
哪位大佬遇到过,使用udf函数乱码问题啊?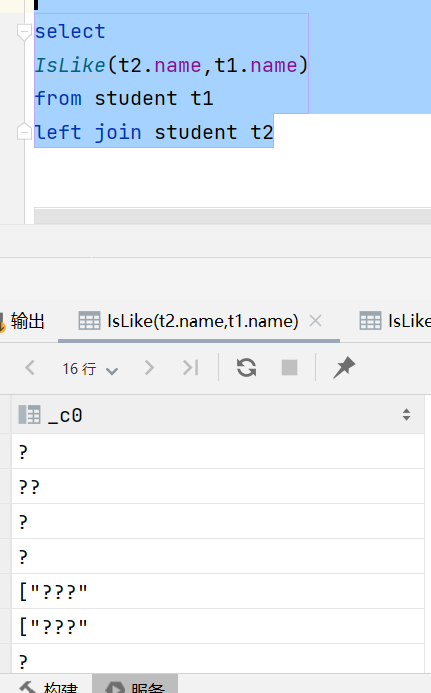
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
遇到UDF函数乱码问题,通常涉及到编码设置不正确,导致数据读取或处理时字符无法正确识别。根据知识库资料,这里有几个常见现象及解决措施:
SyntaxError: Non-ASCII character '\xe8' in file xxx. on line yyy# -*- coding: utf-8 -*-。UnicodeEncodeError: 'ascii' code can't encode characters in position x-y: ordinal not in range(128)UnicodeDecodeError: 'utf-8' codec can't decode byte xxx in position xxx: invalid continuation byteis_encoding(column, 'utf-8', 'utf-8') = true来筛选出正确的编码数据。cast(column as binary)转换数据类型。通过上述措施,你应该能够解决UDF函数执行过程中出现的乱码问题。如果问题依然存在,请检查具体错误日志以获取更详细的错误信息进行进一步分析。
