
SELECT * FROM t WHERE gmt_create BETWEEN '2023-04-11 00:00:00' and '2023-04-21 00:00:00'; 在数据过滤怎么写
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中进行数据过滤,可以通过在SQL脚本中使用WHERE语句进行筛选。以您提供的SQL语句为例,可以在其中添加WHERE语句来进行数据过滤,如下所示:
plaintext Copy code SELECT * FROM t WHERE gmt_create BETWEEN '2023-04-11 00:00:00' AND '2023-04-21 00:00:00';
其中,WHERE语句后面的条件表达式是用来筛选数据的关键。在上述示例中,gmt_create BETWEEN '2023-04-11 00:00:00' AND '2023-04-21 00:00:00'表示筛选出gmt_create字段在指定时间范围内的数据。其中,BETWEEN关键字表示在两个值之间,可以包括这两个值,AND关键字用于连接两个值。 您可以根据实际需求,修改WHERE语句后面的条件表达式,来实现不同的数据过滤效果。例如,可以根据字段值的大小、数据类型、字符串匹配等条件进行筛选。
在数据过滤中,你可以使用 WHERE 子句来过滤数据。如果你想要查询 t 表中 gmt_create 字段在 ‘2023-04-11 00:00:00’ 和 ‘2023-04-21 00:00:00’ 之间的数据,可以像下面这样写:
SELECT * FROM t WHERE gmt_create >= '2023-04-11 00:00:00' AND gmt_create < '2023-04-21 00:00:00'; 这里使用了 >= 和 < 运算符来过滤 gmt_create 字段。注意,使用 < 运算符而不是 <= 运算符可以避免在日期范围的结束时间点上漏掉数据。
数据过滤:
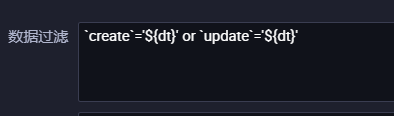
参数格式为'dt=20230406'或者'2023-04-06'
比如十分钟调度的mysql数据增量同步到maxcompute最新分区中。
数据过滤参数配置为:
date_format(addtime,'%Y-%m-%d %H:%i:%s') <= '${key1} ${key3}'
含义是将最近十分钟的数据过滤出来,同步到maxcompute表的最新分区中(每十分钟创建一个分区)。
其中参数为 key1=$[yyyy-mm-dd] key2=$[hh24:mi:ss-10/24/60] key3=$[hh24:mi:ss] key1:当前的日期,格式是yyyy-mm-dd key2:十分钟前的时间,格式是hh24:mi:ss key3:当前时间,格式是hh24:mi:ss
以上仅供参考。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。



