
请问大家,我写一个插入语句insert into hTable select * from tb_300w_source; 需要配置什么参数,在webUI上可以看到写入的数据量,而不是空空的0?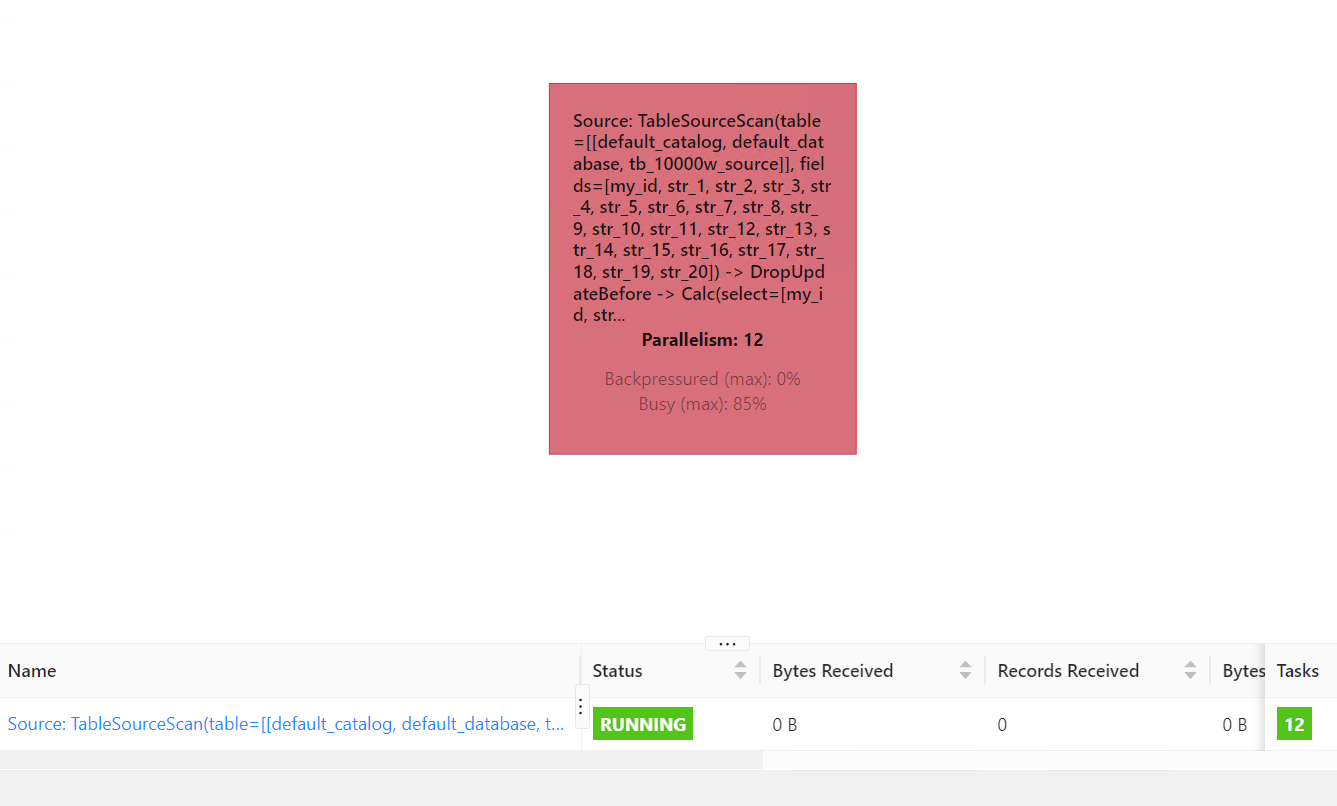
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink中,可以通过配置metrics.reporter参数,来选择不同的指标报告器,通过指标报告器可以输出Flink任务的状态、性能相关指标等等。
其中最常用的指标报告器为flink-metrics-prometheus,它可以将Flink任务的指标报告到Prometheus系统中,使用Grafana等工具来可视化展示指标。
使用步骤如下:
metrics.reporters: prom
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter
metrics.reporter.prom.host: ${prometheus_server_ip}
metrics.reporter.prom.port: ${prometheus_server_port}
在Prometheus服务中,添加Flink任务的metrics报告地址,即flink-conf.yaml中配置的prometheus server地址和端口号。
在Grafana中,添加并配置一个Flink Dashboard,选择正确的数据源(即Prometheus),并配置相应的PromQL查询语句,比如查询任务从kafka中消费的数据量与写入的数据量。可以参考下列PromQL查询语句:
Kafka Topic 消费量
sum by (topic) (flink_taskmanager_job_task_operator_taskmanager_numRecordsInPerSecond{})
sum(flask_sink_task_numBytesOutPerSecond{})
这样,在Grafana中就可以可视化展示Flink任务的相应指标了,方便我们进行性能调优。
设置set pipeline.operator-chaining=false;,然后再执行sql,此回答整理自钉群“【③群】Apache Flink China社区”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



