
请教下大佬为什么不能用flinksql 开发数据同步呢?另外pg的整库同步我在网上找了但是没找到,大佬受累发我一个链接好嘛,大佬,我刚看了flinkcdc官网,您的意思是DataStream Source方式采集可以采集多表用一个slot,我在tableList这里添加需要采集的表,实现思路是对的吧?另外整库同步大佬发我的链接是Dinky,我这边目前打算用streamPark,我去找下是否有类似功能,大佬只言片语让我瞬间感觉柳暗花明了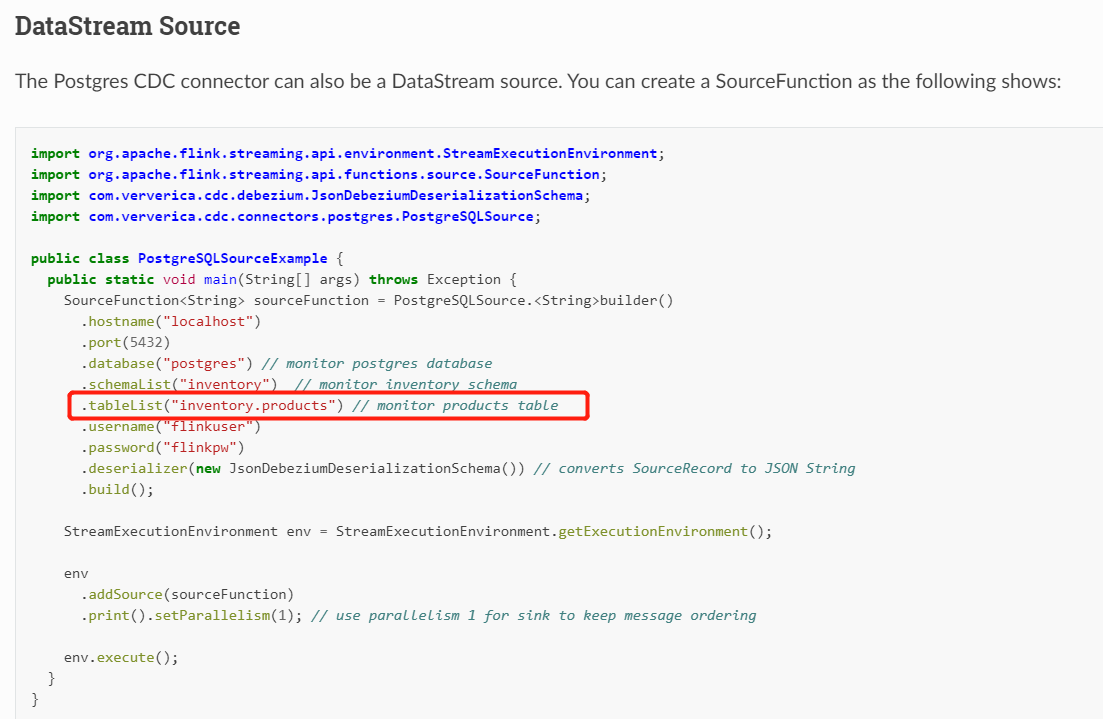 我理解是flinksql时按表过滤,而且是一张表,可以实现多张表过滤吗?
我理解是flinksql时按表过滤,而且是一张表,可以实现多张表过滤吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
采集阶段别用lfink sql,因为一张表就需要用一个slot。你们那边dba要求那么严格,肯定过不去。 采集进来以后,可以使用flink sql计算,转换。http://www.dlink.top/docs/0.7/data_integration_guide/cdcsource_statements有这个能力就自己开发一个整库同步,我希望也能分享我一份 一个slot本来就是会采集到整个库的数据,只是dbz做了过滤,flinksql 要创建多个source吧,可以source用api,sink用sql志明,中间分流,按表分流,最好纯api,flink sql有时改了state会对不上,此回答整理自钉群“Flink CDC 社区”
