
flink中这种解析异常的话 有没有方法可以异常处理呀 不然一直在mq里面 一直报错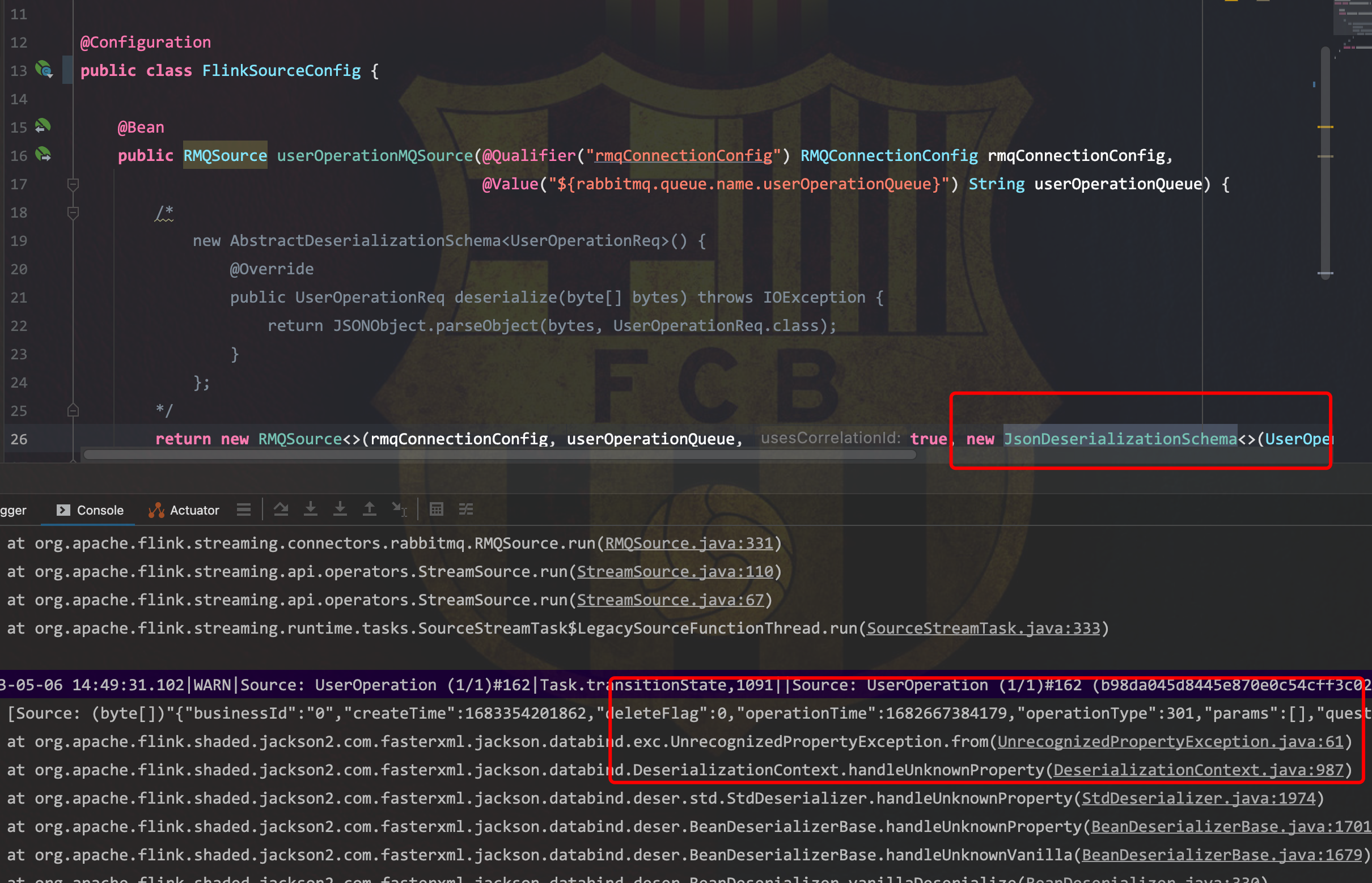
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink中处理解析异常时,可以通过以下方法进行异常处理,以避免消息队列(MQ)中的数据因解析失败而一直报错。以下是具体的解决方案和配置建议:
如果某些数据格式不符合预期,可以选择跳过这些异常数据,而不是让整个作业失败。这可以通过设置相关参数实现。
Debezium JSON 数据源
如果使用的是 Debezium JSON 格式,可以启用 debezium-json.ignore-parse-errors 参数来跳过解析异常的数据:
debezium-json.ignore-parse-errors = true
说明:当设置为 true 时,遇到解析异常的数据会跳过当前行,而不会导致作业失败。
通用字段解析策略
对于其他数据源,可以通过设置字段解析策略为 SKIP 来跳过解析异常的数据:
field-parsing-strategy = SKIP
说明:当解析出的字段数与定义字段数不一致时,跳过该行数据。
为了更好地定位问题,可以开启调试开关,打印解析异常的日志信息。
columnErrorDebug 参数为 true,以记录解析异常的详细日志:
columnErrorDebug = true
说明:开启后,可以在日志中查看具体的解析错误信息,便于后续排查问题。
如果解析异常是由于数据类型不匹配导致的,可以尝试调整数据类型的推导逻辑。
将复杂类型推导为字符串
对于复杂类型(如 ROW、ARRAY、MAP 等),Flink 默认会将其处理为 STRING 类型。如果需要显式指定,可以启用以下参数:
debezium-json.infer-schema.primitive-as-string = true
说明:此配置会将所有字段推导为 STRING 类型,避免因类型不兼容导致的解析异常。
手动声明准确的类型
如果自动推导无法满足需求,建议在 DDL 中手动声明字段的准确类型。例如:
CREATE TABLE source_table (
id BIGINT,
name STRING,
timestamp TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
...
);
说明:手动声明类型可以减少因类型不匹配导致的解析异常。
如果 MQ 中存在大量异常数据,可能会导致作业频繁报错。可以通过限制每次拉取消息的数量来缓解问题。
pullBatchSize 参数,控制每次从 MQ 拉取的消息数量:
pullBatchSize = 32
说明:默认值为 64,可以根据实际情况适当减小该值,降低单次处理的压力。
如果使用的是 Maxwell 或类似工具生成的变更事件,可能会因故障导致重复投递。可以通过以下方式处理:
table.exec.source.cdc-events-duplicate = true
说明:此配置需要在源表上定义主键(PRIMARY KEY),Flink 会基于主键对变更事件进行去重。
如果解析异常与网络或域名解析有关,可以按照以下步骤排查:
确认网络连通性
确保 Flink 和 MQ 之间的网络是连通的,并且能够访问 Kafka Broker 的 Endpoint。
配置自定义 DNS 解析
如果使用了自建 DNS 或需要解析特定域名,可以配置 Flink 的域名解析服务。例如:
env.java.opts: >-
-Dsun.net.spi.nameservice.provider.1=default
-Dsun.net.spi.nameservice.provider.2=dns,sun
-Dsun.net.spi.nameservice.nameservers=192.168.0.1
说明:通过自定义 DNS 配置,解决域名解析问题。
如果问题与 Flink 内部 API 或依赖冲突有关,建议升级到最新版本或调整依赖配置。
避免依赖内部 API
确保只使用 Flink 官方标注为 @Public 或 @PublicEvolving 的方法,避免依赖内部 API 导致的兼容性问题。
解决依赖冲突
如果存在类冲突问题,可以通过 Maven 的 exclusions 配置排除冲突的依赖,或者使用 maven-shade-plugin 进行类重定位。
通过以上方法,您可以有效处理 Flink 中的解析异常问题,避免因异常数据导致作业持续报错。具体操作包括跳过异常数据、打印调试日志、调整数据类型推导逻辑、限制拉取批次大小、启用去重机制以及检查网络和依赖配置等。根据实际场景选择合适的方案,确保作业稳定运行。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

