
开通MaxCompute服务,如何根据本身数据存储量以及计算任务评估开通哪些产品规格?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
新用户建议开通MaxCompute按量付费版本,存储和下载都是按量付费,正式跑一段时间之后再评估是否需要变换产品规格。
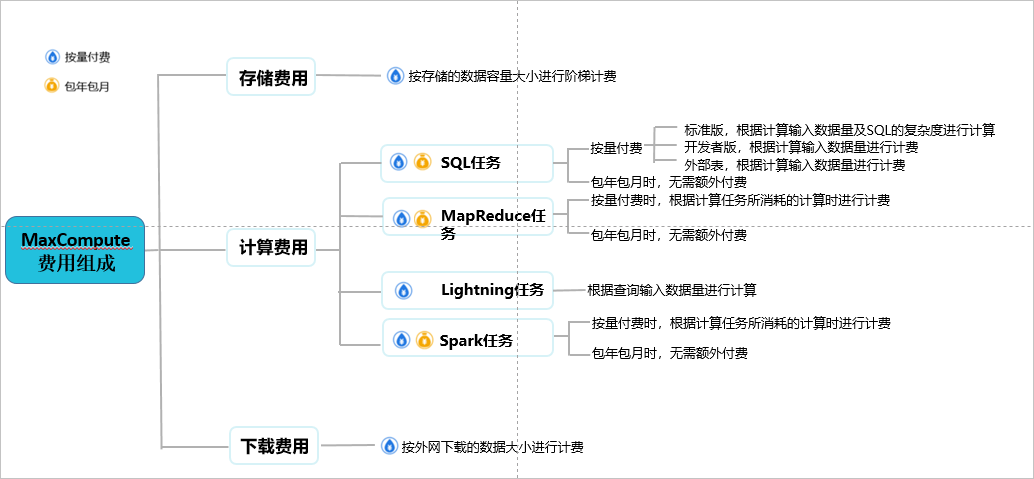
MaxCompute对存储、计算、下载操作进行计量计费。本文向您介绍如何选择MaxCompute按量计费和包年包月两种购买方式,以及如何进行初步的成本估算。
MaxCompute中,计量计费项如下所示。
包年包月:此方式仅在阿里云大数据计算服务提供,包括SQL、MapReduce等计算任务
说明 如果您选择包年包月,MaxCompute会为您预留所购买的资源。我们将此种资源的基本单位定义为CU(Compute Unit),1CU包含的计算资源为4GB内存、1核CPU。以TPC-DS标准对1TB大小的数据集进行性能测试,数据表明如果您使用MaxCompute 160CU,则执行TPC-DS的99个SQL任务,平均每个任务约需要5分钟。您可以参考上述数据用于CU购买量估算。
说明 若您担心按量计费项目每天消费过高,可以通过云监控配置消费监控告警,按Project粒度配置SQL、MR每日消费总额上限告警,及时获悉当日SQL、MR的累计消费,以便及时介入检查任务是否正常。具体告警配置请参见监控报警。
结算说明:账单以Project(项目空间)为单位统计,结算周期为天。
报价速算器:MaxCompute报价速算器下载。
有关计量计费的详细计算方式,请参见查看账单详情。
计费常见问题请参见计量计费常见问题。
MaxCompute提供按量计费和包年包月两种计算计费方式。
说明 如果您是新用户,建议您先采用按量计费的方式进行结算。初期使用MaxCompute时,消耗的资源较少,采购CU预留资源会导致资源闲置。相对而言,按量计费方式成本会更低。
通常,针对同一业务创建两个项目。 您也可以通过创建DataWorks标准模式工作空间(详细请参见创建工作空间),自动生成两个项目:
- 开发项目:通常用于工程师开发调试,作业随机性大,数据量小。建议您使用CU包年包月模式,它能够帮您有效控制成本,将资源消耗控制在一定范围内。
- 生产项目:您的作业相对稳定(经过开发调试再上线),可以考虑使用按量计费模式,以避免资源闲置。
目前MaxCompute开放的计算任务类型有SQL、UDF、MapReduce、Graph、 Lightning(交互式分析)、Spark和机器学习作业。目前对SQL(不包含UDF)、MapReduce、PyODPS任务、 Lightning(交互式分析)和Spark计算任务进行收费,其他类型的作业暂不收费。PyODPS任务底层执行的是SQL任务,费用参考SQL的计量计费逻辑。
在估算存储成本时,请您特别注意MaxCompute采用压缩存储,通常能压缩到原文件大小的1/5 。MaxCompute存储按照压缩后的大小计费。估算结果仅供参考,实际结果请以账单为准。
通常情况下,每个进程占用1个CU的资源。如果您采购了10个CU,而提交的作业需要100个进程并发,则这个作业会被分成10轮进行,每一轮10个进程,每个进程占用1个CU的资源。
MaxCompute为您提供调整每个进程占用内存的能力。详情请参见Cost SQL。
欢迎扫码加入 MaxCompute开发者社区钉钉群,或点击申请加入。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


