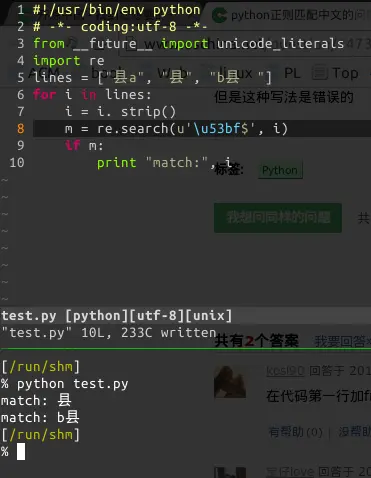
比方说我要匹配某个中文string含有"县"这个字
代码如下:
#!/usr/bin/python # -*- coding: utf-8 -*- for i in lines: i = i.strip() m = re.search(u'\u53bf',i) if m: print i但如果添加变成是匹配是以"县"字结尾的中文string,这个时候这个正则该怎么写呢?我试过这样写,但是这种写法是错误的
re.search(u'\u53bf$',i)
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。