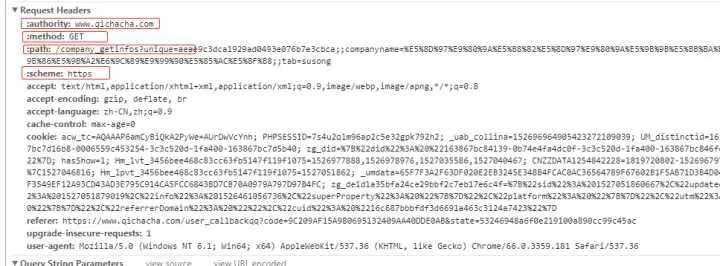

如上图所示:这样的请求头有一部分前面有冒号,不去冒号用requests会报错,去掉冒号,爬取的内容是错误的,问下该怎么写这样的请求头?要爬取的网址是“https://www.qichacha.com/search?key=南通四建集团有限公司”。初学python的小白,请多多关照,,谢谢!
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
<p>你在浏览器看到的这种带冒号的请求头,是因为浏览器与服务器之间使用的是HTTP2协议。走不走HTTP2是可选的,即客户端不支持HTTP2时就不会使用HTTP2协议进行交互。所以,你只需要考虑按照正常的https请求来交互即可。 之所以会得到405,是因为服务端有安全策略检测的。我初步分析,应该是与cookie中的信息有关。</p>
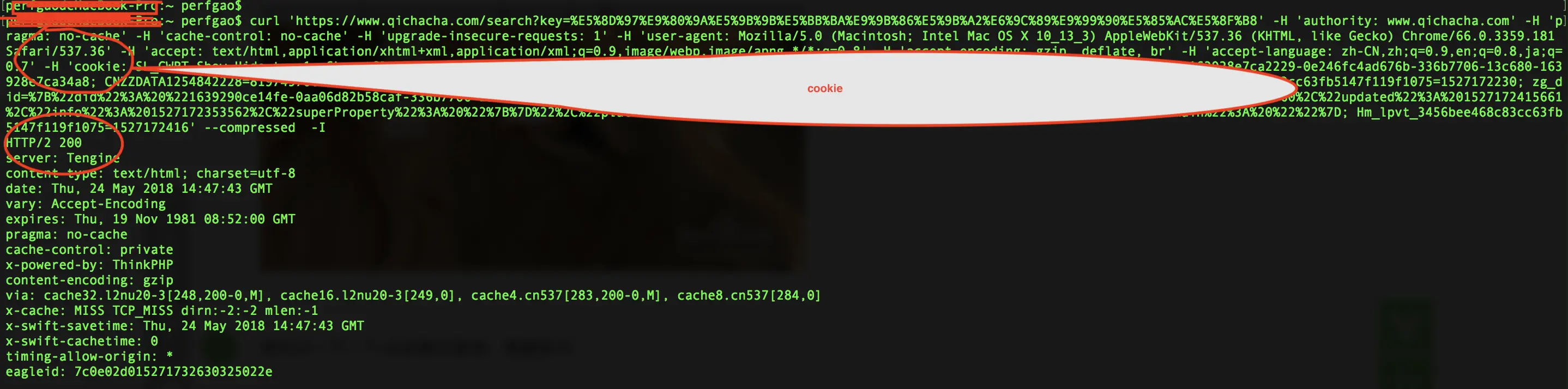

回复 <a class="referer" target="_blank">@北国之秋秋</a> : 尽量模拟正常的用户请求。有两点需要注意,1. 请求的User-Agent要模拟为正常浏览器的;2. 要携带cookie信息。
哥,我想知道该如何解决啊??谢谢!
<p>这里我给你一个实例,你看下:</p>
# coding=utf-8
import requests
def test():
head = {
"User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36"
}
payload = {
"key": "小米"
}
s = requests.Session()
s.get("https://www.qichacha.com/", headers = head)
s.headers.update(head)
r = s.get("https://www.qichacha.com/search", params=payload)
print(r)
print(r.text)输出: