
如何对数据库架构进行调优?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
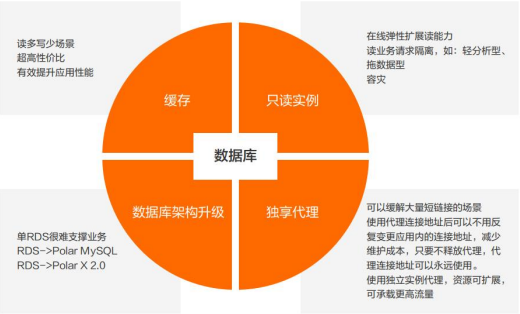
如果业务的访问都用数据库支撑的话成本高昂,缓存可以代替一部分关系型数据 库在读方面的请求。基于原理的设计以及 成本方面考虑,缓存的读性能比关系型数据库好,性价比较高。
到数据库层面,如果是读多写少,针对于单个实例很难支撑的情况下,可以助于只读实例。只读实例可以实现在线弹性 的扩展读能力,读的业务请求可以实现隔离,例如可以把轻分析型以及拖数据类型在只读实例内完成。
此外,每个只读实例都有一个单独的链接地址,如果把某一类的业务和其他的业务区分开,例如某一类的只读的这个场景,只到某一个实例访问,可以单独链接只读实例的链接串。
如果要是想从整个层面来控制主实例和只读实例的访问,可以借助负载均衡独享代理完成。独享代理可以缓解大量短链接的场景,使用代理后不用反复变更应用类的链接地址,减少维护成本。使用独享代理之后,可以对线上的资源实现可扩展,承受更高的流量。如果是 RDS 的实例规格以及只读实例都已经升到最大,但仍然不能支撑业务发展的话,可以考虑把 RDS 的升级到 Polar MySQL 或者是分库分表 PolarDB X 2.0,完成读写容量的扩展。
资源来源于《阿里云数据库运维实战问题改》
https://developer.aliyun.com/topic/download?spm=a2c6h.20345107.J_6399686890.1.2e1e17dbzKUX5r&id=8198
