
问题详细描述:
在最近的netty项目中,我做了一个心跳机制
服务端监听了读空闲(间隔为20秒一次),在触发读空闲的时候,服务端需要向客户端写一个心跳数据包,并累计空闲次数,如果超过3次,就认为客户端失连;
客户端收到服务端的心跳消息后,会回写一个心跳包给服务端,服务端收到消息后,会将该客户端的空闲次数清0
在测试的时候,客户端连上服务器几秒后,断开客户端的网络,服务端会开始执行读空闲的逻辑,当服务端执行两次读空闲后,我启动客户端的网络,这个时候,服务端就会出现一个异常:
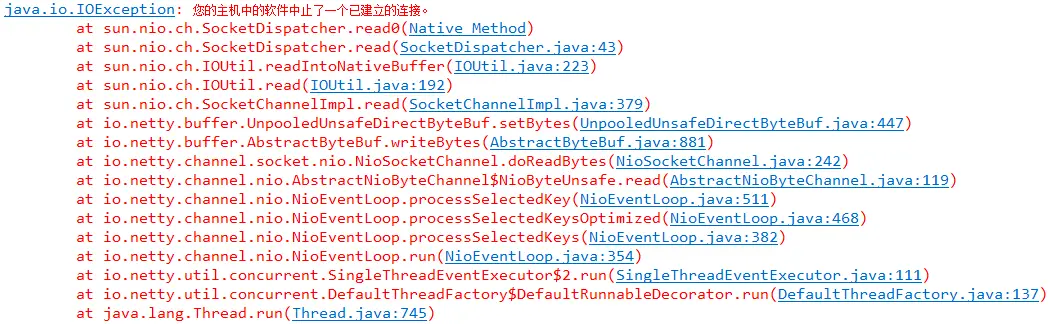
但是服务端只执行一次读空闲写心跳包的时候,客户端启动网络,是没有问题的,求大神指点
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
遇到您描述的问题,可能涉及到几个方面的原因,包括但不限于网络连接恢复后的状态同步、Netty的Channel管理以及心跳机制的实现细节。以下是一些建议和排查方向:
Channel状态检查:当客户端网络断开后重新连接时,服务端可能没有正确识别到这个变化,导致对已失效的Channel进行写操作。在发送心跳包之前,确保通过channel.isActive()或channel.isWritable()等方法检查Channel是否处于活动且可写状态。
资源清理:在触发读空闲并尝试写入心跳包时,如果发现Channel已经不可用(例如因为网络中断),应该有逻辑去关闭或移除这个Channel,避免后续继续向无效的Channel发送数据。同时,确保在客户端重连时能够创建新的Channel并与之通信。
异常处理:您提到的异常具体是什么?通常,对于网络操作,特别是写操作,应当有完善的异常捕获和处理逻辑,比如通过try-catch块捕获IOException或WriteException,并在捕获异常后采取适当的措施,如关闭Channel、记录日志或重试等。
心跳逻辑优化:考虑在客户端和服务端的心跳逻辑中增加更多的状态标识,比如在服务端记录除了空闲次数外,还可以记录上一次心跳响应的状态,以更精确地判断客户端是否真的失联。
Netty配置调整:检查Netty的配置,特别是与连接超时、写缓冲区大小、重连策略相关的设置,确保它们适合您的应用场景。有时候,不恰当的配置会导致意外的行为,比如写缓冲区满导致写操作失败。
调试与日志:增强日志输出,特别是在心跳处理、Channel状态变更、异常处理等关键环节,这有助于追踪问题的具体发生位置和原因。
客户端重连逻辑:确认客户端在断网后重新连接时,是否正确实现了重连逻辑,包括但不限于关闭旧的连接、建立新的连接通道,并且在连接成功后能够正常响应服务端的心跳请求。
综上所述,建议从这些角度出发,逐步定位并解决问题。希望这些建议能帮助您解决当前遇到的难题。
