
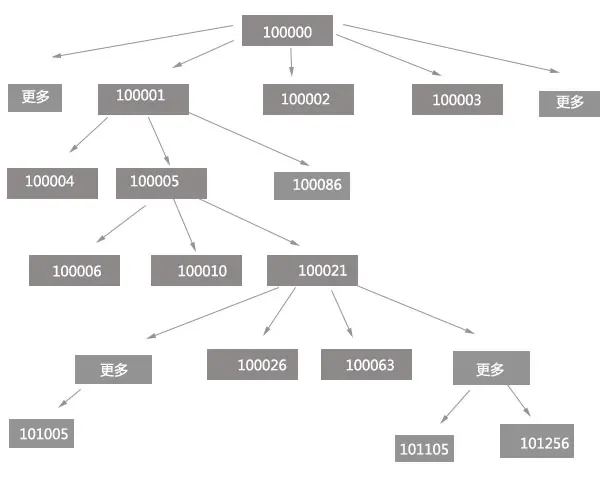
以上是结构图,现有数据库只有两个字段,如:uid和tid,假设我目前的uid是100001,我发展了三个会员,但是我的其中一个会员100005他 发展了三个,但不一定是三个,目前想要统计出我是100001下面有多少,包括树下所有人,统计100021下面有多少人,还有怎么把这个树表达出来,由 于个人能有限,请各位大神给予帮助,写出相应的算法!还有就是输入一个ID可以把我下面的所有人员都列出来,这个怎么实现,数据库当时设计只有这两个字段。更改是不是有困难!
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
http://blog.csdn.net/MONKEY_D_MENG/article/details/6647488
基于左右值编码的Schema设计
不改结构只能递归了.
######求写法!######
如果不考虑性能的话,可以使用一个 递归 去获取所有。当然,每次执行起来就会变得非常慢了。
在现有表中添加一个 child 的字段,用于记录 子层的发展。每一个子层进行更改,程序都对上层的父进行记录和修改。
这样要用到的时候,直接填写ID,查对应的 记录就行了。
-----
另外一个方法就是 对遍历过的 整个 进行 缓存处理,打包成成品。 只要涉及到修改,就更新缓存。这是在不改表结构,用算法去实现。
估计写存储过程可以,不过我不会写
如果要调整表的结构,可以参考我的博文(只有思路,没有实现):
http://my.oschina.net/u/1382972/blog/225211
######http://segmentfault.com/q/1010000000126370
###### 见https://my.oschina.net/drinkjava2/blog/828781
只需要利用行号(已排序)和深度两个额外字段(加上尾部的结束标记),即可以高效地实现SQL子树、父子节点的查询/删除/插入操作,缺点是节点的移动操作不太方便,适用于只增减,不常移动节点的场合。

