
请问有没有人知道clickhouse 中 limit语句执行的逻辑,图片中,上面的SQL可以执行成功,但是读取数据的速率较慢200Mb/s,下方的sql则执行失败,报Memory limit (for query) exceeded,内存不够了,但是数据读取速率快,在4Gb/s。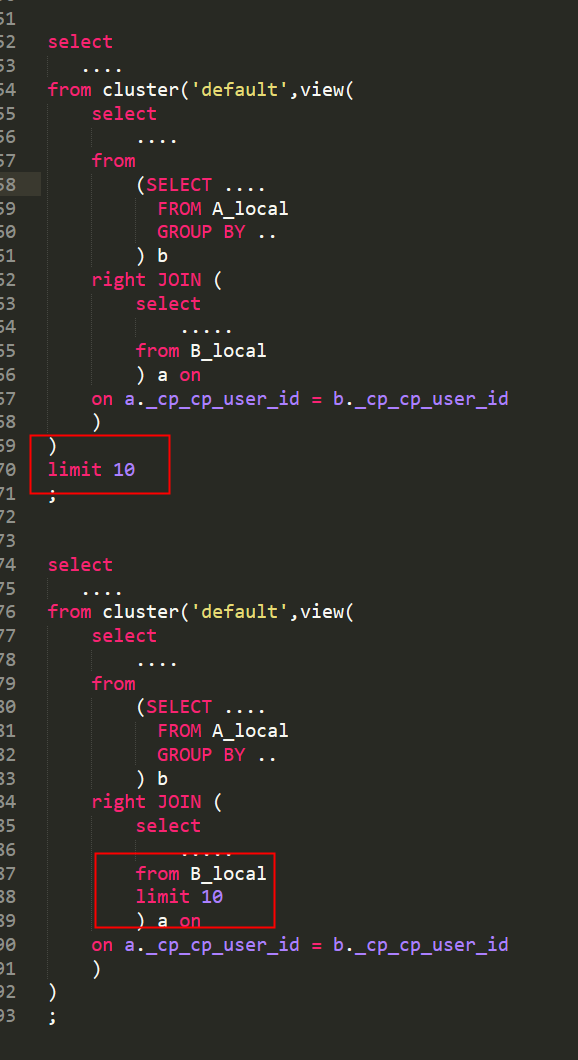
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在ClickHouse中,LIMIT语句的执行逻辑与查询优化器密切相关。它旨在限制返回给客户端的结果行数,理论上应减少查询处理所需的内存。然而,实际效果取决于查询计划和数据分布。
对于您提到的现象,这里有几个关键点来解释:
慢速但成功的查询(200Mb/s):
LIMIT但查询速度较慢时,这可能是因为ClickHouse在尝试优化查询执行过程,比如先进行排序或聚合操作以应用LIMIT。尽管读取速率不高,但它可能在更早的阶段就应用了限制条件,从而避免了处理大量数据到内存中。快速但失败的查询(4Gb/s):
Memory limit (for query) exceeded,说明该查询在尝试加载更多数据到内存中以便快速完成计算。这通常发生在ClickHouse决定先全量读取数据再应用LIMIT的场景,尤其是在没有有效利用索引或无法提前过滤掉大部分数据的情况下。解决建议:
优化查询: 考虑是否可以在WHERE子句中添加更多的过滤条件,或者利用索引来减少需扫描的数据量。确保LIMIT能尽早作用于数据流中,减少不必要的数据处理。
调整内存配置: 根据错误提示,可以通过EMR控制台调整ClickHouse的相关配置参数,如增加max_memory_usage或为特定查询/用户设置内存限制,以适应查询需求,但这仅是临时解决方案,且需谨慎操作以免影响其他查询。
监控与分析: 使用ClickHouse的系统表如system.query_log来分析高内存消耗查询的具体情况,包括CPU和内存使用情况,进而针对性地优化。
数据预处理: 确保写入数据前进行适当排序或分区,特别是按时间序列数据,可以显著提升基于时间范围查询的效率,减少查询时的内存占用和提高执行速度。
综上所述,查询执行效率和内存使用情况受到多种因素影响,通过优化查询结构、合理配置内存限制以及深入分析查询日志,可以有效解决此类问题。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
