
流式计算平台是由如何搭建的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
首先,数据采集通常来讲是一个分布式的消息队列,它采用的发布或者订阅是一种消息 的分发机制,同时还能在后面的计算和存储引擎出现问题时把消息缓存在消息队列里面。这 个分布式的消息队列本身也是高可用的,当出现流量峰值,它也能对后面的存储引擎有保护 作用。 当数据流进来之后,第二步就是分布式计算引擎。首先需要对进来的数据做校验,判断 数据是否合法,格式是否是我期待的,有没有脏数据等等,同时还可以去业务数据库引擎里 拉取一些数据,把它变得更加丰富,来辅助后期的分析。另外,现在的流式计算平台能让数 据计算更加精确,这一点基于事件时间开窗的计算。而流式的分布式计算引擎本身在云上也 具备弹性,且可以做热更新,这对整个平台的稳定性和扩展性来说都是非常友好的。 除了消息队列和分布式计算引擎之外,后面我们还会选择三个比较关键的引擎,其中一 个就是我们主要要讨论的引擎 Elasticsearch。除此之外可能还会引入高 IO 的 KW 列存, 最常用的是 HBase。这两个引擎在这个组合里面扮演的是对于非常热的数据的一些处理和 计算,是实时的一部分。第三个引擎我们引入的通常来讲是线下的比如数据仓库或者一些 MPP 引擎。大家的选择面是非常广的,比如传统的 HIVE,还有开源的 Greenplum 等等, 甚至一些商业产品都可以是在我们选择清单里的一些存储,这些存储的角色更倾向于一些偏 线下的计算,或者是比较温的一些数据的计算,比如过去七天的一些数据的计算,基于每天: 去绘制的报表和计算。在热数据这一部分,Hbase 通常来讲不是一个非常必要的引擎,只 是在我们有非常高 IO 的吞吐的场景下不得不引入它,它的核心的实时数据分析这一部分通 常来讲我们还是用 Elasticsearch 去完成的。 基于上面这一套引擎,下面还会有两个非常重要的基础组件,这个在云端实际上也都给 大家封装非常好的一些成熟的产品和底座。 如果大家是在 on-premise 自己的 IDC 机房 里去部署的,还需要维护这两套系统,在本地需要有一个高性能的网络,能够支撑比如消息 队列之间的消息传递,还有分布式计算引擎之间 worker 节点的一些 shuffling 的操作,也 都需要通过高性能网络及交换数据,数据引擎之间的数据交换,节点之间的 shuffle 也都需 要高性能的网络来支撑。 另外就是底层的分布式存储,这个存储的选择当然也非常多,在云端我们通常会借助对 象存储来做比如分布式计算引擎的文件输出,或者数据的输出,还有错误数据的一些落地, 后面的数据引擎比如 Elasticsearch 就会做一些数据的备份,比如说 snapshots。分布式 存储可以作为我们数据的一些 archive,比如一些老旧数据的备份,或者在关键时刻需要重 塑,可以很快地从这些 snapshots 里面恢复数据。
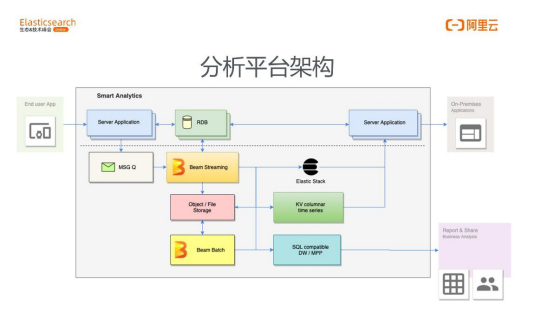
这个平台的组建实际上是非常简单的,那么在根据这些组件搭建真正的架构的时候,就 可以看到上图这样的一张架构图。中间虚线部分上面是真正的业务引擎,里面有我们的服务 器,还有处理业务的关系型数据库。真正的数据就是从我们服务上来的,通常来讲,比如说 可能有这些服务器的日志,监控,业务上来讲,从这个业务服务器上我们可能会采集很多用 户端的一些行为,比如说用户在你的平台上购买什么样的商品,或者社交类的产品、内容类 的产品都点开了哪些内容等等。这些数据就会被实时地发送到刚才介绍的消息队列里面(图 中左边信封的图标),在这个队列缓存里进行缓存之后,就会把它放到后面的 Streaming 引擎里面去。这个引擎用到了 Beam 这样一个驱动层,分布式计算的一个框架,它也是一 个开源的分布式计算引擎的框架,只是一个驱动层。在这一方面,我们想把这个平台打造的 通用性好一些,所以在这个关键的分布式计算环节,我们选择了这样一个驱动层。 它所带 来的好处是比如我在一次编码之后,可以驱动不同的分布式计算引擎去帮我完成计算任务, 而且它是批流一体的引擎,Beam 的代码就可以驱动 Flink 去完成计算任务,也可以驱动很 多其他的 driver。你可以去做流式的处理,也可以做线下的 Bash 处理,这是我们选择 Beam 的一个原因。 当然,Beam 也会有它一定的局限性,可能每个引擎之间有不同的非 常独立的 calculator,没有能很好地移植到 Beam 里面,它就不支持。所以大家在真正使 用的时候,还是要根据自己的业务看 Beam 是不是一个非常好的选择,目前在我们服务的 客户当中 Beam 基本上是可以满足绝大多数的需求的。 既然 Beam 是一个批流一体的引擎,并且分布式计算已经会做一些 ETL,然后从我们 的业务数据里我们可能会拉取一些业务表,来跟我们实时采集的用户行为数据或者日志数据 做一些联动,方便我们日后去做分析。这个时候我们会把一些不符合或者有问题的数据输送 到对象存储上面去做备份,与此同时还会把明细数据也都打包压缩备份一份放在对象存储上 面以备不时之需。 接下来后面接的引擎我们就会把一些实时的数据直接注入到 Elasticsearch 引擎里面, 去支撑我们的业务包括实时分析业务。在非常高吞吐的情况下,我们会引入 HBase,就是 下面介入的 KV 型的列存。它的列存表的设计有宽表或高表两种,是完全取决于我们的业务 的,但是一旦我们引入 Hbase 这种 KV 引擎的话有一点需要注意,就是明细的数据才可能 会录到 HBase 里面去,为了减少 Elasticsearch 本身的 IO,我们会把一部分计算任务放 在中间的分布式计算引擎里面去做。举个简单的例子,假设打车这样一个场景,用户或车辆 的实时地理位置信息是非常海量的数据注入到系统里面,在这个订单当前没有完成的时候, 我们都可以把这些实时高 IO 的数据放到 HBase 里面进行查询,或支撑你的业务,当这个 session 结束之后,把它归拢成一条数据放到 ES 里面去,我们在 Elasticsearch 里面就 可以做一些实时订单的分析,轨迹,金额,或者官方的一些客服人员去对这个订单做查询和 服务我们的客户。这就是 ES 加 HBase 在实时的场景是这样配合工作的,并不是同样的数 据全部录入到两个引擎里面去。 第三个与此同时我们还会做的事情就是放到 Data Warehouse 里面去做一些线下的 分析。另外,可以看到 Beam 还会承担一部分 BASH 的工作,也许我们会有一部分这种批 处理的工作,在实时的数据落到对象存储之后,我们也可以定时地让 Beam 去驱动 Flink 等引擎完成后面的一系列批处理的工作。
资料来源于《开源与云Elasticsearch应用剖析》下载地址:https://developer.aliyun.com/topic/download?id=1169
