
要怎样一步步达成我们的终极目的“ Auto Code”呢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
这个过程通俗来讲就是 通用组件 + 配置信息 的模式,配置信息即 ProCode的部分,该部分即为需要 AI 自动产出的内容。因此想要完成自动出码,就需要对ProCode 的部分进行样本制造和监督学习。
我们来总结一下我们的三步走计划:
需求的结构化收集 (为了降低NLP 的分析难度)。
创造结构化需求到标准逻辑表达的样本(为机器学习ProCode 部分提供充足样本)。
通过机器学习对样本进行学习,以达到AutoCode 的目标(长期目标)。
即我们需建立要两个平台,我们称之为P2C 的 2.0 代 和 1.0 代。P2C 1.0 负责打标需求数据,并为 2.0 的智能出码提供庞大准确的数据。而 P2C 2.0 则主要进行需求的结构化收集并与1.0 的样本进行关联学习,训练出码模型,最终达到创作和自动完成需求的目的。
两个平台所代表的关键词分别是:
●P2C1.0:精确收集,精确产出
●P2C2.0:开放收集,创新产出
那么精确收集样本就成为我们 P2C 1.0 的主要工作方向。
打标样本一定要从实践出发,并能在该阶段帮助需求真实的进行产出,即我们提供的打标平台能真实的完成业务需求,因此我们决定开发一个可视化编排的平台,通过该平台来收集样本数据,并且可以顺手把需求也消化掉。
那么问题来了,这么多的样本打标的工作到底由谁来完成呢?
我们通过调研发现运营的角色在可视化编排方向上,是有着非常高契合度的。为什么呢?其一,运营都具备模块搭建的能力。其二,很多运营的需求都不一定有机会能够落地,主要原因是开发资源不足导致的,这也是多年来存在的业务与技术矛盾,前端这十年来一直朝着工程化、规范化、模块化的方向发展,本意是为了更有效的重用业务能力以达到解放生产力,而产品却一直在朝着丰富化、精细化的方式来运作,各个业务方不再是单单为了满足功能诉求而更讲求的是用户心智。最终致使现在对一个个性化需求的提出往往是用一个标准化方案来落地的。当业务方为资源不足妥协时,其业务整体感官也会越来越平庸化、趋同化,最终导致产品对用户的心智弱化。
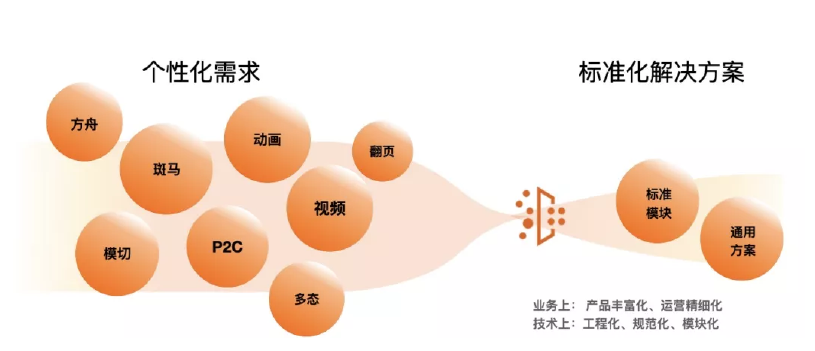
因此对于运营的诉求是希望能将创新和业务思考带入到自己的产品中,而不是简单的拆解为一个个的标准实现。如何拉大与竞争对手的运营差异、交互差异、创新差异、视觉差异才是对于运营真正的核心价值。
在AI 的介绍篇中我们讲了对于复杂的逻辑关系我们依然可以采用抽象的组件化来实现,而这部分实现对比传统搭建体系的组件颗粒度更细,传统搭建一般是对模块的自定义配置,而在我们的编排体系里最小的组件应该是原子化的不可再被拆解的,比如一个Image 组件,而对组件的配置可以是一段编排好的逻辑实现,因此它能有着同代码一样的绝对灵活性。
以上内容摘自《大促背后的前端核心业务实践》电子书,点击https://developer.aliyun.com/topic/download?id=728可下载完整版。


