

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
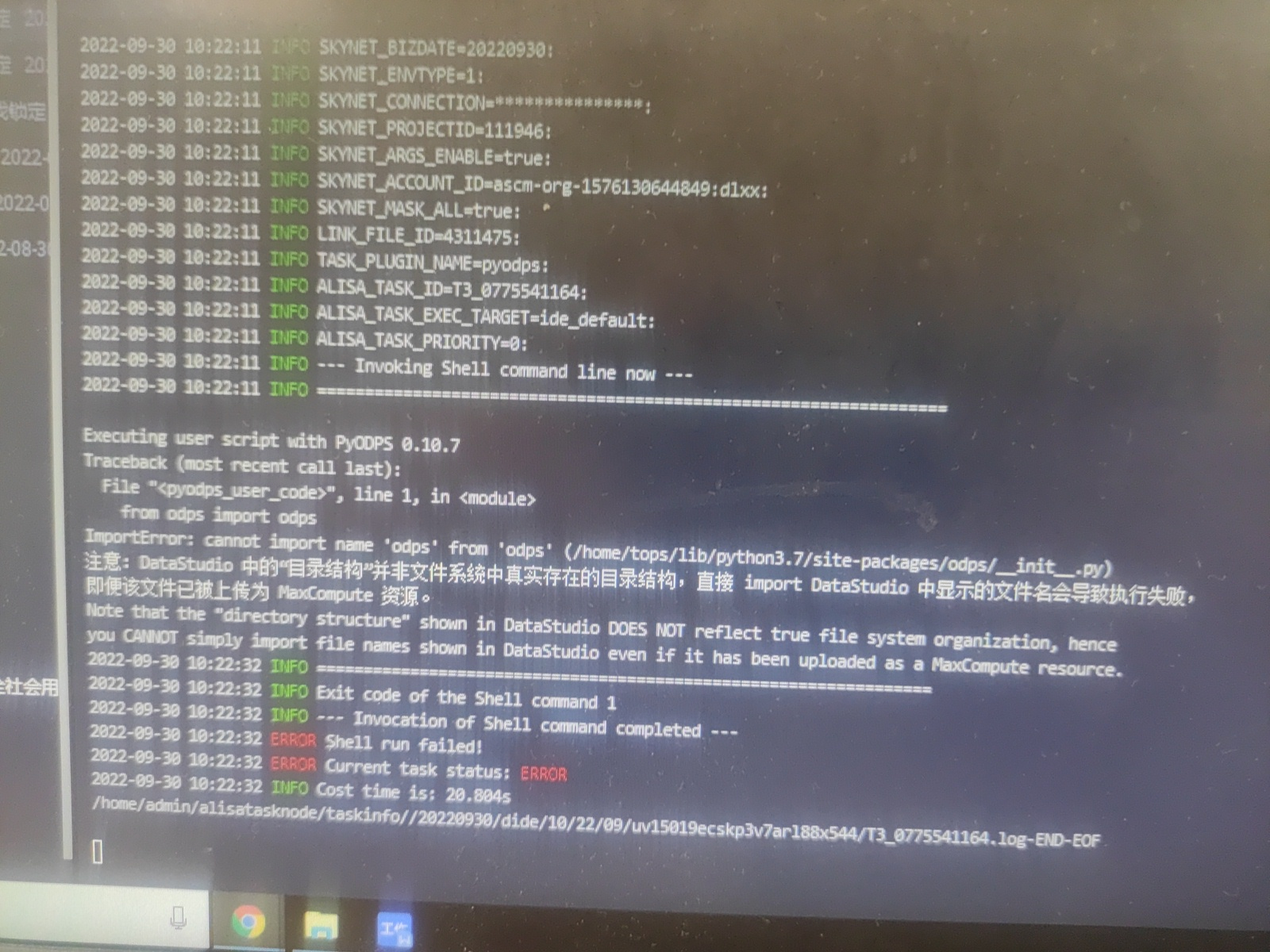
楼主看看这个: 使用限制 PyODPS节点获取本地处理的数据不能超过50 MB,节点运行时占用内存不能超过1 GB,否则节点任务会被系统中止。请避免在PyODPS任务中写额外的Python数据处理代码。 在DataWorks上编写代码并进行调试效率较低,为提升运行效率,建议本地安装IDE进行代码开发。 在DataWorks上使用PyODPS时,为了防止对DataWorks的Gate Way造成压力,对内存和CPU都有限制,该限制由DataWorks统一管理。如果您发现有Got killed报错,即表明内存使用超限,进程被中止。因此,请尽量避免本地的数据操作。通过PyODPS发起的SQL和DataFrame任务(除to_pandas外)不受此限制。 由于缺少matplotlib等包,如下功能可能受限: DataFrame的plot函数。 DataFrame自定义函数需要提交到MaxCompute执行。由于Python沙箱限制,第三方库只支持所有的纯粹Python库以及Numpy,因此不能直接使用Pandas。 DataWorks中执行的非自定义函数代码可以使用平台预装的Numpy和Pandas。不支持其他带有二进制代码的三方包。 由于兼容性原因,在DataWorks中,options.tunnel.use_instance_tunnel默认设置为False。如果需要全局开启instance tunnel,需要手动将该值设置为True。 由于实现的原因,Python的atexit包不被支持,请使用try-finally结构实现相关功能。 ODPS入口 DataWorks的PyODPS节点中,将会包含一个全局变量odps或者o,即为ODPS入口。您不需要手动定义ODPS入口。 print(o.exist_table('pyodps_iris'))
试一下这样操作呢 https://help.aliyun.com/document_detail/90444.html(此答案整理自MaxCompute开发者社区2群)
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。



