
取消 flink 作业后 ,发现 flink 所在的 taskmanage 挂掉了。上面的 flin
取消 flink 作业后 ,发现 flink 所在的 taskmanage 挂掉了。上面的 flink job 没有自动迁移到别的机器,一直重启中,这是什么原因呢 taskmanage 挂掉, job 应该会自动迁移到别的机器吧?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
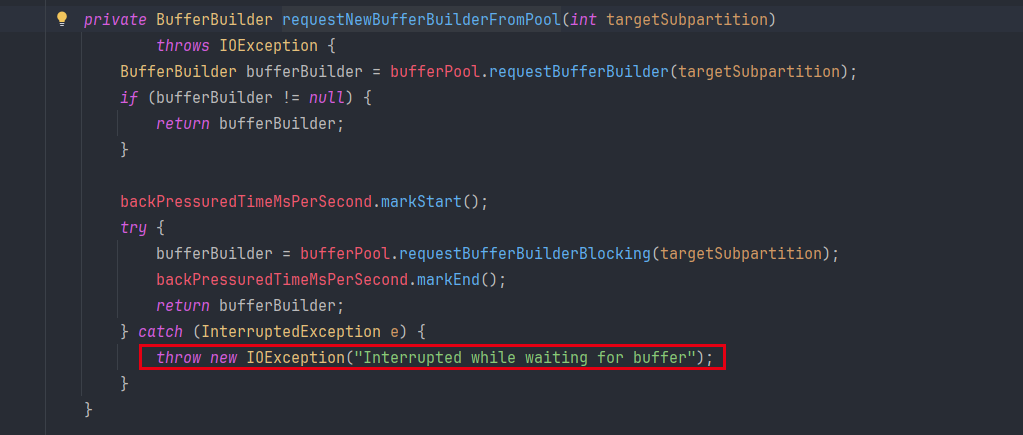
Flink是通过中止线程来取消算子执行的,如果在请求下游算子资源的时候,阻塞线程被打断,而在底层代码()catch了InterruptedException转为IoException,并且没有复位中断状态,而自定义代码又把IoException异常catch住了,下一个event仍能继续执行,就会导致算子阻塞在请求下一资源的地方。算子未能正常取消,超时时间到了之后,CancelerWatchDog就会中止进程
 2025-04-10 13:31:44赞同 展开评论
2025-04-10 13:31:44赞同 展开评论 -
资深技术专家。主攻技术开发,擅长分享、写文、测评。
看到问题的第一反应是首先看TaskManager进程为什么会挂掉,这个问题比较严重,因为涉及到集群层面而不单单是任务了,askCancelerWatchDog是用来监听Cancel任务是否成功的线程,如果超过timeoutMillis执行线程还处理alive状态,则向TaskManager进程抛出FatalError,而这个timeoutMillis是通过task.cancellation.timeout参数来指定,默认是180s,如果指定为0则不开启这个功能。
2022-11-24 20:11:07赞同 展开评论 -
-
天下风云出我辈,一入江湖岁月催,皇图霸业谈笑中,不胜人生一场醉。
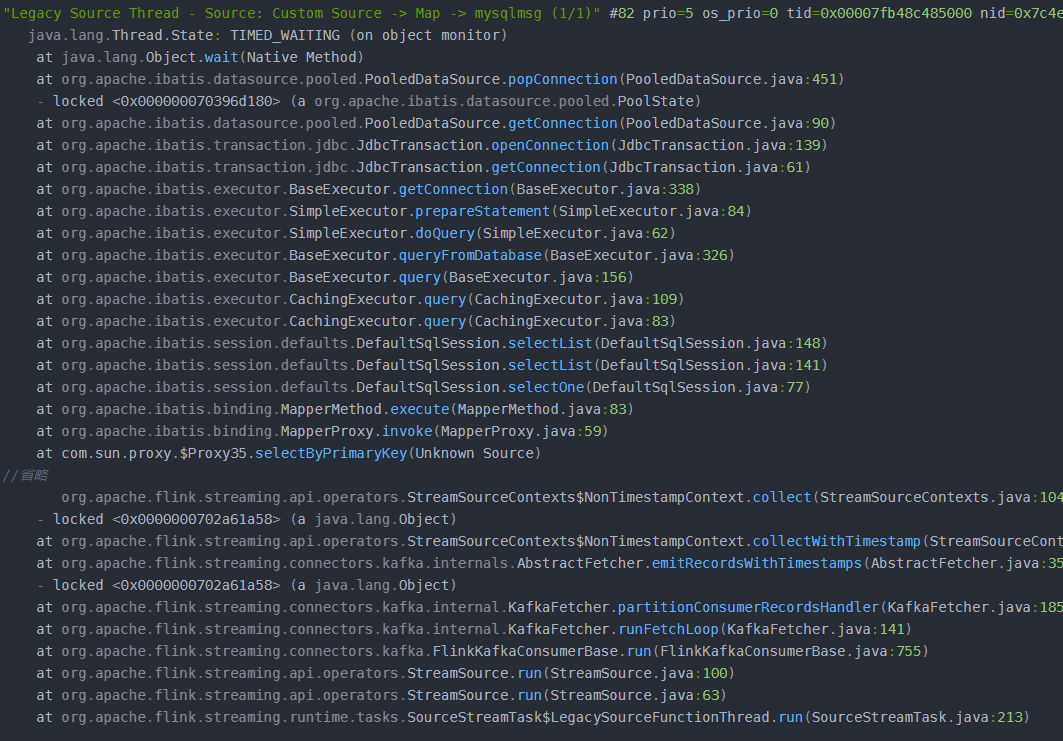
看到问题的第一反应是首先看TaskManager进程为什么会挂掉,这个问题比较严重,因为涉及到集群层面而不单单是任务了。查看Taskmanager日志 原因1 由于任务在180s内没被正常Cancel导致。为了防止TaskManager进程挂掉,我们添加参数task.cancellation.timeout: 0 原因2 大量checkpoint处于pendding状态,最终还会超时。因为未设置execution.checkpointing.tolerable-failed-checkpoints,因此一旦发生超时,任务将会发生重启 解决方案 增加最大活跃线程数poolMaximumActiveConnections; 采用长连接,在open时初始化连接,close方法销毁连接; 不用另外开启连接,直接采用flink-jdbc-connector来发送数据,因为数据源涉及上百张表,需要有分流的操作。
 2022-11-23 11:15:23赞同 展开评论
2022-11-23 11:15:23赞同 展开评论 -
十年摸盘键,代码未曾试。 今日码示君,谁有上云事。
可能是程序中存在内存泄露,猜测可能是程序中的LIST,MAP等等使用存错误导致程序使用内存一直在增长最终达到上限被yarn给kill掉了(concurrentHashMap,不停的增长,导致内存泄露),也有可能是堆外内存的bug.
可以查看一下日志,如果TaskManager使用的内存逐渐增到,最终超过了申请的最大物理内存,就会发生内存泄露的问题。
为了稳定,建议放弃了使用RockDbStateBackEnd改用FsStatebackEnd程序,运行会良好一些。
2022-11-22 15:07:42赞同 展开评论


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
