
flink cdc 同步过来的数据出现了乱码情况, 这个应该怎么调整一下?大佬们.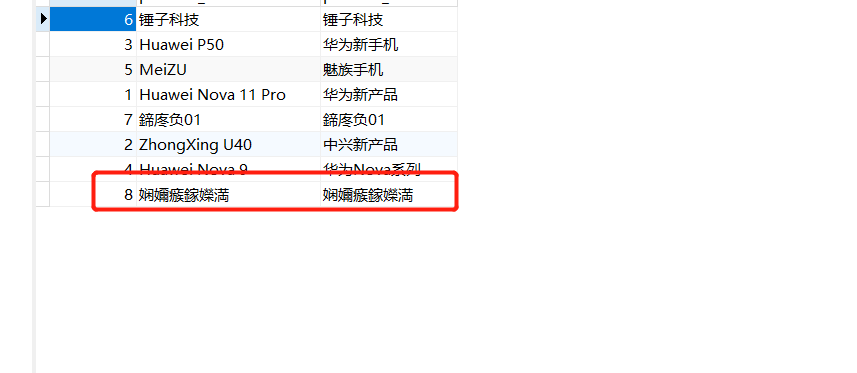
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用 Flink CDC 同步数据时,如果同步过来的数据出现了乱码情况,可能是由于字符集编码不一致或配置不当导致的。以下是可能的原因及解决方法:
SHOW VARIABLES LIKE 'character_set%';
确保 character_set_database 和 character_set_server 使用的是 UTF-8 或其他兼容的字符集。
ALTER DATABASE your_database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
WITH (
'connector' = 'mysql-cdc',
'hostname' = 'your_mysql_host',
'port' = '3306',
'username' = 'your_username',
'password' = 'your_password',
'database-name' = 'your_database',
'table-name' = 'your_table',
'server-time-zone' = 'Asia/Shanghai',
'deserializer.charset' = 'UTF-8' -- 显式指定字符集
);
TEXT 类型。key.serializer 和 value.serializer 使用正确的编码格式。例如:
key.serializer=org.apache.kafka.common.serialization.StringSerializer
value.serializer=org.apache.kafka.common.serialization.StringSerializer
WITH (
'connector' = 'kafka',
'topic' = 'your_topic',
'properties.bootstrap.servers' = 'your_kafka_broker',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true',
'properties.charset' = 'UTF-8' -- 显式指定字符集
);
sink.type-normalize-strategy 参数为 ONLY_BIGINT_OR_TEXT,以确保字符串类型被正确映射。WITH (
'connector' = 'hologres',
'endpoint' = 'your_hologres_endpoint',
'tablename' = 'your_table',
'username' = 'your_username',
'password' = 'your_password',
'sink.type-normalize-strategy' = 'ONLY_BIGINT_OR_TEXT'
);
通过以上步骤,您可以有效解决 Flink CDC 同步数据时出现的乱码问题。
