
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink 支持在流处理和批处理中使用 SQL 查询 Hive 表。通过 Flink 的 HiveCatalog,可以将 Hive 中的表注册为 Flink 中的表,然后使用 SQL 查询这些表。
下面是使用 Flink 查询 Hive 表的步骤:
在 Maven 或 Gradle 中添加 Flink 的 Hive 依赖,例如:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
在上面的示例中,我们添加了 Flink 的 Blink Table Planner 和 Hive Connector 依赖。
在 Flink 应用程序中,可以创建一个 HiveCatalog,用于连接到 Hive 元数据存储,并将 Hive 中的表注册为 Flink 中的表。例如:
String catalogName = "myhive";
String defaultDatabase = "default";
String hiveConfDir = "/path/to/hive/conf/dir";
String hiveVersion = "2.3.4";
HiveCatalog hiveCatalog = new HiveCatalog(catalogName, defaultDatabase, hiveConfDir, hiveVersion);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build());
tableEnv.registerCatalog(catalogName, hiveCatalog);
tableEnv.useCatalog(catalogName);
在上面的示例中,我们创建了一个 HiveCatalog,指定了 Hive 的元数据存储、版本号和默认数据库。然后,我们使用 StreamTableEnvironment.registerCatalog() 方法将 HiveCatalog 注册到 Flink 中,并使用 StreamTableEnvironment.useCatalog() 方法指定默认使用的 Catalog。
在 Flink 应用程序中,可以使用 SQL 查询 Hive 中的表。例如:
String sql = "SELECT * FROM mytable";
Table table = tableEnv.sqlQuery(sql);
DataStream<Row> result = tableEnv.toAppendStream(table, Row.class);
result.print();
在上面的示例中,我们使用 SQL 查询名为 mytable 的 Hive 表,并将查询结果转换为 DataStream,然后输出到控制台。
是的,在阿里云实时计算 Flink 中,可以使用 SQL 查询 Hive 表。Flink 提供了一个名为 HiveCatalog 的 Hive 表源,可以用于在 Flink SQL 中查询和操作 Hive 表数据,支持使用 SQL DDL 命令创建和删除表、插入和查询数据等操作。具体来说,您可以按照以下步骤使用 Flink SQL 查询 Hive 表:
首先需要在 Flink 核心的配置文件 flink-conf.yaml 中添加 HiveCatalog 配置信息,包括 hive-site.xml 所在的路径、默认数据库名称、表类型等参数。例如:
catalogs:
- name: myhive
type: hive
hive-conf-dir: /path/to/hive/conf
default-database: mydb
version: 2.3.0
metastore-uri: thrift://localhost:9083
其中,name 是表源的名称,type 是表源的类型;hive-conf-dir 是 Hive 配置文件所在的路径;default-database 是默认使用的数据库名称;version 是 Hive 的版本号,metastore-uri 是 Hive metastore 的地址信息。
在 Flink SQL 客户端中,需要使用 USE CATALOG 和 USE 命令将 HiveCatalog 表源和目标数据库注册到 Flink 中。例如:
USE CATALOG myhive;
USE mydb;
其中,myhive 是 HiveCatalog 表源的名称,mydb 是要查询的 Hive 数据库的名称。
完成 HiveCatalog 表源的注册之后,就可以使用 Flink SQL 查询和操作 Hive 表数据了。例如:
SELECT * FROM mytable;
其中,mytable 是要查询的 Hive 表的名称。Flink SQL 查询操作支持标准的 Select、Insert、Update、Delete 等操作,同时也支持 Hive SQL 扩展的语法和函数库。需要注意的是,由于 Hive 使用的 Metastore 与 Flink 中表的注册方式略有不同,因此在查询 Hive 表数据时需要适当调整语法和参数,保证 Hive 和 Flink 之间的数据兼容性。
是的,Flink 支持通过 SQL 查询 Hive 表。Flink 可以通过将 Hive 的元数据通过配置传递给 Flink,使得 Flink 可以访问 Hive 中的数据并执行 SQL 查询。您可以使用 Flink Table API 或 Flink SQL API 编写查询语句,并通过 Flink 的 HiveCatalog 和 HiveTableSource 实现对 Hive 数据的访问。
具体而言,您需要将 Hive 元数据存储在 Flink 配置的目录中,并使用 Flink 的 HiveCatalog 将其注册到 Flink 中。注册后,您便可以在 Flink SQL 或 Table API 中使用该 Catalog。通过 Flink 的 HiveTableSource,您也可以将 Hive 中的表作为 Flink 的输入源进行处理。具体使用方法可以参考 Flink 的官方文档:https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/hive/
Flink可以通过sql查询hive表,使用之前需要关注对应的限制条件:SQL编辑器提交的SQL作业,仅支持开源Flink V1.11、Flink V1.12和Flink V1.13版本。 SQL支持的上下游存储(连接器)列表,请参见支持的上下游存储。具体通过sql操作Hive Catalog的方式可以参考文档创建Hive Catalog,创建Hive Catalog支持UI与SQL命令两种方式配置Hive Catalog,推荐使用UI方式配置Hive Catalog。以及通过sql方式使用Hive Catalog
是的,Flink 支持使用 SQL 查询 Hive 表。你可以使用 Flink 的 Table API 或 SQL API 来访问 Hive 中已经存在的表,这需要先配置 Hive Catalog 来连接到 Hive Metastore。具体步骤可以参考 Flink 官方文档中的介绍:Hive Catalog
肯定可以哈。Flink可以使用SQL查询Hive表。Flink提供了一个Hive Catalog,可以将Hive中的表映射为Flink中的表,从而可以使用SQL查询Hive表。
要使用Hive Catalog,需要在Flink的配置文件中配置Hive Metastore的地址和端口号,以及Hadoop配置文件的路径。配置完成后,可以使用以下语句将Hive Catalog添加到Flink中。
是的,Apache Flink可以使用SQL查询Hive表。Flink是一种快速、可靠、高效的大数据处理引擎,支持流处理、批处理以及交互式查询等一系列数据处理需求。其中,Flink提供了一个名为“Flink SQL”的模块,与Hive的SQL语言兼容,使得在Flink中查询Hive表变得非常方便。
下面是使用Flink查询Hive表的步骤:
1.确保Flink和Hive已经正确配置并可以运行在同一个集群上。
2.在Flink的SQL客户端中,创建Hive表的元数据信息。例如:
CREATE TABLE hive_table ( id INT, name STRING, age INT ) WITH ( 'connector.type' = 'hive', 'connector.version' = 'X.X.X', 'connector.path' = '/path/to/hive/warehouse', 'table.name' = 'hive_table', 'format.type' = 'orc' ) 3.使用SELECT语句查询Hive表数据。例如:
SELECT * FROM hive_table; 需要注意的是,在进行Flink SQL查询Hive表数据时,使用的SQL语法必须与Hive相同,而不是Spark SQL语法。此外,还需要确保Flink SQL和Hive的版本兼容。
以上是使用Flink查询Hive表的基本步骤,希望能够对你有所帮助。
是的,Apache Flink 提供了集成 Hive 的功能,支持通过 SQL 查询 Hive 表。具体来说,Flink 可以通过将 Hive 元数据和表信息加载到 Flink 内存中,并支持使用 SQL 对 Hive 表进行查询。此外,Flink 还支持将查询结果插入到 Hive 表或新建 Hive 表。
需要注意的是,为了实现 Flink 和 Hive 的集成,需要在 Flink 作业的配置中设置相关参数以及引入相应的依赖库。另外,Flink 也提供了支持流式 SQL 查询的功能,可以更加灵活地处理数据流。
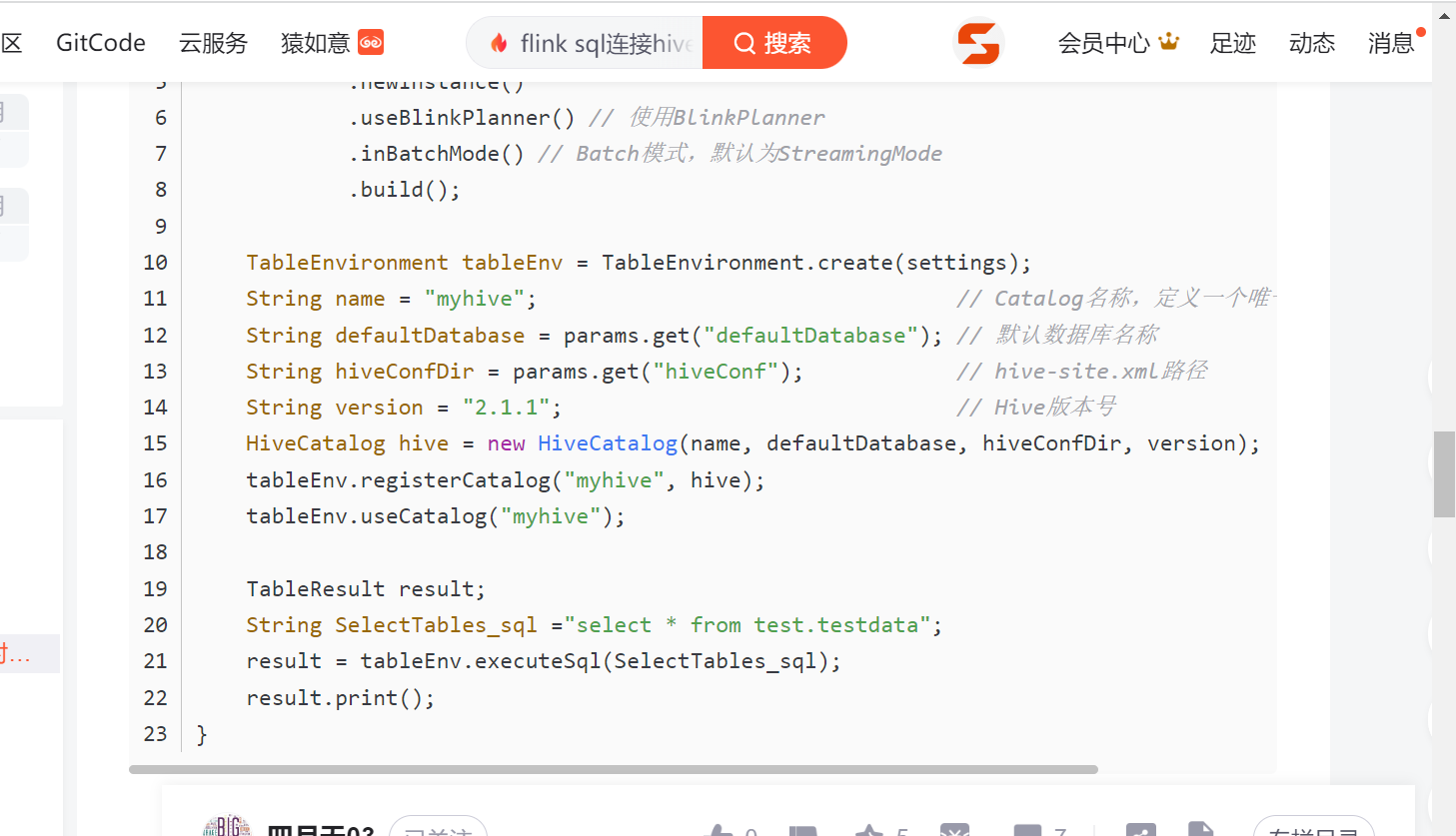
import org.apache.flink.table.catalog.hive.HiveCatalog;
public class HiveJdbcMain {
public static void main(String[] args) throws Exception {
//设置账户为hadoop,有写入hdfs权限
System.setProperty("HADOOP_USER_NAME", "hadoop");
System.setProperty("HADOOP_USER_PASSWORD", "hadoop");
//使用阿里的Planner
EnvironmentSettings settings = EnvironmentSettings.newInstance()/*.inBatchMode()*/.build();
// EnvironmentSettings settings = EnvironmentSettings.newInstance()
// .useBlinkPlanner()
// .inStreamingMode() // 有流和批inBatchMode() 任选
// .build();
// 构建table环境
TableEnvironment tableEnv = TableEnvironment.create(settings);
//设置方言 不同数据库的语句有差别
tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
//构造hive catalog 直接调用hiveconstans就可以
// Catalog名称,定义一个唯一的名称表示
String NAME="myhive";
// 默认Hive数据库名称
String DEFAULTDATABASE="default";
//hive-site.xml路径 运行Flink的Linux目录下
// String HIVECONFDIRPATH="/opt/module/hive-3.1.2/conf/";服务器文件位置
String HIVECONFDIRPATH="src/main/resources";//本地文件位置
//hive版本
String VERSION="3.1.2";
HiveCatalog myHive=new HiveCatalog(NAME, DEFAULTDATABASE,HIVECONFDIRPATH, VERSION);
//注册指定名字的catalog
tableEnv.registerCatalog("myhive",myHive);
//使用上面注册的catalog
tableEnv.useCatalog("myhive");
// 执行逻辑,需要提前创建好hive的库表。
String sql="select * from default.ems_data";
Table tableResult1 = tableEnv.sqlQuery(sql);
tableResult1.execute().print();
//获取结果的迭代器,可以循环迭代器获取结果
/*CloseableIterator<Row> collect = tableResult1.execute().collect();
System.out.println(collect.next());*/
//执行executeSql 插入或更新数据库
/*String executeSql="insert into table xxxx select * from default.ems_data";
TableResult tableResult6 = tableEnv.executeSql(executeSql);*/
}
}
楼主你好,flink是可以使用sql查询hive表的,因为flink提供支持Hive的集成,即查询和读取,可以通过配置集成Hive环境以及设置参数,即可实现sql查询hive表的功能。
是的,Flink 可以使用 SQL 查询 Hive 表。Flink 提供了对 Hive 的集成支持,包括使用 SQL 查询 Hive 表、读取 Hive 表中的数据等。
要使用 Flink 查询 Hive 表,您需要先配置 Flink 的 Hive 集成环境。具体来说,需要在 Flink 的配置文件中设置相应的 Hive 参数,例如:
hive.metastore.uris=thrift://localhost:9083
hive.exec.dynamic.partition.mode=nonstrict
其中,hive.metastore.uris 参数指定了 Hive 的元数据存储位置,hive.exec.dynamic.partition.mode 参数指定了 Hive 表的分区模式。
配置完成后,您可以在 Flink 中使用 SQL 查询 Hive 表,例如:
SELECT * FROM my_hive_table WHERE date > '2022-01-01'
在 Flink 中查询 Hive 表的语法和查询本地表的语法是相同的。Flink 会自动将查询翻译成 Hive 的查询语句,并将结果返回给 Flink。您可以使用 Flink 的 DataStream API 或 Table API 来处理查询结果。
另外,Flink 查询 Hive 表的性能可能会受到 Hive 元数据存储的访问速度和网络传输速度的限制。如果您需要在 Flink 中频繁查询 Hive 表,建议将数据复制到 Flink 的存储系统中,以获得更好的性能和可靠性。
是的,Flink 可以通过 Flink SQL 访问 Hive 表。Flink 官方文档提供了详细的介绍和使用示例,可以参考官方文档:https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/connectors/table/hive/。同时,需要注意 Flink 和 Hive 的版本兼容性。
阿里云 Flink 支持使用 SQL 查询 Hive 表。您可以使用 Flink 的 Table API 或者 SQL API 来查询 Hive 中的表数据。在阿里云 Flink 中,连接 Hive 数据源需要通过配置 JDBC 连接信息来实现。
以下是使用 Table API 查询 Hive 表的示例:
// 创建 ExecutionEnvironment 和 BatchTableEnvrionment ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); BatchTableEnvironment tableEnv = BatchTableEnvironment.create(env);
// 注册 HiveCatalog 到 Flink HiveCatalog hive = new HiveCatalog("myHiveCatalog", "default", "hive-conf-dir"); tableEnv.registerCatalog("myHiveCatalog", hive);
// 将 Hive 表作为 Flink 表进行查询 Table result = tableEnv.sqlQuery("SELECT * FROM myHiveDatabase.myHiveTable");
// 输出查询结果 DataSet output = tableEnv.toDataSet(result, Row.class); output.print(); 如果要使用 SQL API 进行查询,则需要先将 JDBC 驱动程序添加到 Maven 依赖项中,并配置 sql.client.default-catalog 和 sql.client.default-schema 参数以指定默认的 Catalog 和 Schema。然后,您可以使用类似于以下代码的方式查询 Hive 表:
// 设置默认 Catalog 和 Schema tEnv.getConfig().getConfiguration().setString("sql.client.default-catalog", "myHiveCatalog"); tEnv.getConfig().getConfiguration().setString("sql.client.default-schema", "myHiveDatabase");
// 执行查询 tEnv.executeSql("SELECT * FROM myHiveTable") .print(); 需要注意的是,在阿里云 Flink 中查询 Hive 表时,需要确保配置正确的 JDBC 连接信息。
是的,Flink 支持使用 SQL 查询 Hive 表。你试试使用 Flink 提供的 HiveCatalog 将 Hive 中的表注册到 Flink 中,并使用 Flink SQL 进行查询。
是的,Flink 支持通过 SQL 查询 Hive 表。
Flink 支持通过 Hive Catalog 将 Hive 表暴露给 Flink 的 Table API 和 SQL,可以直接使用 CREATE CATALOG 命令创建 Hive Catalog,注册完后就可以在 Flink 中通过 SQL 查询 Hive 表了。
以下是一个具体的示例,假设你已经在 Flink 集群中搭建好了 Hive Catalog。你可以通过以下命令将 Hive Catalog 注册到 Flink 中:
CREATE CATALOG hive_catalog WITH(
'type'='hive',
'default-database'='default',
'hive-conf-dir'='/path/to/hive/conf/dir'
);
其中 type 参数指定了 Catalog 的类型为 Hive,default-database 参数指定了默认的数据库为 default,hive-conf-dir 参数指定了 Hive 的配置文件所在目录。你可以根据实际情况进行修改。
然后,你可以使用 USE CATALOG 命令将 Hive Catalog 作为当前的 Catalog,例如:
USE CATALOG hive_catalog;
接下来,你就可以使用 SQL 查询 Hive 表了,例如:
SELECT * FROM hive_table;
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



