
新手实验storm-hive插件的使用遇到下面的问题:


代码:
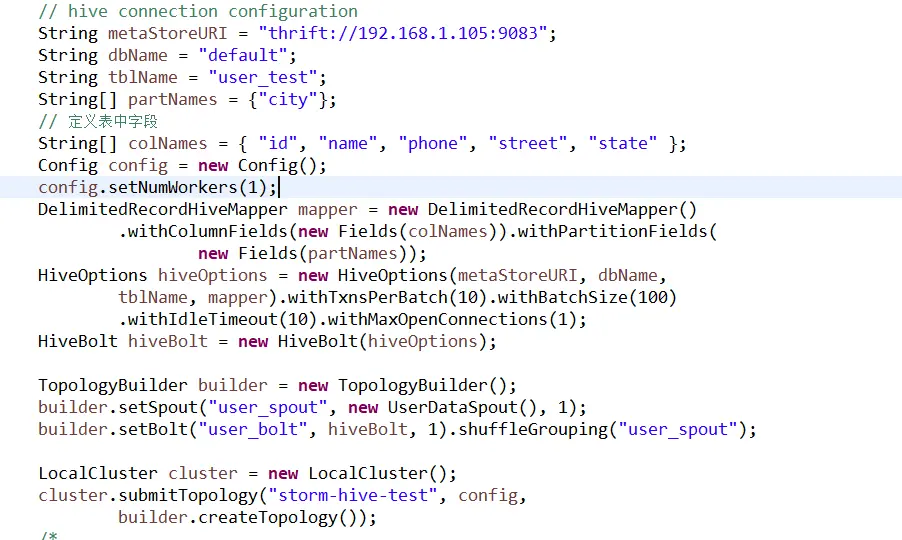
连接的远程集群,结果,创建文件却在本地计算机,请问该怎么修改呢?
重新建立maven项目后,运行topo
报错:
java.lang.RuntimeException: The root scratch dir: /tmp/hive on HDFS should be writable. Current permissions are: ---------
at org.apache.hadoop.hive.ql.session.SessionState.createRootHDFSDir(SessionState.java:690) ~[hive-exec-2.1.0.jar:2.1.0]
at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:622) ~[hive-exec-2.1.0.jar:2.1.0]
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:550) ~[hive-exec-2.1.0.jar:2.1.0]
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:513) ~[hive-exec-2.1.0.jar:2.1.0]
at org.apache.hive.hcatalog.streaming.HiveEndPoint$ConnectionImpl.createPartitionIfNotExists(HiveEndPoint.java:445) ~[hive-hcatalog-streaming-2.1.0.jar:2.1.0]
at org.apache.hive.hcatalog.streaming.HiveEndPoint$ConnectionImpl.<init>(HiveEndPoint.java:314) ~[hive-hcatalog-streaming-2.1.0.jar:2.1.0]
at org.apache.hive.hcatalog.streaming.HiveEndPoint$ConnectionImpl.<init>(HiveEndPoint.java:278) ~[hive-hcatalog-streaming-2.1.0.jar:2.1.0]
at org.apache.hive.hcatalog.streaming.HiveEndPoint.newConnectionImpl(HiveEndPoint.java:215) ~[hive-hcatalog-streaming-2.1.0.jar:2.1.0]
at org.apache.hive.hcatalog.streaming.HiveEndPoint.newConnection(HiveEndPoint.java:192) ~[hive-hcatalog-streaming-2.1.0.jar:2.1.0]
at org.apache.hive.hcatalog.streaming.HiveEndPoint.newConnection(HiveEndPoint.java:122) ~[hive-hcatalog-streaming-2.1.0.jar:2.1.0]
at org.apache.storm.hive.common.HiveWriter$5.call(HiveWriter.java:229) ~[storm-hive-0.10.0.jar:0.10.0]
at org.apache.storm.hive.common.HiveWriter$5.call(HiveWriter.java:226) ~[storm-hive-0.10.0.jar:0.10.0]
at org.apache.storm.hive.common.HiveWriter$9.call(HiveWriter.java:332) ~[storm-hive-0.10.0.jar:0.10.0]
at java.util.concurrent.FutureTask.run(FutureTask.java:262) ~[?:1.7.0_80]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) ~[?:1.7.0_80]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) ~[?:1.7.0_80]
at java.lang.Thread.run(Thread.java:745) [?:1.7.0_80]
**** RESENDING FAILED TUPLE
24347 [hive-bolt-0] INFO o.a.h.h.q.Driver - Compiling command(queryId=Administrator_20170906152102_275e25b7-8d79-4f0b-a449-3128b4e7fbee): use default
FAILED: NullPointerException Non-local session path expected to be non-null
文件本应在 /user/hive/warehoouse/ 下
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
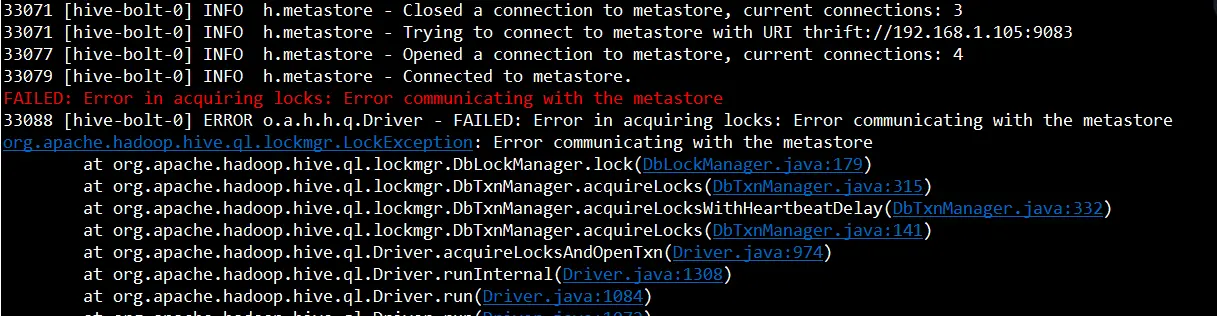
FAILED:Errorinacquiringlocks:Errorcommunicatingwiththemetastore
14:20:20.090[hive-bolt-0]ERRORorg.apache.hadoop.hive.ql.Driver-FAILED:Errorinacquiringlocks:Errorcommunicatingwiththemetastore
org.apache.hadoop.hive.ql.lockmgr.LockException:Errorcommunicatingwiththemetastore
Causedby:org.apache.thrift.TApplicationException:Internalerrorprocessinglock
14:20:20.540[Thread-8-user_bolt]ERRORcom.test.bolt.HiveBolt-FailedtocreateHiveWriterforendpoint:{metaStoreUri='thrift://192.168.1.105:9083',database='default',table='user_test10',partitionVals=[sunnyvale]}
com.test.common.HiveWriter$ConnectFailure:FailedconnectingtoEndPoint{metaStoreUri='thrift://192.168.1.105:9083',database='default',table='user_test10',partitionVals=[sunnyvale]}
Causedby:org.apache.hive.hcatalog.streaming.StreamingException:partitionvalues=[sunnyvale].Unabletogetpathforendpoint:[sunnyvale]
