
DataWorks数据集成的离线同步任务如何配置?
DataWorks数据集成的离线同步任务如何配置?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
数据集成的离线同步任务主要通过设置并发度,来控制任务的占用和同步速度。离线同步任务包括向导模式和脚本模式:通过向导模式配置离线同步任务,详情请参见通过向导模式配置任务。在向导模式编辑页面的通道控制区域,您可以通过配置任务期望最大并发数来控制离线任务的并发度。
 通过脚本模式配置离线同步任务,详情请参见通过脚本模式配置任务。在脚本模式的编辑页面,您可以在JSON结构的配置文本中,通过JSON路径$.setting.speed.concurrent设置离线任务的并发度。
通过脚本模式配置离线同步任务,详情请参见通过脚本模式配置任务。在脚本模式的编辑页面,您可以在JSON结构的配置文本中,通过JSON路径$.setting.speed.concurrent设置离线任务的并发度。 出于性能的考虑和具体数据源读取的限制,同步任务实际运行时的并发度可能小于配置的任务最大期望并发数和任务实际运行时的并发度不一致。查看任务实际运行并发度的操作如下:登录DataWorks控制台。在左侧导航栏,单击工作空间列表。选择工作空间所在地域后,单击相应工作空间后的进入运维中心。在左侧导航栏,单击周期任务运维 > 周期实例。单击相应的数据同步节点,在右侧打开DAG图。右键单击该节点,选择查看运行日志。
出于性能的考虑和具体数据源读取的限制,同步任务实际运行时的并发度可能小于配置的任务最大期望并发数和任务实际运行时的并发度不一致。查看任务实际运行并发度的操作如下:登录DataWorks控制台。在左侧导航栏,单击工作空间列表。选择工作空间所在地域后,单击相应工作空间后的进入运维中心。在左侧导航栏,单击周期任务运维 > 周期实例。单击相应的数据同步节点,在右侧打开DAG图。右键单击该节点,选择查看运行日志。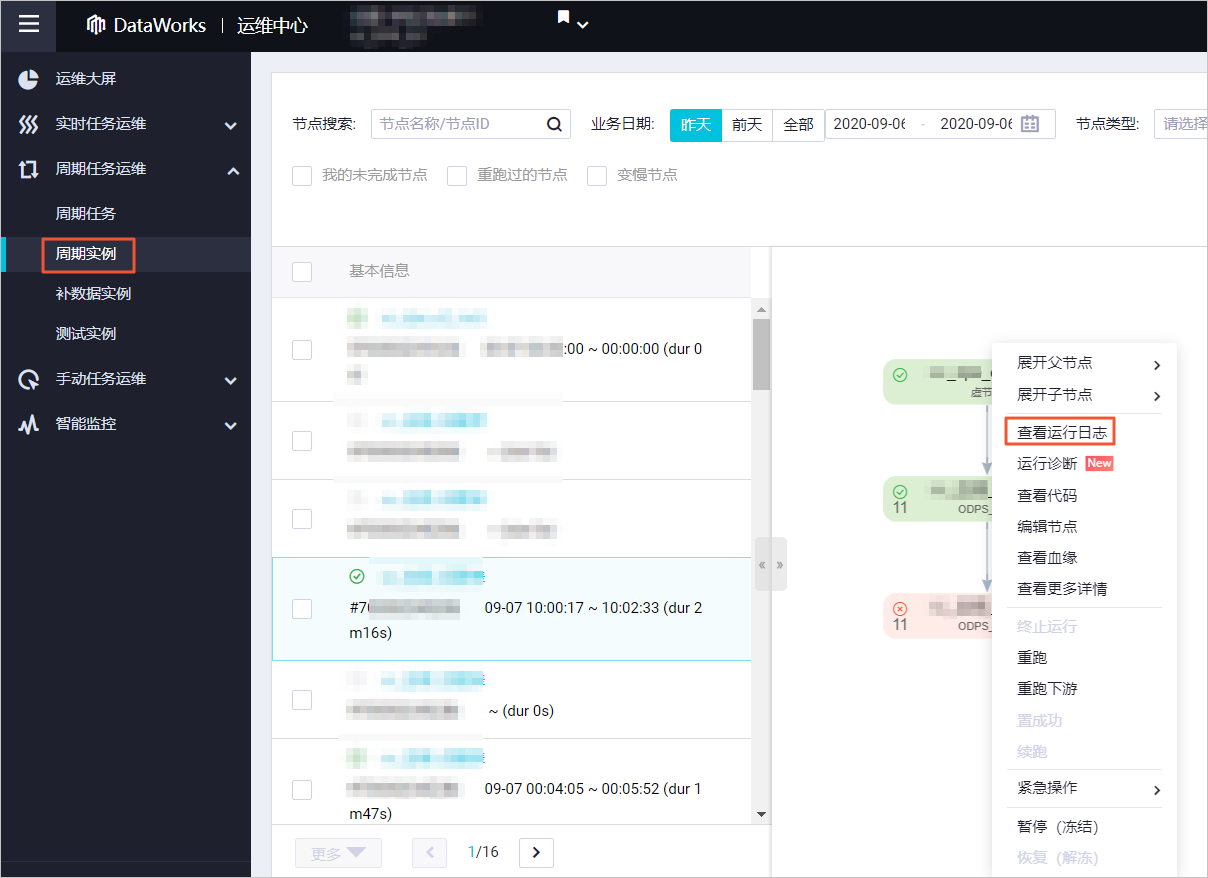 在节点的运行日志页面,单击Detail log url链接。在数据同步任务的详情日志页面,查找形式为JobContainer - Job set Channel-Number to 2 channels.的日志,此处的channels即为任务实际运行的并发度。 https://help.aliyun.com/document_detail/183131.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2023-05-13 09:20:08赞同 展开评论
在节点的运行日志页面,单击Detail log url链接。在数据同步任务的详情日志页面,查找形式为JobContainer - Job set Channel-Number to 2 channels.的日志,此处的channels即为任务实际运行的并发度。 https://help.aliyun.com/document_detail/183131.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2023-05-13 09:20:08赞同 展开评论

DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。