
作者:袁斌、鄢志杰 阿里达摩院语音实验室
语音AI是最早从实验室走向应用的AI技术,其发展史就是不断创新、解锁应用的历史,从1995年 Dragon Dictate的桌面孤立词语音识别,到2011年苹果的手机语音助手SIRI,再到当下百花齐放的各种智能语音应用。
由于技术的快速进步,以及各大云计算厂商以API形式提供的语音AI能力,目前开发者已能便捷使用语音AI去搭建应用。但API也存在局限性,不少开发者希望获得更多、更底层的把控力,希望对API背后AI模型有更深入的了解;不只是开发应用,还可以开发模型;不只是调用API接口,还可以通过对模型的训练或微调(fine-tuning),以提升实际应用效果。
为了让所有满怀创意的开发者实现更高水平的创新,在最近推出的魔搭社区ModelScope上,阿里达摩院首批开源开放了40多个语音AI模型,公有云上广受欢迎的付费模型这次也免费开放。模型背后,我们提供了训练或微调脚本工具链,含盖语音AI各个主要方向。
下面,就让我们以语音合成、语音识别、语音信号处理为例,来展示如何玩转魔搭社区的语音AI模型。
语音合成是将文字作为输入,让AI能够将文字转换为语音的原子能力。例如,我们希望AI朗读如下的一段文字:
“最当初,他只是觉得赛伦看莫颖儿的眼光温柔得超过一般父女或是师徒的感情,在观察了一段时间过后,他才逐渐确定赛伦似乎很在乎这个少女。”
在魔搭社区,可以有两种方式来进行语音合成模型的体验:
第一种方式是使用模型详情页的“在线体验”功能,以最直观的方式对每个语音合成模型进行体验。这对模型的初步体验和把玩品鉴非常高效。
接下来以“SambertHifigan语音合成-中文-多人预训练-16k”模型为例,介绍如何进行在线体验。
模型链接:ModelScope 魔搭社区
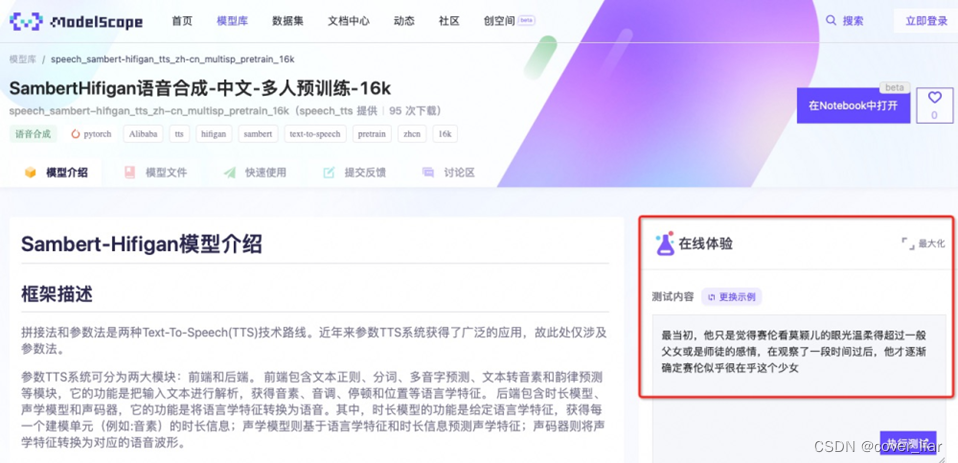
我们输入文字,点击“执行测试”,等待片刻,便可试听语音合成的效果。
第二种方式是使用编程,通过简单的几行代码,就可以实现自己的语音合成功能,并集成嵌入到具体的应用中去。这种方式适合选定喜欢的发音人后、进行深度的应用开发。
魔搭社区提供了**免费的CPU算力(不限额)和GPU算力(NVIDIA-V100-16G 限额100小时),**供开发者进行使用,下面我们使用Notebook开发环境来简单演示如何实现使用代码进行语音合成。
让我们选择CPU服务,稍等几分钟服务启动,我们点击“查看NoteBook”,进入开发环境,选择启动一个python脚本。
这些语音AI模型都配备了代码示例,我们可以在模型详情页的代码示例中找到:
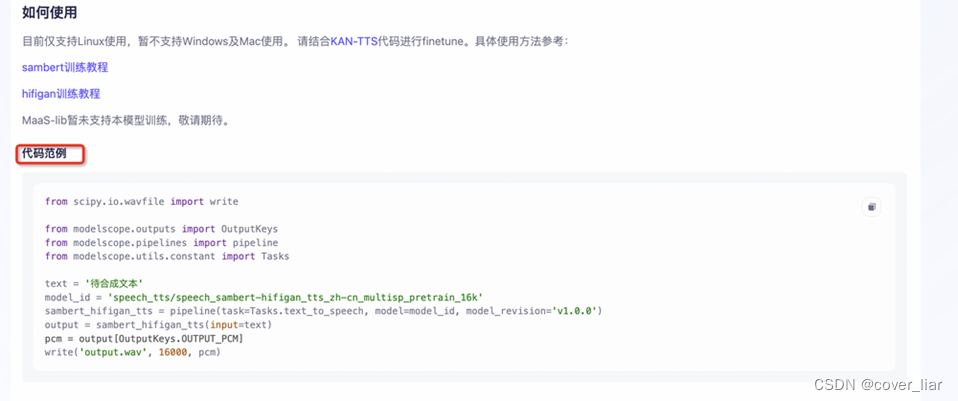
将该代码进行复制并粘贴至notebook的python脚本当中,我们可以将代码中**‘待合成文本’字符串**替换成想要的合成本文,并执行程序,便可以下载生成的音频文件进行试听。

这项语音合成技术背后是达摩院的显式韵律声学模型SAMBERT以及Hifi-GAN声码器的结合。
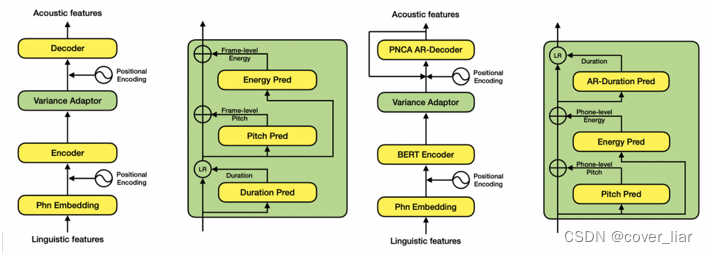
在语音合成领域,目前以FastSpeech2类似的Non-Parallel模型为主流,它针对基频(pitch)、能量(energy)和时长(duration)三种韵律表征分别建模。但是,该类模型普遍存在一些效果和性能上的问题:独立建模时长、基频、能量,忽视了其内在联系;完全非自回归的网络结构,无法满足工业级实时合成需求;帧级别基频和能量预测不稳定...
因此达摩院设计了SAMBERT,一种基于Non-Parallel结构的改良版TTS模型,它具有以下优点:
建立时长与基频、能量的依赖关系,并使用自回归结构的时长预测模块,提升预测韵律的自然度和多样性;
Decoder使用PNCA自回归结构,降低带宽要求,支持CPU实时合成;
音素级别建模基频、能量,提高容错率;
以预训练BERT语言模型为编码器,在小规模数据上效果更好。
在魔搭社区上,达摩院语音实验室开放了核心的语音识别模型“Paraformer语音识别-中文-通用-16k-离线”,这是即将大规模商业部署的下一代模型,其训练数据规模达到5万小时以上,通过对非自回归语音识别模型技术的改进,不仅达到当前类Transformer自回归模型的语音识别准确率,而且在推理效率上有10倍的加速比提升。
模型链接:ModelScope 魔搭社区
在魔搭社区中,语音识别模型与语音合成一样,提供Demo和Notebook两种方式进行效果体验,操作方法请参见上文,不再赘述。
除了开放最先进的Paraformer模型之外,语音实验室还免费开放了当红的语音识别模型UniASR,它在公有云上提供商业化的服务,广受欢迎。UniASR模型含盖了中、英、日、俄等语种,支持8k/16k采样率,可以满足开发者不同场景的开发需求。
模型链接:ModelScope 魔搭社区
信号处理也是语音处理的一个重要的技术组成分支,达摩院开源了基于深度学习的回声残余抑制算法。
模型名:DFSMN回声消除-单麦单参考-16k
模型链接:ModelScope 魔搭社区从用户体验角度,一个理想的回声消除算法要达到以下效果:远端单讲(far end single talk)时零回声泄露;近端单讲(near end single talk)时语音无损;双端同时讲话时可以互相听清,也即双讲(double talk)通透。目前在开源的信号处理算法当中,双讲时的效果都比较差强人意。这是因为目前的开源信号处理算法无法有效区分录音信号中的回声信号和近端语音信号,而且真实通话中双讲出现的时间一般较短、时间占比也很低,所以从策略上为了确保零回声泄露,只好牺牲双讲时的效果。
达摩院这个模型能够进一步提升双讲通话效果,满足用户对语音通信时的音质要求,已在阿里内部音视频项目上完成了工业化部署。大家如果现在使用钉钉视频会议,会发现了多一个较为方便的对讲功能。这次模型开源,希望能对从事webRTC的研究者与开发者有所帮助,欢迎大家基于这个模型进行应用开发,在NoteBook中只需要5行代码就可以得到回声消除结果。
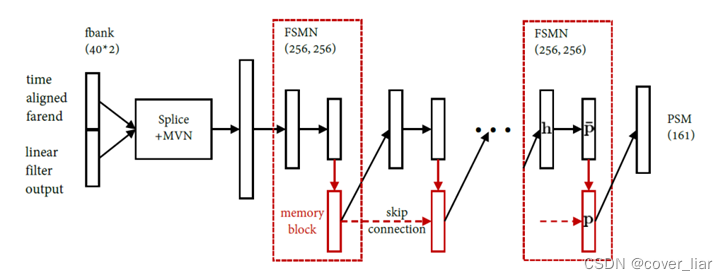
该模型的技术创新点在于借鉴了智能降噪的解决思路:数据模拟->模型优化->模型推理。
具体而言,我们结合回声残余抑制的任务特点,在输入特征上,拼接了线性滤波器的输出信号和时延对齐的回采信号,并提取FBank进行均值方差归一化。在输出目标上,选择了相位感知的掩蔽值(Phase-Sensitive Mask, PSM)。在模型推理阶段,对PSM与线性输出的信号频谱逐点相乘后再进行IFFT (inverse Fast Fourier Transform)获得近端语音。
在过去的语音 AI 探索当中,达摩院完整实现了从研到发,从模型创新到提供API的全链条。但是随着近年来语音AI的飞速发展,开发者角色变得多元化、各方面需求也变得越来越丰富,传统的“包打天下”的模式已不再合适。面向未来,我们希望通过魔搭这样的开放、开源的社区来推进语音AI的研究和应用,促进语音AI生态的活跃和繁荣。

