
执行命令 bin/nutch crawl urls -dir tmpData -threads 50 -depth 2
nutch-site.xml配置:

简略报错信息:
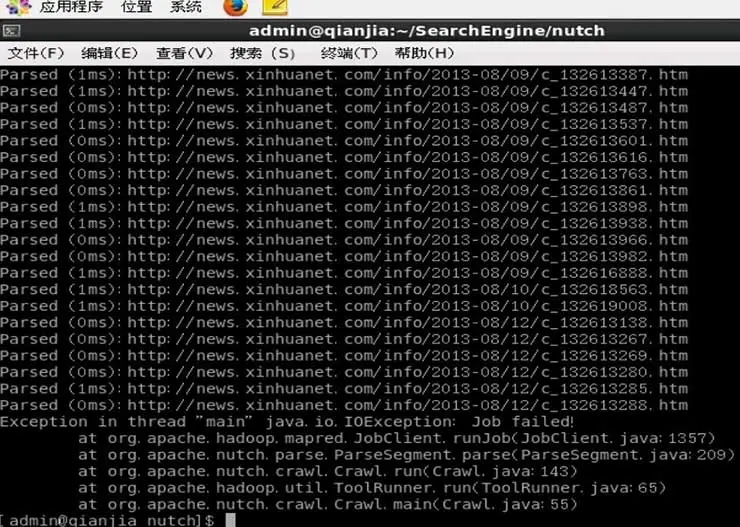
hadoop.log日志文件里的报错信息:

报错所指源码部分一:
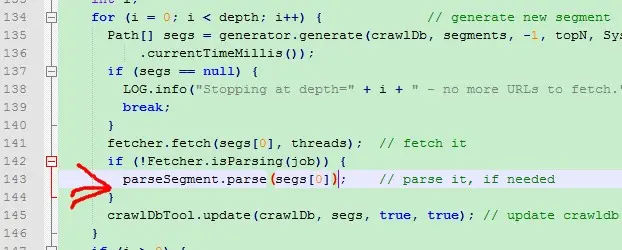
报错所指源码部分二:
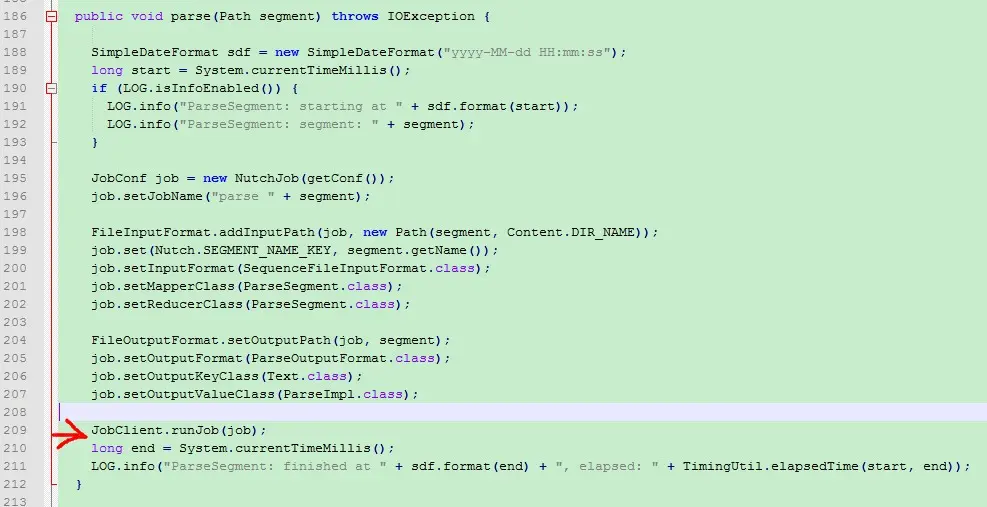
网上类似的关于此问题的帖子:
http://lucene.472066.n3.nabble.com/Nutch-1-7-Parser-java-lang-OutOfMemoryError-unable-to-create-new-native-thread-td4096365.html
没看懂。。。
求大神解决。跪求。。。!!!
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
求解!
这个问题有两个解决方案,一个是你加入topN参数,不超过2000就parse成功。
第二个,修改源代码,重新编译。
修改:src/java/org/apache/nutch/parse/ParseSegment.java
定义个类成员
<spanstyle="color:#333333;font-family:Menlo,'LiberationMono',Consolas,'CourierNew','andalemono','lucidaconsole',monospace;font-size:12px;line-height:18px;background-color:#F4FAFF;">privateParseUtilparseUtil=null;
然后,在99行修改为
<preclass="brush:java;toolbar:true;auto-links:false;">ParseResultparseResult=null;try{//parseResult=newParseUtil(getConf()).parse(content);if(parseUtil==null)parseUtil=newParseUtil(getConf());parseResult=parseUtil.parse(content);}catch(Exceptione){LOG.warn("Errorparsing:"+key+":"+StringUtils.stringifyException(e));return;}