
问题一:https://logview.aliyun.com/logview/?h=http://service.cn.maxcompute.aliyun-inc.com/api&p=renlijia_ng&i=20230529082644820gdfv61m9mcr4&token=a2MxYkdIbXZNdVVSbGRnY2hKVlFlaVR3OG93PSxPRFBTX09CTzoxMDc4MjA5MDIxMTI1NjA5LDE2ODc5NDA4MDUseyJTdGF0ZW1lbnQiOlt7IkFjdGlvbiI6WyJvZHBzOlJlYWQiXSwiRWZmZWN0IjoiQWxsb3ciLCJSZXNvdXJjZSI6WyJhY3M6b2RwczoqOnByb2plY3RzL3JlbmxpamlhX25nL2luc3RhbmNlcy8yMDIzMDUyOTA4MjY0NDgyMGdkZnY2MW05bWNyNCJdfV0sIlZlcnNpb24iOiIxIn0= MaxCompute这个sql执行好慢呀,不太理解为什么,一直a表都没读? 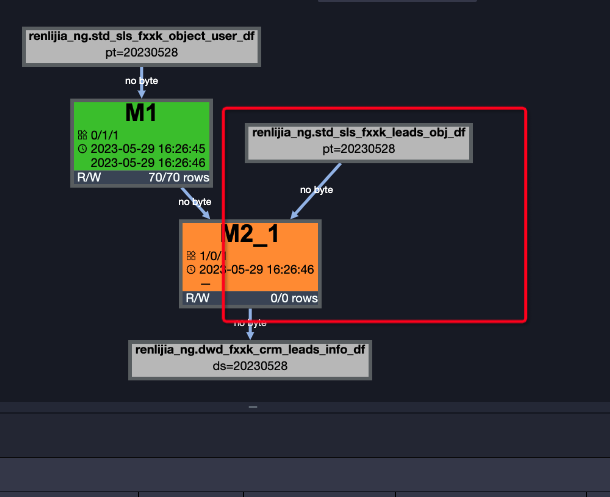
5分钟了,都没跑完,就20万数据,刚跑完
问题二:我调小是可以,但是之前也是get_json_obect ,我之前其他节点设置的50就不错,到这里要分成10,和json数据的大小也有关系对吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
针对问题一的回答: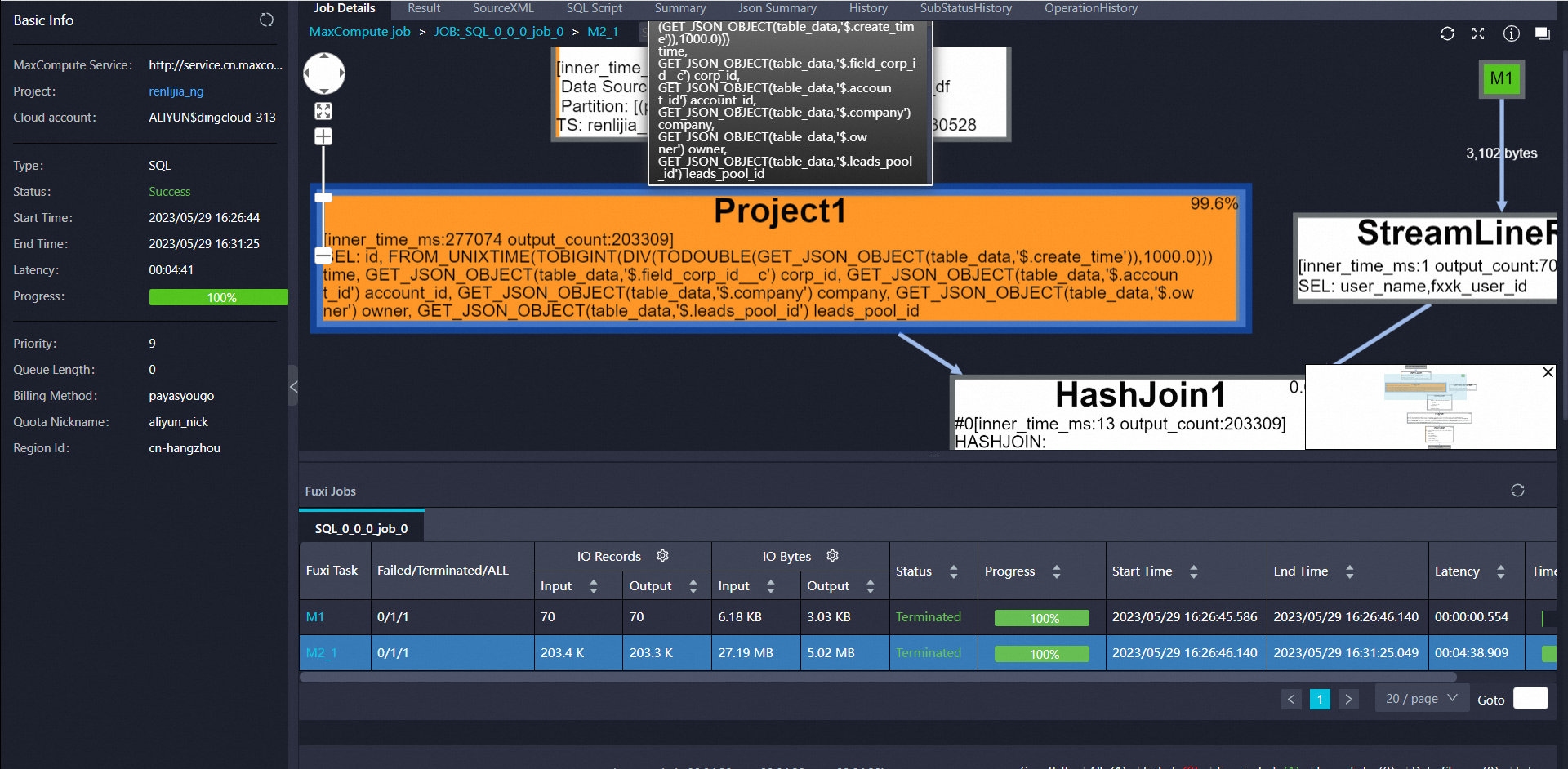 ,看着是这个阶段比较耗时了,只有一个worker跑,可以把这个参数调小一下试试:odps.stage.mapper.split.size,这个也可以调大:odps.stage.mapper.mem 针对问题二的回答:对的,此回答整理自钉群“MaxCompute开发者社区2群”
,看着是这个阶段比较耗时了,只有一个worker跑,可以把这个参数调小一下试试:odps.stage.mapper.split.size,这个也可以调大:odps.stage.mapper.mem 针对问题二的回答:对的,此回答整理自钉群“MaxCompute开发者社区2群”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

