
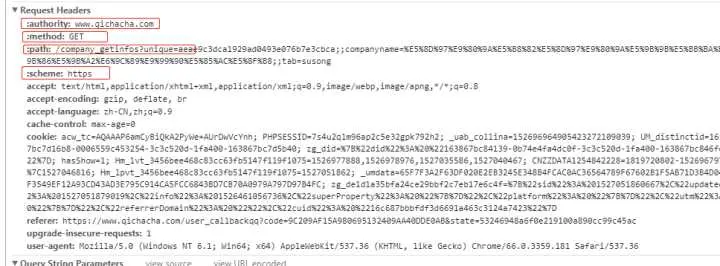

如上图所示:这样的请求头有一部分前面有冒号,不去冒号用requests会报错,去掉冒号,爬取的内容是错误的,问下该怎么写这样的请求头?要爬取的网址是“https://www.qichacha.com/search?key=南通四建集团有限公司”。初学python的小白,请多多关照,,谢谢!
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Python中使用requests库发送HTTP请求时,请求头(headers)应该是一个字典类型,其中每个键值对都不包含冒号。如果你看到的请求头示例中带有冒号,那是因为在网络抓包或文档展示时,冒号用于分隔键和值。实际上构造请求头时,你应该直接提供键值对,无需包含冒号。
针对你提供的网址“https://www.qichacha.com/search?key=南通四建集团有限公司”,如果你想自定义请求头进行爬取,可以按照以下方式编写代码:
import requests
url = "https://www.qichacha.com/search?key=南通四建集团有限公司"
# 正确构造请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3",
# 可以根据需要添加其他头部信息,如Referer等
}
response = requests.get(url, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
content = response.text
print(content)
else:
print("请求失败,状态码:", response.status_code)
这段代码中,headers字典包含了请求头信息,其中"User-Agent"是模拟浏览器的一种常见用法,用来告诉服务器你是通过哪种浏览器访问的。你可以根据实际需求添加更多头部信息,但注意保持键值对格式,不要包含冒号。
请确保你的环境已经安装了requests库,如果没有安装,可以通过运行pip install requests命令来安装。
