
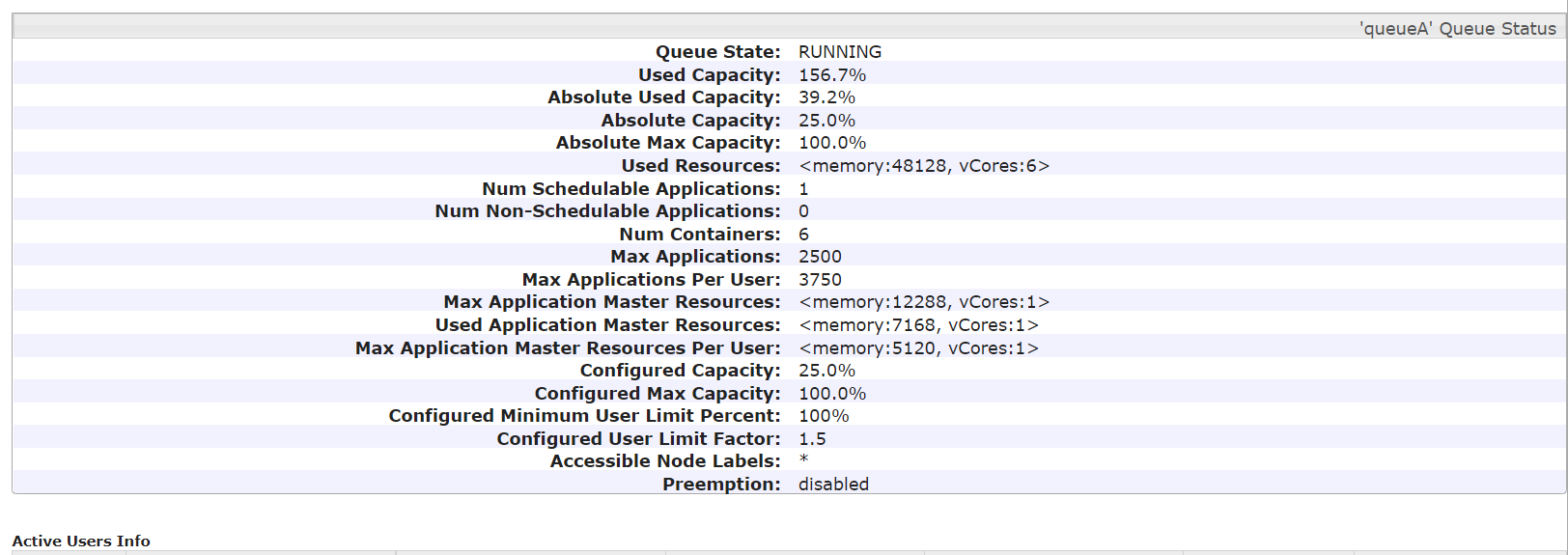
问题:156.7% ,39.2% 是怎么计算出来的?
Used Capacity: 156.7% Absolute Used Capacity: 39.2%
总资源:总共120G, 3个节点,24Cores, 现有三个队列: defaut : 60G, User_Limit_Factor = 1 queueA : 30G, User_Limit_Factor = 1.5 queueB : 30G, User_Limit_Factor = 0.1
现有一个提交任务,提交命令如下:
/apache/app/spark3.1.1/bin/spark-submit \
--class com.rhb.readKafka \
--master yarn \
--deploy-mode cluster \
--queue queueA \
--packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.3 \
--driver-memory 6g \
--executor-cores 3 \
--executor-memory 7g \
--num-executors 20 \
/root/rhb/mutiUserDemo0.1.jar
运行之后的资源分配图如下:
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的信息,要理解“Used Capacity: 156.7%”和“Absolute Used Capacity: 39.2%”,我们首先需要明确这些百分比是如何计算的。在YARN(Yet Another Resource Negotiator)资源管理系统中,这些百分比通常与队列或集群资源使用情况相关。
对于您的场景,我们需要知道每个队列的具体使用情况来直接计算“156.7%”。然而,没有直接给出每个队列的实际使用量,但我们可以尝试推断。由于任务提交到了queueA,并且指定了资源需求,我们可以基于这些需求来间接分析。
任务提交到queueA时,请求的资源包括: - Driver Memory: 6G - Executor Cores: 3 * 20 = 60 cores - Executor Memory: 7G * 20 = 140G
但是,这里有一个明显的矛盾点,因为Executor Memory的总和超出了单个节点的内存总量,更不用说整个队列或集群了。这可能是一个假设错误或者输入数据的问题,因为实际应用中这样的请求是无法被满足的,除非有其他机制未被提及(比如动态资源分配)。因此,正确的资源请求应该重新审视,但基于现有信息,我们无法直接计算出准确的“Used Capacity”。
“Absolute Used Capacity: 39.2%”可能是指所有队列加起来实际消耗的资源占整个集群物理资源的百分比。如果总资源是120G内存加上CPU核心数(未明确具体如何分配),那么这个百分比可能反映了所有正在运行的任务所占用资源的总和。
由于直接计算缺乏具体每个队列的实际使用数据,且任务提交参数存在不合理之处,我们不能直接算出这两个百分比。不过,“156.7%”的Used Capacity表明某队列(很可能是讨论中的queueA)的使用超过了其配置的最大资源限制,这可能是因为User Limit Factor的应用、资源抢占或是统计时间窗口内的瞬时峰值导致的。
而“39.2%”的Absolute Used Capacity则意味着整体上集群资源的使用率相对较低,尽管有个别队列可能过度使用,但集群作为一个整体尚未达到饱和状态。
为了获得准确的计算方法,需要具体的每个队列实时使用资源的数据以及它们的配置上限,并结合YARN的调度策略和队列管理规则进行分析。
