
分布式文件系统的背景是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
分布式文件系统,无论是 Lustre、GlusterFS、OrangeFS、BeeGFS、XtreemFS 还是之前的 Ceph,都有几个关键需求:
高效的事务
快速的元数据操作
(可能不是通用的)对未来的不向后兼容的存储硬件的支持
因为大部分文件系统按 POSIX 标准实现,因此缺乏事务概念,因此分布式文件系统往往通过 WAL 或者基于文件系统的内部事务机制实现(Lustre)。
无法高效的列举目录内容或者 hanle 海量小文件也是分布式存储使用本地文件系统的一个痛点,为此分布式文件系统就需要通过元数据缓存、哈希、数据库或对本地文件系统打 patch 来解决。
根据硬件供应商的预测,2023 年半数的数据中心将使用 SMR HDD。此外 ZNS SSD 能够通过不提供 FTL 来避免 gc 带来的不可控的延迟。像这种新硬件也是 Ceph 希望支持的。
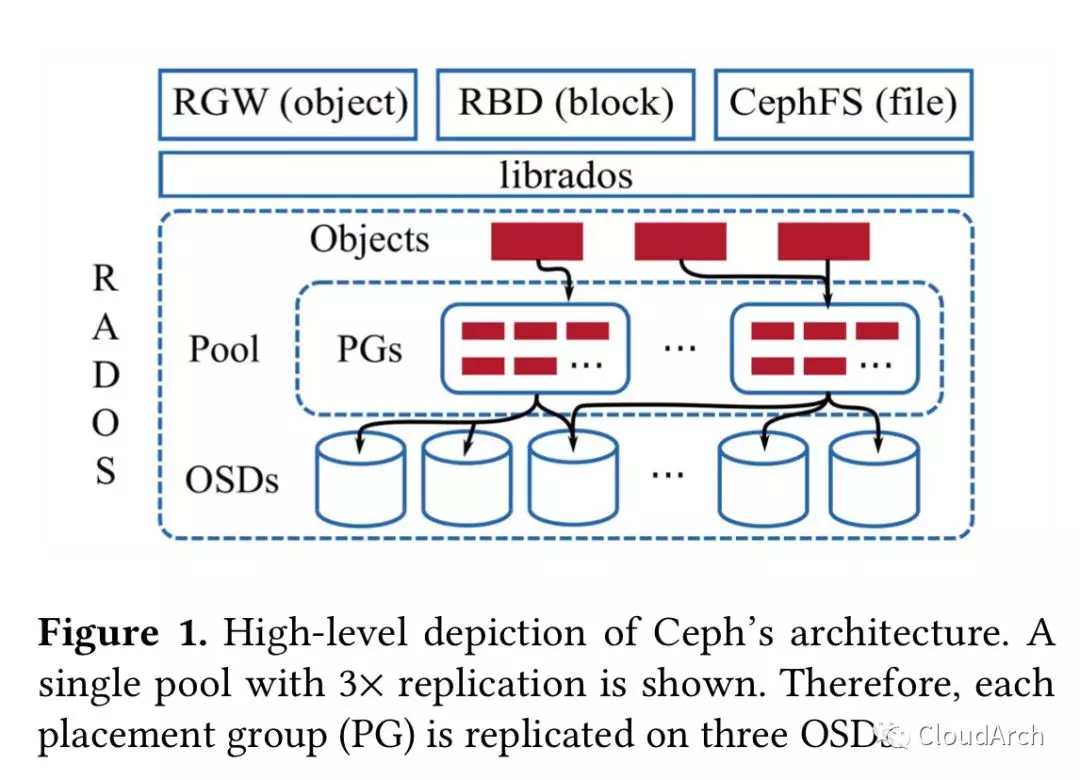 上图是 Ceph 的大致架构,考虑到 Ceph 架构的介绍文章很多,这里就赘述了,读者可以搜索任一篇 Ceph 架构的介绍文章。
上图是 Ceph 的大致架构,考虑到 Ceph 架构的介绍文章很多,这里就赘述了,读者可以搜索任一篇 Ceph 架构的介绍文章。
Ceph 的 ObjectStore 第一个实现是一个叫 EBOFS(Extent and B-Tree-based Object File System ) 的用户态文件系统。2018 年 Btrfs 出现,有事务、去重、校验码、透明压缩都特性,因此 EBOFS 被基于 Btrfs 实现的 FileStore 取代。
FileStore 里,一个对象集合会被映射到目录,数据会被存储到文件。一开始对象的属性是被 POSIX 的 xattrs 保存的,但后来被移到了 LevelDB(xattrs 容量有限)。
Btrfs 被用作生产环境后端很多年,这个过程中 Btrfs 一直有不稳定和数据/元数据的 fragmentation 问题,但因为对象接口的不断演进导致已经不太可能退回到 EBOFS 了,因此 FileStore 被移植到过 XFS、ext4、ZFS,最终因为在 XFS 上良好的 scale 和元数据性能而成为 FileStore 的事实标准。 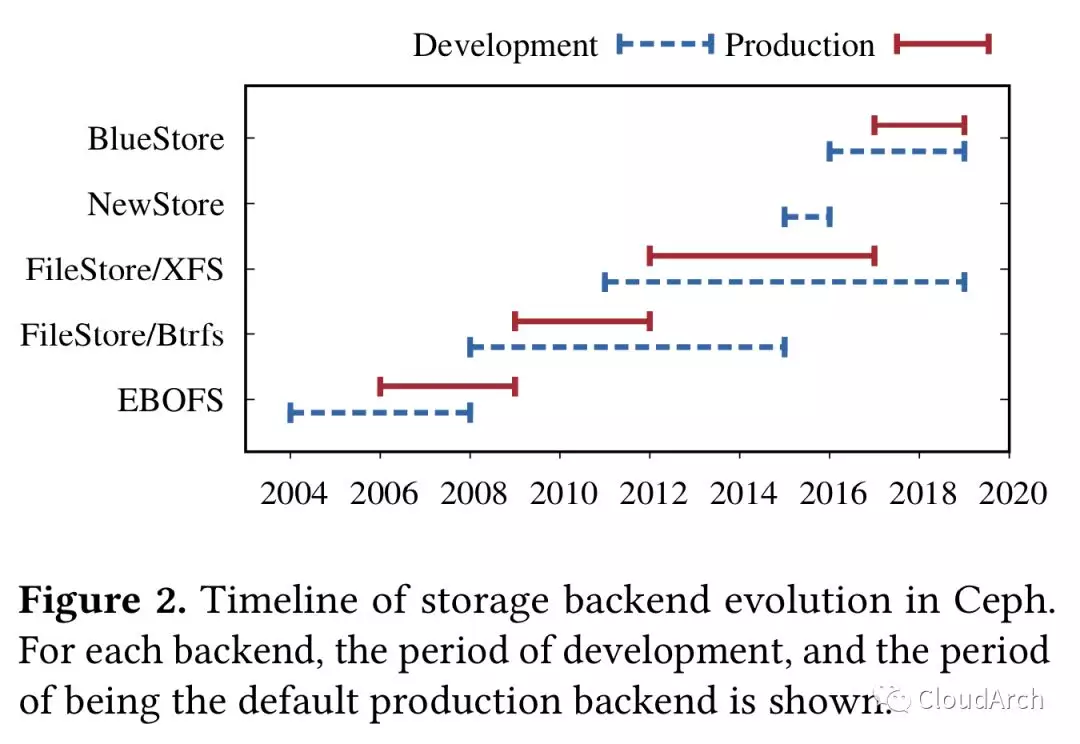
虽然基于 XFS 的 FileStore 已经比较稳定了,但是一直受元数据 fragmentation 和无法充分发挥硬件性能的问题困扰。因为缺乏原生的事务,所以用户态的 WAL 实现使用了完整数据的 journal,并受读取-修改-写入这一过程(read-modify-write workloads )的速度限制——这个正是 Ceph WAL 的典型操作过程。此外,XFS 不是一个 COW 文件系统,快照因为需要克隆操作受此影响就会很慢。
NewStore 是 Ceph 尝试通过基于文件系统解决元数据问题的第一次尝试。NewStore 不再使用目录来代表对象集合,而是用 RocksDB 保存元数据。此外 RocksDB 还用来实现 WAL,使得读取-修改-写入过程可以通过合并数据和元数据日志来加速。
这个方案整体来说就是通过文件保存数据、通过在日志文件系统上运行 RocksDB 来保存元数据。但这个方案带来沉重的一致性负担,最终促使了 BlueStore 的开发。

