
有没有大佬 遇到过, Flink CDC 中拉oracle 从binlog最新点位拉去的 直接报错推出的?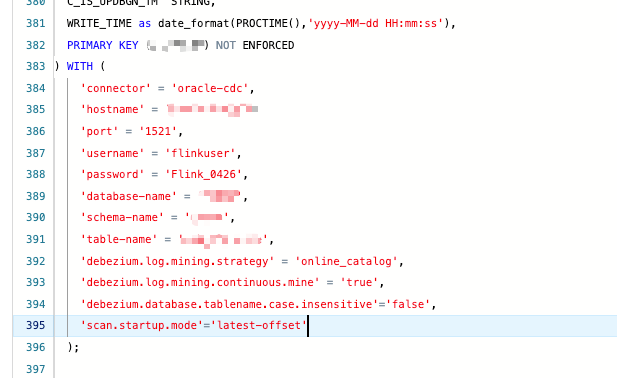 日志都没找到 yarn 上对应的appid 被清除了
日志都没找到 yarn 上对应的appid 被清除了
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题,Flink CDC 在拉取 Oracle 数据时从 Binlog 最新点位开始消费直接报错退出,并且 Yarn 上对应的 AppID 被清除。以下是可能的原因分析及解决方案:
Mixed 或 Statement 时,CDC 工具无法正确解析数据变更事件。expire_logs_days 参数,Oracle 的日志保留策略也需要合理配置。scan.startup.mode 参数),可能会导致作业尝试从一个无效的点位开始消费,进而报错退出。SELECT log_mode FROM v$database;
如果返回值不是 ARCHIVELOG,需要启用归档日志模式:
SHUTDOWN IMMEDIATE;
STARTUP MOUNT;
ALTER DATABASE ARCHIVELOG;
ALTER DATABASE OPEN;
'scan.startup.mode' = 'latest-offset'
或者,如果您希望从某个特定时间点开始消费:
'scan.startup.mode' = 'timestamp',
'scan.startup.timestamp-millis' = '1698765432000'
taskmanager.memory.process.size: 4096m
jobmanager.memory.process.size: 2048m
parallelism.default: 4
task.cancellation.timeout: 0
execution.checkpointing.timeout: 10min
log4j.logger.org.apache.kafka.clients.consumer=trace
log4j.logger.org.apache.flink.connector.jdbc=debug
server-id 全局唯一,避免多个作业或工具使用相同的 server-id 导致冲突。通过以上步骤,您可以逐步排查并解决 Flink CDC 拉取 Oracle 数据时从最新点位消费报错的问题。如果问题仍未解决,请提供更详细的日志信息以便进一步分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
