
从 Java 代码到 Java 堆 背景信息:Java 进程的内存使用 参考知识 Java 对象详解 Java 数组对象详解 更为复杂数据结构详解 32 位和 64 位 Java 对象 Java 集合的内存使用 集合中的空白空间 集合的扩展和重新调整 Java 集合:汇总 集合的实际应用:PlantsByWebSphere 和 WebSphere Application Server Version 7 通过 Memory Analyzer 查找低填充率 结束语:报错
分析是一种美德,PS原文地址:http://www.ibm.com/developerworks/cn/java/j-codetoheap/
理解和优化您的应用程序的内存使用
本文将为您提供 Java™ 代码内存使用情况的深入见解,包括将 int 值置入一个 Integer 对象的内存开销、对象委托的成本和不同集合类型的内存效率。您将了解到如何确定应用程序中的哪些位置效率低下,以及如何选择正确的集合来改进您的代码。
13![]() 评论:
评论:
 内容
内容 优化应用程序代码的内存使用并不是一个新主题,但是人们通常并没有很好地理解这个主题。本文将简要介绍 Java 进程的内存使用,随后深入探讨您编写的 Java 代码的内存使用。最后,本文将展示提高代码内存效率的方法,特别强调了 HashMap 和 ArrayList 等 Java 集合的使用。
如需进一步了解 Java 应用程序的进程内存使用,请参阅 Andrew Hall 撰写的 developerWorks 文章 “内存详解”。这篇文章介绍了 内存详解 以及 AIX® 提供的布局和用户空间,以及 Java 堆和本机堆之间的交互。
通过在命令行中执行 java 或者启动某种基于 Java 的中间件来运行 Java 应用程序时,Java 运行时会创建一个操作系统进程,就像您运行基于 C 的程序时那样。实际上,大多数 JVM 都是用 C 或者 C++ 语言编写的。作为操作系统进程,Java 运行时面临着与其他进程完全相同的内存限制:架构提供的寻址能力以及操作系统提供的用户空间。
架构提供的内存寻址能力依赖于处理器的位数,举例来说,32 位或者 64 位,对于大型机来说,还有 31 位。进程能够处理的位数决定了处理器能寻址的内存范围:32 位提供了 2^32 的可寻址范围,也就是 4,294,967,296 位,或者说 4GB。而 64 位处理器的可寻址范围明显增大:2^64,也就是 18,446,744,073,709,551,616,或者说 16 exabyte(百亿亿字节)。
处理器架构提供的部分可寻址范围由 OS 本身占用,提供给操作系统内核以及 C 运行时(对于使用 C 或者 C++ 编写的 JVM 而言)。OS 和 C 运行时占用的内存数量取决于所用的 OS,但通常数量较大:Windows 默认占用的内存是 2GB。剩余的可寻址空间(用术语来表示就是用户空间)就是可供运行的实际进程使用的内存。
对于 Java 应用程序,用户空间是 Java 进程占用的内存,实际上包含两个池:Java 堆和本机(非 Java)堆。Java 堆的大小由 JVM 的 Java 堆设置控制:-Xms 和 -Xmx 分别设置最小和最大 Java 堆。在按照最大的大小设置分配了 Java 堆之后,剩下的用户空间就是本机堆。图 1 展示了一个 32 位 Java 进程的内存布局:

在 图 1 中,可寻址范围总共有 4GB,OS 和 C 运行时大约占用了其中的 1GB,Java 堆占用了将近 2GB,本机堆占用了其他部分。请注意,JVM 本身也要占用内存,就像 OS 内核和 C 运行时一样,而 JVM 占用的内存是本机堆的子集。
在您的 Java 代码使用 new 操作符创建一个 Java 对象的实例时,实际上分配的数据要比您想的多得多。例如,一个 int 值与一个 Integer 对象(能包含 int 值的最小对象)的大小比率是 1:4,这个比率可能会让您感到吃惊。额外的开销源于 JVM 用于描述 Java 对象的元数据,在本例中也就是 Integer。
根据 JVM 的版本和供应的不同,对象元数据的数量也各有不同,但其中通常包括:
对象元数据后紧跟着对象数据本身,包括对象实例中存储的字段。对于 java.lang.Integer 对象,这就是一个 int。
如果您正在运行一个 32 位 JVM,那么在创建 java.lang.Integer 对象实例时,对象的布局可能如图 2 所示:
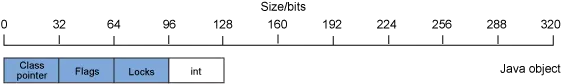
如 图 2 所示,有 128 位的数据被占用,其中用于存储 int 值的为 32 位,而对象元数据占用了其余的 96 位。
数组对象(例如一个 int 值数组)的形状和结构与标准 Java 对象相似。主要差别在于数组对象包含说明数组大小的额外元数据。因此,数据对象的元数据包括:
图 3 展示了一个 int 数组对象的布局示例:
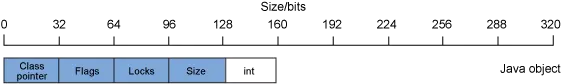
如 图 3 所示,有 160 位的数据用于存储 int 值内的 32 位数据,而数组元数据占用了其余 160 位。对于 byte、int 和 long 等原语,从内存的方面考虑,单项数组比对应的针对单一字段的包装器对象(Byte、Integer 或 Long)的成本更高。
良好的面向对象设计与编程鼓励使用封装(提供接口类来控制数据访问)和委托(使用 helper 对象来实施任务)。封装和委托会使大多数数据结构的表示形式中包含多个对象。一个简单的示例就是 java.lang.String 对象。java.lang.String 对象中的数据是一个字符数组,由管理和控制对字符数组的访问的 java.lang.String 对象封装。图 4 展示了一个 32 位 Java 进程的java.lang.String 对象的布局示例:
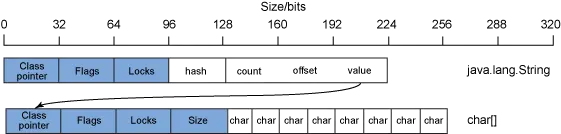
如 图 4 所示,除了标准对象元数据之外,java.lang.String 对象还包含一些用于管理字符串数据的字段。通常情况下,这些字段是散列值、字符串大小计数、字符串数据偏移量和对于字符数组本身的对象引用。
这也就意味着,对于一个 8 个字符的字符串(128 位的 char 数据),需要有 256 位的数据用于字符数组,224 位的数据用于管理该数组的java.lang.String 对象,因此为了表示 128 位(16 个字节)的数据,总共需要占用 480 位(60 字节)。开销比例为 3.75:1。
总体而言,数据结构越是复杂,开销就越高。下一节将具体讨论相关内容。
之前的示例中的对象大小和开销适用于 32 位 Java 进程。在 背景信息:Java 进程的内存使用 一节中提到,64 位处理器的内存可寻址能力比 32 位处理器高得多。对于 64 位进程,Java 对象中的某些数据字段的大小(特别是对象元数据或者表示另一个对象的任何字段)也需要增加到 64 位。其他数据字段类型(例如 int、byte 和 long )的大小不会更改。图 5 展示了一个 64 位 Integer 对象和一个 int 数组的布局:
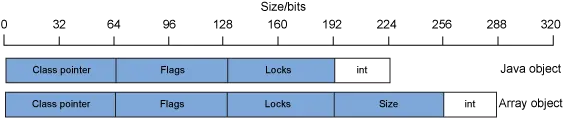
图 5 表明,对于一个 64 位 Integer 对象,现在有 224 位的数据用于存储 int 字段所用的 32 位,开销比例是 7:1。对于一个 64 位单元素 int数组,有 288 位的数据用于存储 32 位 int 条目,开销比例是 9:1。这在实际应用程序中产生的影响在于,之前在 32 位 Java 运行时中运行的应用程序若迁移到 64 位 Java 运行时,其 Java 堆内存使用量会显著增加。通常情况下,增加的数量是原始堆大小的 70% 左右。举例来说,一个在 32 位 Java 运行时中使用 1GB Java 堆的 Java 应用程序在迁移到 64 位 Java 运行时之后,通常需要使用 1.7GB 的 Java 堆。
请注意,这种内存增加并非仅限于 Java 堆。本机堆内存区使用量也会增加,有时甚至要增加 90% 之多。
表 1 展示了一个应用程序在 32 位和 64 位模式下运行时的对象和数组字段大小:
| 字段类型 | 字段大小(位) | |||
|---|---|---|---|---|
| 对象 | 数组 | |||
| 32 位 | 64 位 | 32 位 | 64 位 | |
| boolean | 32 | 32 | 8 | 8 |
| byte | 32 | 32 | 8 | 8 |
| char | 32 | 32 | 16 | 16 |
| short | 32 | 32 | 16 | 16 |
| int | 32 | 32 | 32 | 32 |
| float | 32 | 32 | 32 | 32 |
| long | 32 | 32 | 64 | 64 |
| double | 32 | 32 | 64 | 64 |
| 对象字段 | 32 | 64 (32*) | 32 | 64 (32*) |
| 对象元数据 | 32 | 64 (32*) | 32 | 64 (32*) |
* 对象字段的大小以及用于各对象元数据条目的数据的大小可通过 压缩引用或压缩 OOP 技术减小到 32 位。
IBM 和 Oracle JVM 分别通过压缩引用 (-Xcompressedrefs) 和压缩 OOP (-XX:+UseCompressedOops) 选项提供对象引用压缩功能。利用这些选项,即可在 32 位(而非 64 位)中存储对象字段和对象元数据值。在应用程序从 32 位 Java 运行时迁移到 64 位 Java 运行时的时候,这能消除 Java 堆内存使用量增加 70% 的负面影响。请注意,这些选项对于本机堆的内存使用无效,本机堆在 64 位 Java 运行时中的内存使用量仍然比 32 位 Java 运行时中的使用量高得多。
在大多数应用程序中,大量数据都是使用核心 Java API 提供的标准 Java Collections 类来存储和管理的。如果内存占用对于您的应用程序极为重要,那么就非常有必要了解各集合提供的功能以及相关的内存开销。总体而言,集合功能的级别越高,内存开销就越高,因此使用提供的功能多于您需要的功能的集合类型会带来不必要的额外内存开销。
其中部分最常用的集合如下:
除了 HashSet 之外,此列表是按功能和内存开销进行降序排列的。(HashSet 是包围一个 HashMap 对象的包装器,它提供的功能比HashMap 少,同时容量稍微小一些。)
HashSet 是 Set 接口的实现。Java Platform SE 6 API 文档对于 HashSet 的描述如下:
一个不包含重复元素的集合。更正式地来说,set(集)不包含元素 e1 和 e2 的配对 e1.equals(e2),而且至多包含一个空元素。正如其名称所表示的那样,这个接口将建模数学集抽象。
HashSet 包含的功能比 HashMap 要少,只能包含一个空条目,而且无法包含重复条目。该实现是包围 HashMap 的一个包装器,以及管理可在 HashMap 对象中存放哪些内容的 HashSet 对象。限制 HashMap 功能的附加功能表示 HashSet 的内存开销略高。
图 6 展示了 32 位 Java 运行时中的一个 HashSet 的布局和内存使用:

图 6 展示了一个 java.util.HashSet 对象的 shallow 堆(独立对象的内存使用)以及保留堆(独立对象及其子对象的内存使用),以字节为单位。shallow 堆的大小是 16 字节,保留堆的大小是 144 字节。创建一个 HashSet 时,其默认容量(也就是该集中可以容纳的条目数量)将设置为 16 个条目。按照默认容量创建 HashSet,而且未在该集中输入任何条目时,它将占用 144 个字节。与 HashMap 的内存使用相比,超出了 16 个字节。表 2 显示了 HashSet 的属性:
| 默认容量 | 16 个条目 |
|---|---|
| 空时的大小 | 144 个字节 |
| 开销 | 16 字节加 HashMap 开销 |
| 一个 10K 集合的开销 | 16 字节加 HashMap 开销 |
| 搜索/插入/删除性能 | O(1):所用时间是一个常量时间,无论要素数量如何都是如此(假设无散列冲突) |
HashMap 是 Map 接口的实现。Java Platform SE 6 API 文档对于 HashMap 的描述如下:
一个将键映射到值的对象。一个映射中不能包含重复的键;每个键仅可映射到至多一个值。
HashMap 提供了一种存储键/值对的方法,使用散列函数将键转换为存储键/值对的集合中的索引。这允许快速访问数据位置。允许存在空条目和重复条目;因此,HashMap 是 HashSet 的简化版。
HashMap 将实现为一个 HashMap$Entry 对象数组。图 7 展示了 32 位 Java 运行时中的一个 HashMap 的内存使用和布局:

如 图 7 所示,创建一个 HashMap 时,结果是一个 HashMap 对象以及一个采用 16 个条目的默认容量的 HashMap$Entry 对象数组。这提供了一个 HashMap,在完全为空时,其大小是 128 字节。插入 HashMap 的任何键/值对都将包含于一个 HashMap$Entry 对象之中,该对象本身也有一定的开销。
大多数 HashMap$Entry 对象实现都包含以下字段:
一个 32 字节的 HashMap$Entry 对象用于管理插入集合的数据键/值对。这就意味着,一个 HashMap 的总开销包含 HashMap 对象、一个HashMap$Entry 数组条目和与各条目对应的 HashMap$Entry 对象的开销。可通过以下公式表示:
HashMap 对象 + 数组对象开销 + (条目数量 * (HashMap$Entry 数组条目 + HashMap$Entry 对象))
对于一个包含 10,000 个条目的 HashMap 来说,仅仅 HashMap、HashMap$Entry 数组和 HashMap$Entry 对象的开销就在 360K 左右。这还没有考虑所存储的键和值的大小。
表 3 展示了 HashMap 的属性:
| 默认容量 | 16 个条目 |
|---|---|
| 空时的大小 | 128 个字节 |
| 开销 | 64 字节加上每个条目 36 字节 |
| 一个 10K 集合的开销 | ~360K |
| 搜索/插入/删除性能 | O(1):所用时间是一个常量时间,无论要素数量如何都是如此(假设无散列冲突) |
Hashtable 与 HashMap 相似,也是 Map 接口的实现。Java Platform SE 6 API 文档对于 Hashtable 的描述如下:
这个类实现了一个散列表,用于将键映射到值。对于非空对象,可以将它用作键,也可以将它用作值。
Hashtable 与 HashMap 极其相似,但有两项限制。无论是键还是值条目,它均不接受空值,而且它是一个同步集合。相比之下,HashMap 可以接受空值,且不是同步的,但可以利用 Collections.synchronizedMap() 方法来实现同步。
Hashtable 的实现同样类似于 HashMap,也是条目对象的数组,在本例中即 Hashtable$Entry 对象。图 8 展示了 32 位 Java 运行时中的一个 Hashtable 的内存使用和布局:

图 8 显示,创建一个 Hashtable 时,结果会是一个占用了 40 字节的内存的 Hashtable 对象,另有一个默认容量为 11 个条目的Hashtable$entry 数组,在 Hashtable 为空时,总大小为 104 字节。
Hashtable$Entry 存储的数据实际上与 HashMap 相同:
这意味着,对于 Hashtable 中的键/值条目,Hashtable$Entry 对象也是 32 字节,而 Hashtable 开销的计算和 10K 个条目的集合的大小(约为 360K)与 HashMap 类似。
表 4 显示了 Hashtable 的属性:
| 默认容量 | 11 个条目 |
|---|---|
| 空时的大小 | 104 个字节 |
| 开销 | 56 字节加上每个条目 36 字节 |
| 一个 10K 集合的开销 | ~360K |
| 搜索/插入/删除性能 | O(1):所用时间是一个常量时间,无论要素数量如何都是如此(假设无散列冲突) |
如您所见,Hashtable 的默认容量比 HashMap 要稍微小一些(分别是 11 与 16)。除此之外,两者之间的主要差别在于 Hashtable 无法接受空键和空值,而且是默认同步的,但这可能是不必要的,还有可能降低集合的性能。
LinkedList 是 List 接口的链表实现。Java Platform SE 6 API 文档对于 LinkedList 的描述如下:
一种有序集合(也称为序列)。此接口的用户可以精确控制将各元素插入列表时的位置。用户可以按照整数索引(代表在列表中的位置)来访问元素,也可以搜索列表中的元素。与其他集合 (set) 不同,该集合 (collection) 通常允许存在重复的元素。
实现是 LinkedList$Entry 对象链表。图 9 展示了 32 位 Java 运行时中的 LinkedList 的内存使用和布局:

图 9 表明,创建一个 LinkedList 时,结果将得到一个占用 24 字节内存的 LinkedList 对象以及一个 LinkedList$Entry 对象,在LinkedList 为空时,总共占用的内存是 48 个字节。
链表的优势之一就是能够准确调整其大小,且无需重新调整。默认容量实际上就是一个条目,能够在添加或删除条目时动态扩大或缩小。每个LinkedList$Entry 对象仍然有自己的开销,其数据字段如下:
但这比 HashMap 和 Hashtable 的开销低,因为链表仅存储单独一个条目,而非键/值对,由于不会使用基于数组的查找,因此不需要存储散列值。从负面角度来看,在链表中查找的速度要慢得多,因为链表必须依次遍历才能找到需要查找的正确条目。对于较大的链表,结果可能导致漫长的查找时间。
表 5 显示了 LinkedList 的属性:
| 默认容量 | 1 个条目 |
|---|---|
| 空时的大小 | 48 个字节 |
| 开销 | 24 字节加上每个条目 24 字节 |
| 一个 10K 集合的开销 | ~240K |
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

