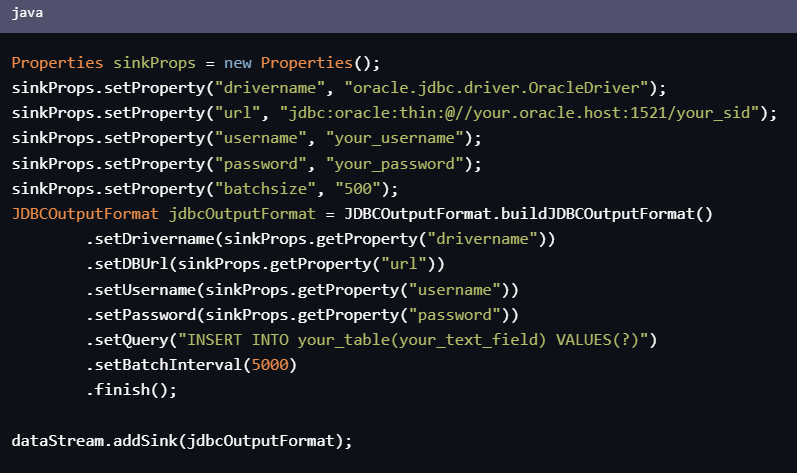
Properties sinkProps = new Properties();
sinkProps.setProperty("drivername", "oracle.jdbc.driver.OracleDriver");
sinkProps.setProperty("url", "jdbc:oracle:thin:@//your.oracle.host:1521/your_sid");
sinkProps.setProperty("username", "your_username");
sinkProps.setProperty("password", "your_password");
sinkProps.setProperty("batchsize", "500");
JDBCOutputFormat jdbcOutputFormat = JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername(sinkProps.getProperty("drivername"))
.setDBUrl(sinkProps.getProperty("url"))
.setUsername(sinkProps.getProperty("username"))
.setPassword(sinkProps.getProperty("password"))
.setQuery("INSERT INTO your_table(your_text_field) VALUES(?)")
.setBatchInterval(5000)
.finish();
dataStream.addSink(jdbcOutputFormat);
其中,需要根据实际情况替换代码中的your_blob_field、your_table和your_text_field字段名称、your_username、your_password、your.oracle.host、your_sid等参数。
以上就是使用阿里云FlinkCDC采集到Blob数据之后写入到另一个Oracle的处理方法。
在使用 Flink CDC 采集 Oracle 数据库中的 Blob 数据时,需要注意 Blob 数据的大小和类型。Blob 数据通常存储二进制数据,例如图片、音频、视频等,如果 Blob 数据较大,可能会影响性能和稳定性。
处理 Blob 数据的一般步骤如下:
以下是一个示例代码,演示了如何在 Flink CDC 中处理 Oracle 数据库中的 Blob 数据,并将数据写入另一个 Oracle 数据库:
public class OracleBlobProcessor implements DebeziumDeserializationSchema<RowData> {
private final TypeInformation<RowData> typeInfo;
private final String sourceColumn;
private final String targetColumn;
public OracleBlobProcessor(TypeInformation<RowData> typeInfo, String sourceColumn, String targetColumn) {
this.typeInfo = typeInfo;
this.sourceColumn = sourceColumn;
this.targetColumn = targetColumn;
}
@Override
public void deserialize(SourceRecord sourceRecord, Collector<RowData> collector) throws Exception {
Struct value = (Struct) sourceRecord.value();
Object blobValue = value.get(sourceColumn);
if (blobValue instanceof byte[]) {
byte[] blobBytes = (byte[]) blobValue;
// 将 Blob 数据转换为字符串
String stringValue = new String(blobBytes, StandardCharsets.UTF_8);
// 创建一个新的 RowData 对象,并将转换后的数据写入其中
GenericRowData rowData = new GenericRowData(2);
rowData.setField(0, value.get("id"));
rowData.setField(1, stringValue);
collector.collect(rowData);
}
}
@Override
public TypeInformation<RowData> getProducedType() {
return typeInfo;
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置 Flink CDC 的源表和目标表信息
Properties properties = new Properties();
properties.setProperty("database.server.name", "oracle-source");
properties.setProperty("database.hostname", "localhost");
properties.setProperty("database.port", "1521");
properties.setProperty("database.user", "user");
properties.setProperty("database.password", "password");
properties.setProperty("database.dbname", "dbname");
properties.setProperty("table.whitelist", "table1");
properties.setProperty("schema.pattern", "schema1");
properties.setProperty("snapshot.mode", "initial");
properties.setProperty("debezium.snapshot.select.statement.overrides.table1", "SELECT * FROM schema1.table1 WHERE id > 0");
// 创建 Flink CDC 数据流
FlinkCDCSource<RowData> source = FlinkCDCSource.<RowData>builder()
.setProperties(properties)
.setDeserializer(new OracleBlobProcessor(
Types.ROW(Types.INT, Types.STRING),
"blob_column",
"target_blob_column"
))
.build();
// 将数据写入目标 Oracle 数据库
JdbcOutputFormat jdbcOutputFormat = JdbcOutputFormat.buildJdbcOutputFormat()
.setDrivername("oracle.jdbc.driver.OracleDriver")
.setDBUrl("jdbc:oracle:thin:@//localhost:1521/dbname")
.setUsername("user")
.setPassword("password")
.setQuery("INSERT INTO schema2.table2 (id, blob_column) VALUES (?, ?)")
.setSqlTypes(new int[]{Types.INTEGER, Types.VARBINARY})
.finish();
DataStream<RowData> stream = env.addSource(source);
stream.addSink(jdbcOutputFormat);
env.execute();
}
}
上述示例代码中,我们首先创建了一个自定义的反序列化器 `OracleBlobProcessor
当使用 Flink CDC 采集到包含 BLOB 数据的变更时,您可以通过以下步骤处理并将其写入另一个 Oracle 数据库:
提取 BLOB 数据:Flink CDC 会将 BLOB 数据以字节数组的形式提供给您。您可以使用 Flink 的 RichMapFunction 或 ProcessFunction 等转换函数来处理记录,并提取 BLOB 数据。
转换 BLOB 数据:一旦您提取了 BLOB 数据,您可以根据需要进行进一步的转换或处理。这可能涉及将字节数组转换为字符串、解析为图像或其他二进制格式等。您可以根据数据的实际内容和格式编写自定义的转换逻辑。
写入另一个 Oracle 数据库:一旦您完成了 BLOB 数据的处理和转换,您可以使用 Flink 的 JDBC Sink 或自定义的 Sink 函数将数据写入另一个 Oracle 数据库。通过配置连接信息和执行插入语句,您可以将处理后的数据写入目标数据库中。
以下是一个简单的示例代码,展示了如何在 Flink CDC 中处理和写入包含 BLOB 数据的变更:
java
Copy
// 提取 BLOB 数据并转换
DataStream processedData = cdcDataStream.map(new RichMapFunction() {
@Override
public Row map(Row row) throws Exception {
// 提取 BLOB 数据
byte[] blobData = (byte[]) row.getField(blobColumnIndex);
// 进行转换或处理
String processedBlob = processBlob(blobData);
// 构造新的 Row 对象
Row newRow = new Row(row.getArity());
newRow.setField(blobColumnIndex, processedBlob);
// 设置其他字段值
return newRow;
}
});
// 写入另一个 Oracle 数据库
processedData.addSink(JdbcSink.sink(
"INSERT INTO target_table (blob_column, other_columns) VALUES (?, ?)",
(ps, value) -> {
// 设置参数
ps.setString(1, value.getField(blobColumnIndex));
// 设置其他参数
},
JdbcExecutionOptions.builder()
.withBatchSize(100)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl(targetDbUrl)
.withDriverName(targetDbDriver)
.withUsername(targetDbUsername)
.withPassword(targetDbPassword)
.build()
));
// 执行作业
env.execute("CDC Job");
请注意,上述代码仅为示例,您需要根据实际情况进行适当的调整和修改。确保配置正确的连接信息、表名、字段索引等,并根据您的数据格式和需求编写相应的处理逻辑。
此外,还要注意处理 BLOB 数据可能涉及到的内存消耗和性能问题。如果 BLOB 数据较大,您可能需要考虑使用流式处理、分批处理或异步写入等方法来优化性能和资源利用。
如果您使用Flink CDC采集到Blob数据之后,想要将其写入到另一个Oracle数据库中,那么您可以使用TableFunction接口,实现自定义的TableFunction函数,将Blob数据写入到目标数据库中。具体来说,您可以在TableFunction函数中,使用Blob类型的变量,读取和写入Blob数据。
需要注意的是,如果您在生产环境中使用Flink CDC同步Blob数据,那么您需要考虑Flink CDC的资源使用情况。例如,您需要确保Flink CDC有足够的内存和CPU资源,以保证数据处理和同步的效率和稳定性。同时,您还需要确保Flink CDC的数据备份和恢复机制,以保证数据的安全性和可靠性。
如果您在使用 Flink CDC (Change Data Capture) 采集 Blob 数据后想要将其写入到另一个 Oracle 数据库中,您可以考虑以下几种方法:
使用 Flink 的 JDBC 输出器将 Blob 数据写入到 Oracle 数据库中。Flink 的 JDBC 输出器可以将 Blob 数据转换为 Oracle 数据库中的 BLOB 数据类型,并将其写入到 Oracle 数据库中。
使用 Flink 的 Kafka 输出器将 Blob 数据写入到 Kafka 中,然后使用 Kafka Connector 将 Kafka 中的 Blob 数据写入到 Oracle 数据库中。Flink 的 Kafka 输出器可以将 Blob 数据转换为 Kafka 中的 Blob 数据类型,并将其写入到 Kafka 中。然后,您可以使用 Kafka Connector 将 Kafka 中的 Blob 数据写入到 Oracle 数据库中。
使用 Flink 的 Hadoop 输出器将 Blob 数据写入到 Hadoop 文件系统中,然后使用 Hadoop Connector 将 Hadoop 文件系统中的 Blob 数据写入到 Oracle 数据库中。Flink 的 Hadoop 输出器可以将 Blob 数据转换为 Hadoop 文件系统中的 Blob 数据类型,并将其写入到 Hadoop 文件系统中。然后,您可以使用 Hadoop Connector 将 Hadoop 文件系统中的 Blob 数据写入到 Oracle 数据库中。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


