
chunk-size设置为3万,看jm日志chunk-size跟设置的对不上,两百多万的表直接给分到一个chunk里面,任务跑不动,大家有遇到这种情况吗?怎么办?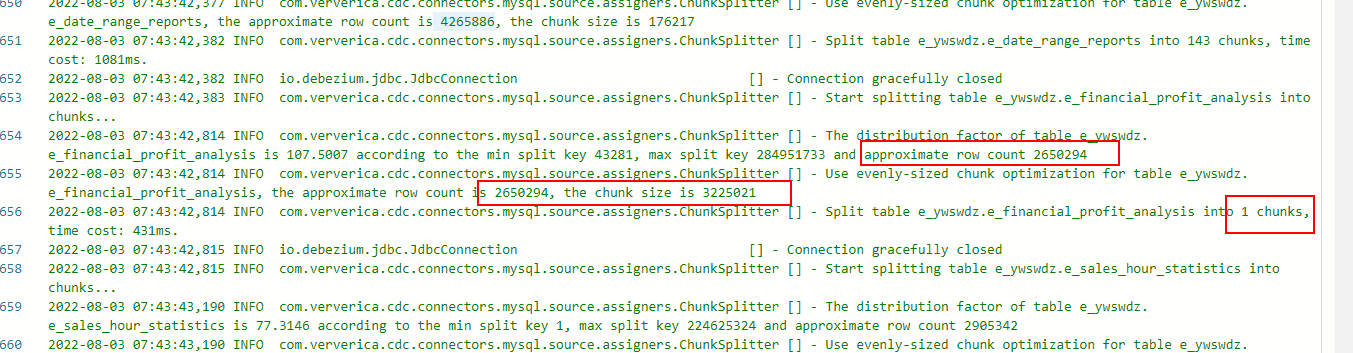
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的信息,您将chunk-size设置为3万,但在JM(可能指Job Manager)日志中发现实际的chunk-size与您设置的不匹配。而且对于一个拥有两百多万行数据的表,所有数据都被分配到一个chunk中,导致任务无法正常运行。这可能是由于以下原因导致的:
配置错误:请确保您正确配置了chunk-size参数,并且将其应用于正在运行的任务。检查您的配置文件或命令行参数,确保没有其他地方覆盖了该值。
数据分布不均匀:如果表中的数据分布非常不均匀,例如大部分数据集中在一小部分id范围内,那么根据设置的chunk-size,可能会导致某个chunk包含大量数据。这种情况下,您可以尝试使用其他方式进行数据切分,例如按照范围、哈希等切分策略,以更好地平衡数据分布。
问题或限制:具体的数据处理框架或工具可能存在特定的问题或限制,导致chunk-size无法按预期生效。请查阅相关文档、社区论坛或官方支持渠道,了解您所使用的工具是否具有已知的限制或问题,并找到解决方案或工具的最佳实践。
解决这个问题的方法可能因使用的具体工具和框架而异。以下是一些可能的解决方案:
调整chunk-size:尝试将chunk-size设置为不同的值,并观察是否能够正确划分数据。根据您的数据量和分布情况,逐步调整chunk-size的值,以找到最适合的设置。
改变数据切分策略:考虑使用其他切分策略,例如按照范围、哈希等方式进行数据切分。根据您的数据特性,选择适合的切分策略,以确保数据在各个chunk中均匀分布。
参考最佳实践和文档:查阅相关工具或框架的官方文档和最佳实践指南,了解如何正确配置和使用chunk-size参数。同时,与社区论坛或官方支持渠道交流,寻求其他用户或开发者的经验和建议。
请注意,具体的解决方案可能会因您所使用的具体工具、框架和环境而有所不同。建议仔细研究相关文档和资源,并与社区或官方支持进行进一步的沟通和咨询,以获取更准确和针对性的解决方案。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



