
ModelScope通过GPT-3中文2.7B模型在诗词生成数据集上二次开发训练
ModelScope通过GPT-3中文2.7B模型在诗词生成数据集上二次开发训练 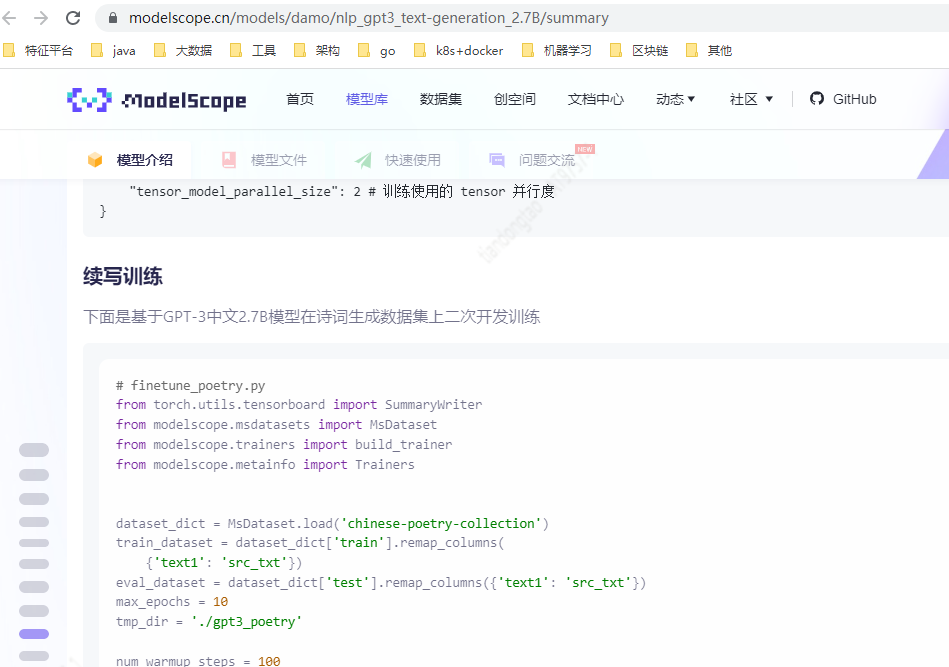 ,训练出的模型预测时报这个
,训练出的模型预测时报这个 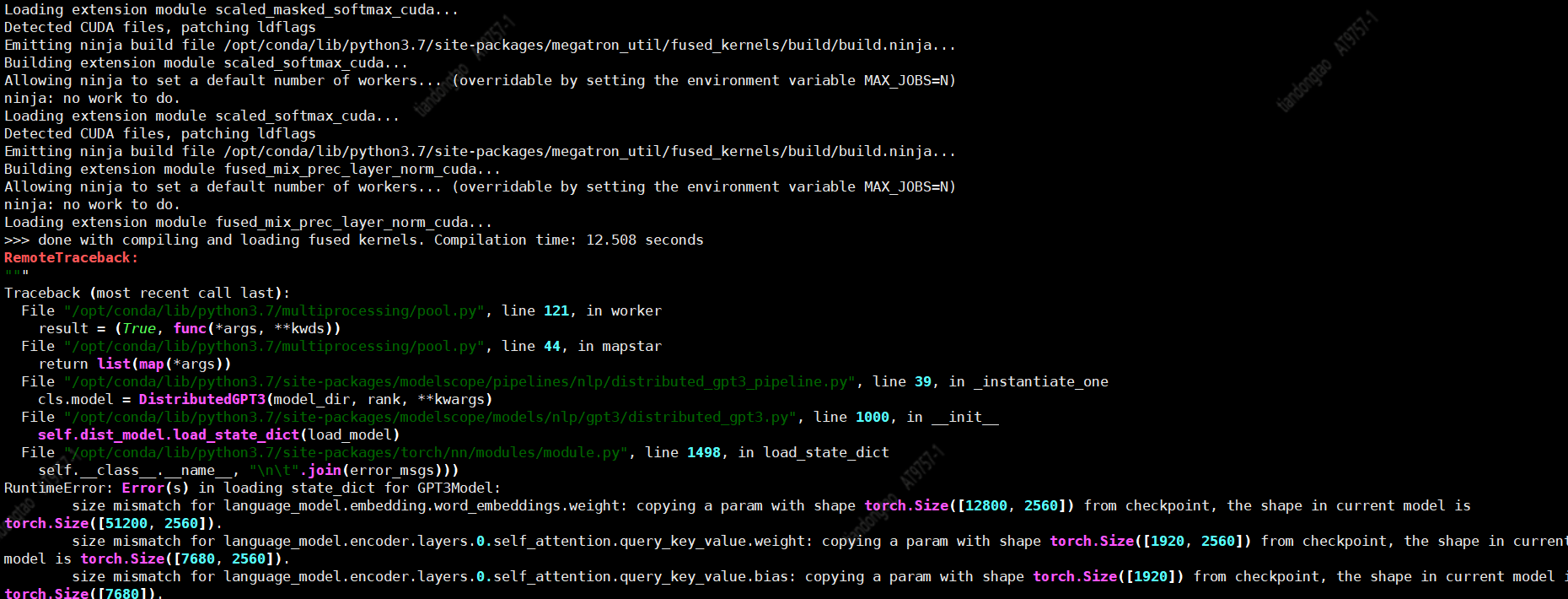 ,请问有解决方式吗,训练过程没报错,模型文件夹:
,请问有解决方式吗,训练过程没报错,模型文件夹: 
展开
收起
2
条回答
写回答
-
数据集准备:为了在GPT-3中文模型上进行二次开发和训练,首先需要准备一个高质量的诗词数据集。数据集应该包含大量标准化的诗词文本,且格式一致,方便模型学习。
环境设置:确保您有权访问ModelScope平台,并且已经设置了必要的开发环境,包括安装了所需的软件包和库。
模型加载:在ModelScope平台上加载GPT-3中文2.7B模型。通常,这可以通过ModelScope提供的API或者SDK来完成。
二次训练:在现有GPT-3中文模型的基础上,使用您准备的诗词数据集来进行二次训练。这通常涉及到设置训练参数,如学习率、批次大小、训练轮数等。
训练过程监控:在训练过程中,监控模型的性能,确保模型在学习过程中没有过拟合或者欠拟合。可以通过设置验证集来评估模型在训练过程中的表现。
优化和调整:根据模型在训练过程中的表现,可能需要对模型的架构或训练参数进行调整,以达到更好的效果。
测试和评估:用另一组数据进行测试,评估模型的诗词生成能力。可以使用诗词质量、创新性、韵律等标准来评价生成的诗词。
模型部署:一旦模型训练完成并通过测试,就可以部署模型,使其可以响应用户的请求进行诗词生成。
2024-02-23 16:31:02赞同 1 展开评论 -

相关问答
收录在圈子:

+ 订阅
相关文章
热门讨论
热门文章
展开全部
展开全部
还有其他疑问?
咨询AI助理