
有没有大佬知道flink任务运行一段时间后的kafka consumer就不消费了,kafka端显示消息堆积,flink web界面也显示没有新的数据进来,整个程序也没有报错,也没有挂掉,用的是FlinkKafkaConsumer,这是为啥?能指出一下排查方向也行的,日志都看了也没发现啥原因,thread dump则是看不懂,用的process time,没有管水印时间,而且没有用到窗口,就是数据进来后,查维表信息,判断然后输出,嗯嗯这种情况我也知道,我这种很怪。。。刚又自动重启好了,应该是程序中查维表挂了,然后数据流就一直卡在那里不动了。。。但是没有报错了,过了两个小时,估计超了啥timeout时间了,程序就自动restart了 日志显示刚好2小时,不知道怎么设置这个时间。。。2小时也太长了,应该不是。我这个任务不会存在这种情况,应该是访问维表报错后就一直重试了2h,导致程序这里断了,kafka源端由于反压机制也不消费了,但是为啥这个operator中访问第三方数据报错后,整个任务过2h才会失败重启。。。有没有老哥知道呀?配了,而且是5分钟内,但是重启策略应该是flink job层面的错误才会触发重启,算子层面的错误,好像不会立刻体现在job层面,我这个错误就是flatMap算子中报错的,但是整整2个小时,flink任务都没挂掉
日志显示刚好2小时,不知道怎么设置这个时间。。。2小时也太长了,应该不是。我这个任务不会存在这种情况,应该是访问维表报错后就一直重试了2h,导致程序这里断了,kafka源端由于反压机制也不消费了,但是为啥这个operator中访问第三方数据报错后,整个任务过2h才会失败重启。。。有没有老哥知道呀?配了,而且是5分钟内,但是重启策略应该是flink job层面的错误才会触发重启,算子层面的错误,好像不会立刻体现在job层面,我这个错误就是flatMap算子中报错的,但是整整2个小时,flink任务都没挂掉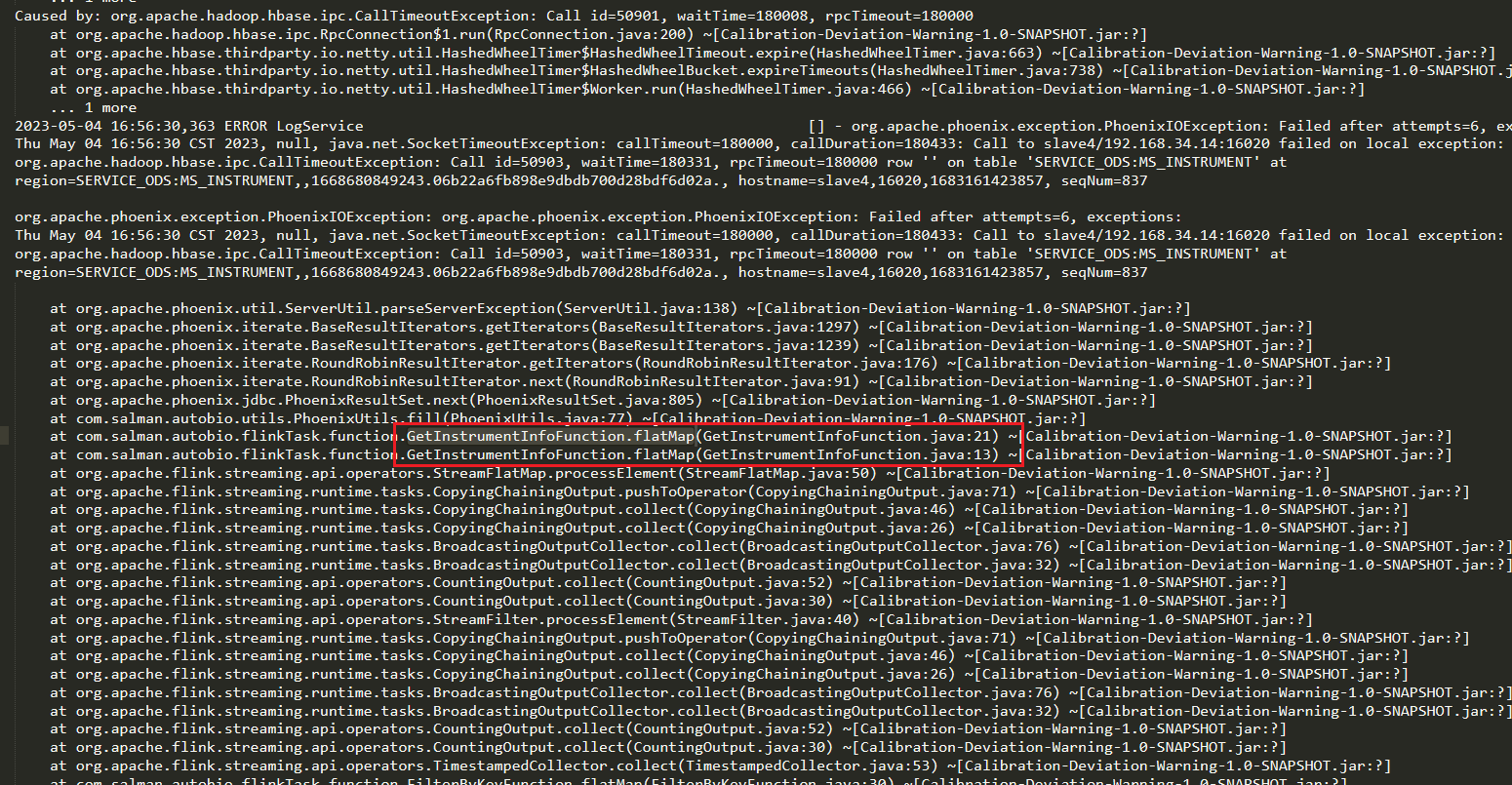
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
有可能是消费速度低于生产速度,导致消息堆积,可以提高并行度试一下,有没有配置重启策略,如果 Flink Job 中没有单独设置重启重启策略的话,则会使用集群启动时加载的默认重启策略,如果 Flink Job 中单独设置了重启策略则会覆盖默认的集群重启策略。默认重启策略可以在 Flink 的配置文件 flink-conf.yaml 中设置,由 restart-strategy 参数控制,有 fixed-delay(固定延时重启策略)、failure-rate(故障率重启策略)、none(不重启策略)三种可以选择。我感觉应该跟这里有关,直到反压机制导致缓冲池内存用完导致任务挂掉,才停止。有没有大佬可以解惑一下。,此回答整理自钉群“【③群】Apache Flink China社区”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

