
请教个MongoShake过滤孤儿文档的代码的问题。图里判断一个sharding key的区间之后,为什么没有接着判断其他的key的区间而是直接break了呢?这里的逻辑是对的嘛? 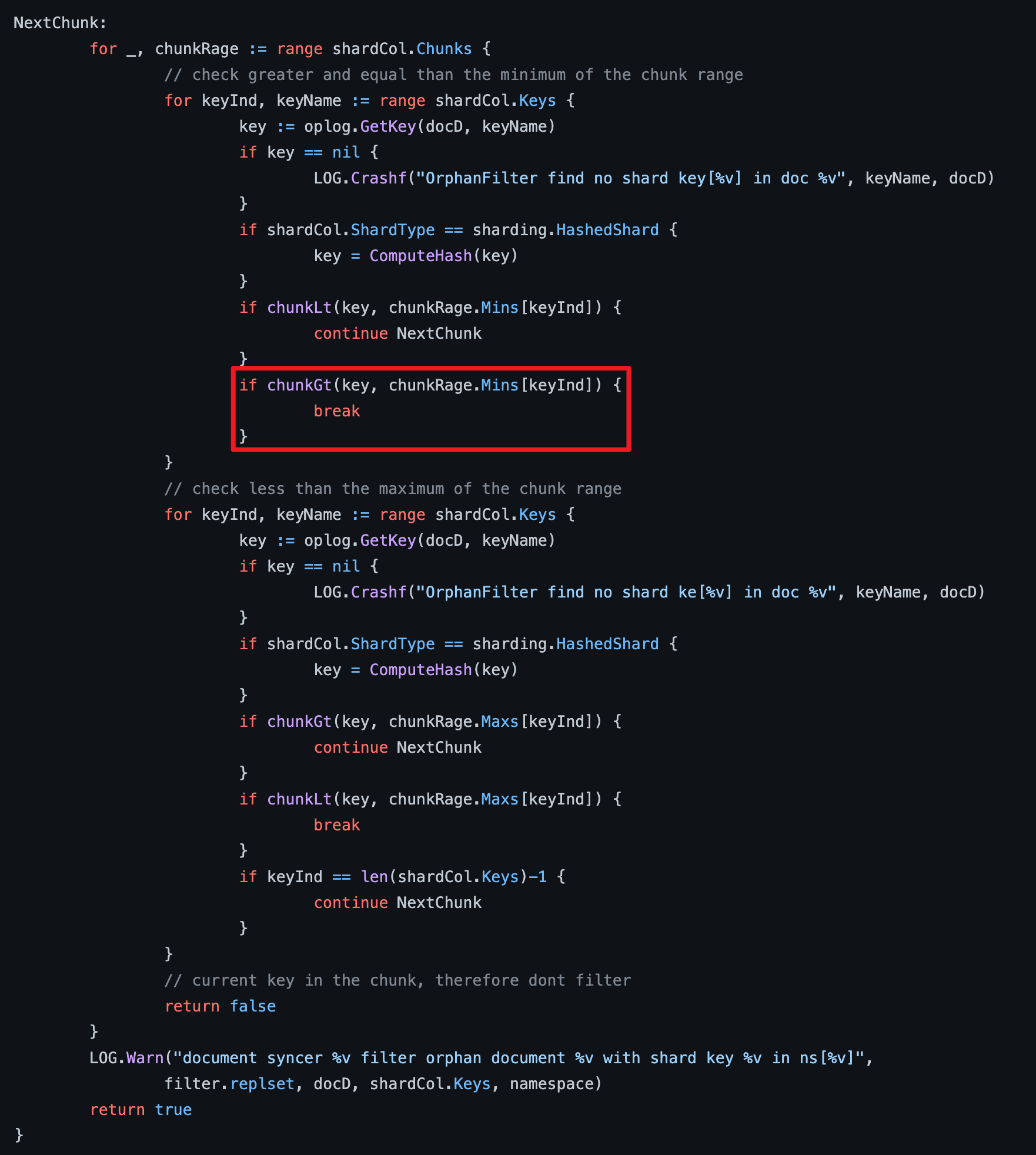
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在MongoDB分片集群中,孤儿文档(orphaned documents)是指那些由于分片键更改或迁移后未能正确移动到其所属分片的文档。关于您提到的代码逻辑问题,虽然直接的代码示例未给出,但根据描述,如果是在遍历分片键区间并检查孤儿文档的过程中使用了break语句,这通常意味着一旦发现某个分片键区间存在孤儿文档并进行了相应处理(比如记录、删除或标记),循环就可能被设计为停止进一步检查当前集合的其他分片键区间。
这样的逻辑可能是基于以下考虑: - 效率与资源管理:检查孤儿文档是一个可能消耗资源的操作,尤其是对于大数据集。一旦确定某一分片存在孤儿文档,开发人员可能认为没有必要立即继续检查同一集合的其他所有分片键区间,特别是当存在大量分片或预期孤儿文档是偶发情况时。 - 阶段处理策略:在某些场景下,清理工作可能被设计成分阶段进行,先定位一个有问题的区间并处理,之后再逐步扩大检查范围或按计划处理其他区间,这样可以更好地控制操作影响和监控效果。
然而,是否合理还需结合具体的应用场景和清理策略来判断。如果目的是全面检查并清理所有孤儿文档,那么直接break可能不恰当,应确保循环能完整遍历所有分片键区间。正确的做法应当是遍历完所有定义的分片键区间,除非有明确的设计理由提前终止。
重要提醒: - 在执行任何孤儿文档清理脚本之前,请务必确认业务能够容忍潜在的数据变动,并做好数据备份。 - 确认使用的MongoDB版本支持所采用的清理命令或方法,如前所述,不同版本间可能存在差异。
综上所述,代码中使用break的逻辑是否正确,取决于整体清理策略和实际需求。如果目标是全面清理,则需调整逻辑以遍历所有区间;若出于特定考量则可能是有意为之。

