
纯requests手撸模拟登录(嫌理论过长可直接拉到中部看代码)
在这里做个小对比,因为selenium无情抛弃了PhantomJS,所以导致selenium在一开始处理请求的速率大大下降;
但是,的确是一个万能工具,就跟机器一样去帮你点击,成功率可是百分百(我目前是没失败过)
所以初学的小伙伴可以先去学习一下selenium自动化工具之后在专精,因为在用的时候你会涉及一些正则和css选择器、html、js之类打交道;可以为你之后的学习打一个很好的基础
下面开始正式讲解一下requests
建议先从小例子下手:
requests官文讲解一下几个我们会用到的地方:
1、浏览器的debug模式
这个功能和你在用IDE的时候是一样的,可以帮你一层层的解析网页数据的处理和找到最后的入口在哪里
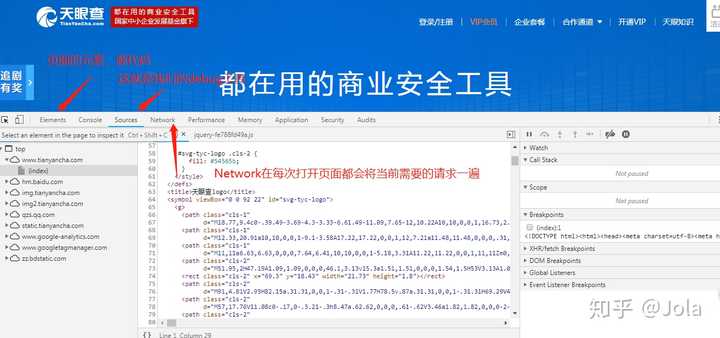

如上图所示,首先我们应该是打开network粗略的浏览一下
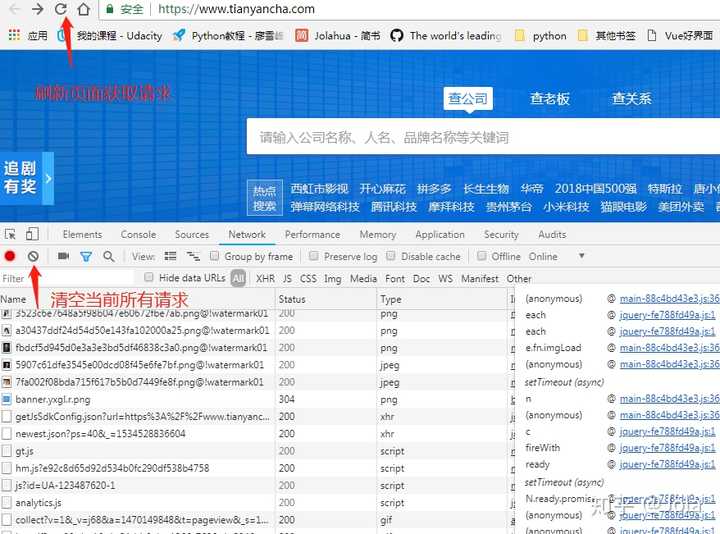
接着看咱们和主页相关的Url,一般为get请求;像图片,css,js一开始可以先忽略掉
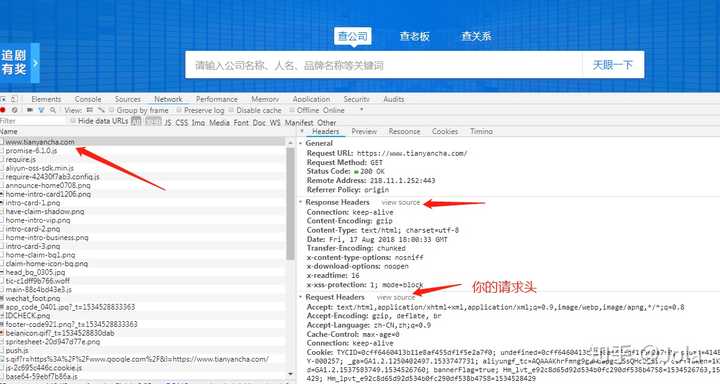
因为用的是笔记本,所以稍微缩小了一下
这里我们看向右侧,其中一个是你的请求,另一个是服务端响应你的请求而制作的头信息
之后咱们模拟一下这个主页请求,首先弄清他的所有格式和数据
然后我们开始写一个简单的代码请求一下主页
import requestsresult = requests.get('https://www.tianyancha.com/', verify=False) print(result) print(result.cookies)
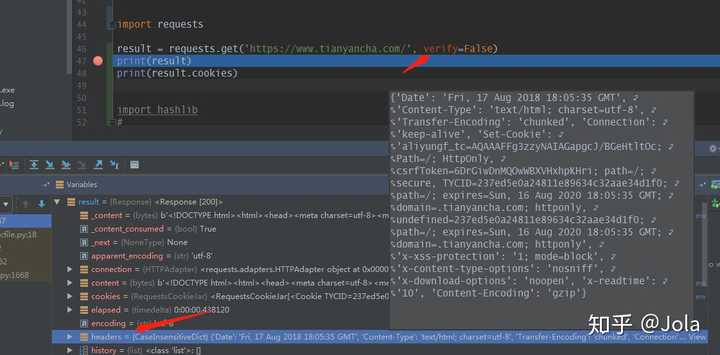
上面的箭头所指的verify指的是是否验证TLS证书,一般都是对 https 网页做验证
这里我们设置为false是为了避开,有的网站需要证书的时候会要用到cert参数
下面是官文解释
verify: (optional) Either a boolean, in which case it controls whether we verify
the server's TLS certificate, or a string, in which case it must be a path
to a CA bundle to use. Defaults to ``True``.
这里我用的是debug模式,方便我们观察;大家也记得打个断点让他停下来,然后观察到我们的header,这个就是网站返回给我们的信息,这里看到的数据和网页没差
一般来说,我们关注的是cookie和一些特定的get请求返回的数据
经过分析是需要cookie的,可以回看上一张图片,在请求的时候已经加上了cookie,是因为我访问过,所以本地有存储,如果我们第一次访问可以直接copy我的代码,请求之后去获取他的cookie,并把返回的信息存下来,用作之后的请求使用
好晚了 暂时先更新着思路 一般我们要要登录的网站,在登录之后这个请求都会消失不见,会不会很神秘

所以,我们第一次都可以先输入一个错误的密码去获取他的链接(阴险脸.jpg)
这里我用错误代码去请求马上获取到了他的url和要传送的数据
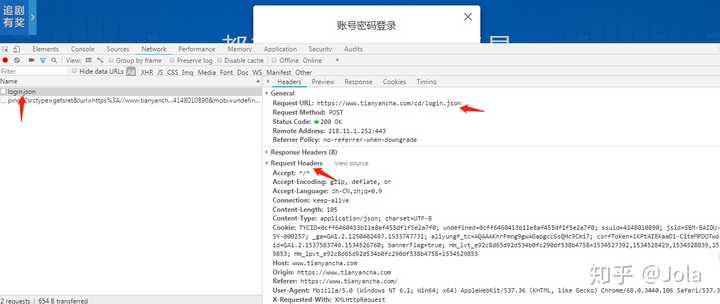
而这里的cookie信息就是我们一开始打开网页获取到的cookie信息,我们在点击登录之前可以先点击左边箭头上面红色小点隔壁的灰色小点清空以方便我们观察
之后我们就可以愉快的发送请求了
#!/usr/bin/python
# -*- coding:utf-8 -*-
# author: Jola
# CreateTime: 2018/8/2 19:47
# software-version: python 3.6
import requests
import json
import hashlib
Phone = '******'
Password = '******'
h1 = hashlib.md5()
h1.update(Password.encode('utf-8'))
PasswordMd5 = h1.hexdigest()
def post_url():
url = 'https://www.tianyancha.com/cd/login.json'
header = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '105',
'Content-Type': 'application/json; charset=UTF-8',
'Cookie': '*********************************',
'Host': 'www.tianyancha.com',
'Origin': 'https://www.tianyancha.com',
'Referer': 'https://www.tianyancha.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3'
'396.99 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
login_info = {
'autoLogin': 'true',
'cdpassword': PasswordMd5,
'loginway': 'PL',
'mobile': Phone
}
result = requests.post(url, data=json.dumps(login_info), headers=header, verify=False)
print(result)
print(result.content)
print(result.text)
return eval(result.text)['data']['token']之后就可以获取到一组token数据,而这一串呢,在你登录之后的请求当中,也是需要加到你的token里面去的,具体放在哪里大家可以自己登陆网页之后看一下网页放在cookie哪个位置。
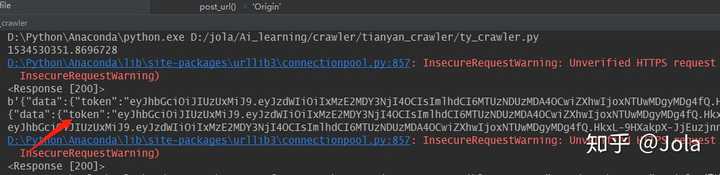
这一串应该是一个JWT格式的token,这可是你的凭证,如果要做成接口给别人访问要注意安全问题哦!
先更成这样吧,有需求再回来补~困了。。。顺便祝大家七夕快乐~!
更1:selenium + firefox 模拟登陆
python安装和环境配置我就不累述了,网上一大堆教程
话不多说 直接上爬虫代码
#!/usr/bin/python
# -*- coding:utf-8 -*-
# author: Jola
# CreateTime: 2018/2/26 19:47
# software-version: python 3.6
import time
from selenium import webdriver
from selenium.webdriver import Firefox
class GetCompanyInfo(object):
"""
爬取天眼查下的企业的信息
"""
def __init__(self):
"""
初始化爬虫执行代理,使用firefox访问
"""
self.username = '******' # 填写自己的账号
self.password = '******' # 填写账号的密码
self.options = webdriver.FirefoxOptions()
self.options.add_argument('-headless') # 无头参数
self.geckodriver = r'geckodriver.exe'
self.driver = Firefox(executable_path=self.geckodriver, firefox_options=self.options)
self.start_url = 'https://www.tianyancha.com'简要解释一下:整个爬虫的初始化
self.options设置加载使用Firefox作为驱动,并且设为无头模式
self.geckodriver是一个最重要的driver文件,整个爬虫都以他为驱动运行,可以把他当做一个承载浏览器的插件。当你运行代码的时候你可以打开你的任务管理器,会发现每开启一个都会有一个Firefox进程。
self.driver 这个则是将其应用Firefox和driver绑定,之后的操作都将在这里完成,比如:点击事件、页面的源码获取等等
def index_login(self):
"""
主页下的登录模式
:return:
"""
get_login = self.driver.find_elements_by_xpath('//a[@class="link-white"]')[0] # 登录/注册
print(get_login.text)
# url为login的input
get_login.click()
login_by_pwd = self.driver.find_element_by_xpath('//div[@class="bgContent"]/div[3]/div[2]/div') # 切换到手机登录
login_by_pwd.click()
input1 = self.driver.find_element_by_xpath('//div[@class="bgContent"]/div[3]/div[1]/div[2]/input') # 手机号码
input2 = self.driver.find_element_by_xpath('//div[@class="bgContent"]/div[3]/div[1]/div[3]/input') # 密码
print(input1.get_attribute('placeholder'))
print(input2.get_attribute('placeholder'))
username, password = self._check_user_pass()
input1.send_keys(username)
input2.send_keys(password)
login_button = self.driver.find_element_by_xpath('//div[@class="bgContent"]/div[3]/div[1]/div[5]') # 点击登录
print(login_button.text)
time.sleep(1) # 等待否则鉴别是爬虫
login_button.click()
return True这个方法主要就是进行登录的操作,简洁的说其实模拟用户点击页面的过程,之后将个人账号密码输入到对应的区域,点击登录。
xpath:我个人是觉得这种用法很便捷,但是没必要专门去学习,当你用到的时候在去google一下就好,随着你个人能力提升,你用到的方法也会越来越多,不是专门走前端的没必要刻意去学习
这里有好几种方式 css选择器、xpath选择器、driver自带的选择器。依个人爱好选择。内容几乎差不多
接下来讲讲我整个分析的过程
1、查看天眼查的主页代码:
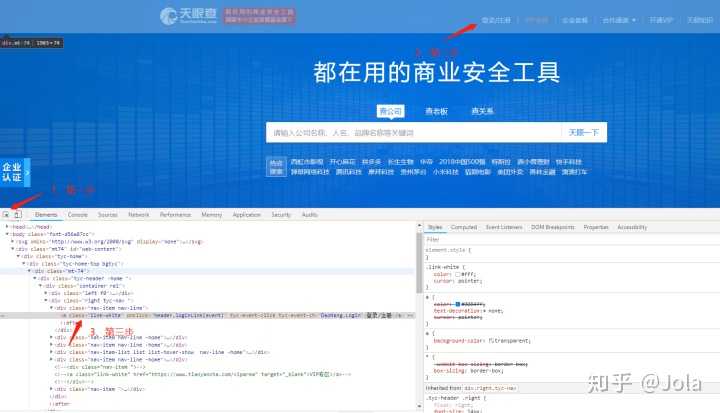
进到天眼查主页,打开开发者工具(按F12);个人使用的是google
2、之后按图中所示,先点击element选择器,之后移动到 登录/注册 的位置,下面的html代码就会自动定位到所在地方,这里我们看到这是一个a标签,然后在element里面搜索一下
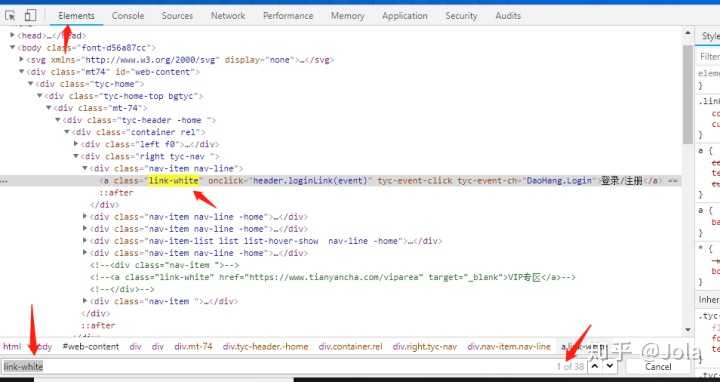
发现其实这个class的第一个,就是我们login的第一个行代码
get_login = self.driver.find_elements_by_xpath('//a[@class="link-white"]')[0] 这里的xpath意思是 //a 表示整个页面下 搜寻a标签 这里的a标签就是
@class则是搜寻样式为 "***" 的a标签 最后的[0] 则对应图上的右下角箭头,程序中是从0开始计数,第一个则是取[0], 如果我们是第12个 则是[11]
3、模拟登录
现在我们取到了 登录/注册 这个a标签 并且当我们在页面的时候是可以点击的,然后代码中我们模拟点击,也就是click事件
get_login.click()
# 获取输入账号的input框
input1 = self.driver.find_element_by_xpath('//div[@class="bgContent"]/div[3]/div[1]/div[2]/input') # 手机号码
# 获取输入密码的input框
input2 = self.driver.find_element_by_xpath('//div[@class="bgContent"]/div[3]/div[1]/div[3]/input') # 密码
# 模拟输入账号密码
input1.send_keys(username)
input2.send_keys(password)然后我们切换到用账号密码登录的模式,之后呢,就开始进行输入账号密码进行登录了
这里的 input.send_keys(username) 就是将你在初始化输入的账号密码模拟输入到input框里,然后点击登录
到此 登录功能暂且完成
整体代码在下面自取
链接: https://pan.baidu.com/s/1FtdWQDsgosPTGdM5w9FLuA 密码: wxp2
requests 有机会再更新了

无意间看到这个问题…过两天来更新
零起步教学 分两种爬取方式:
1、selenium + firefox或者谷歌 模拟登录后爬取(最新版本不支持phjs了)
2、单纯request模拟登录获取token访问
第一种呢 比较慢 但是绝对能爬取
第二种秒级反应并可以通过一个token连续爬取
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
