Kubernetes 集群节点故障自愈系统怎么设计?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
我们都知道物理机硬件存在一定的故障概率,随着集群节点规模的增加,集群中会常态出现故障节点,如果不及时修复上线,这部分物理机的资源将会被闲置。
为解决这一问题,我们设计了一套故障发现、隔离、修复的闭环自愈系统。
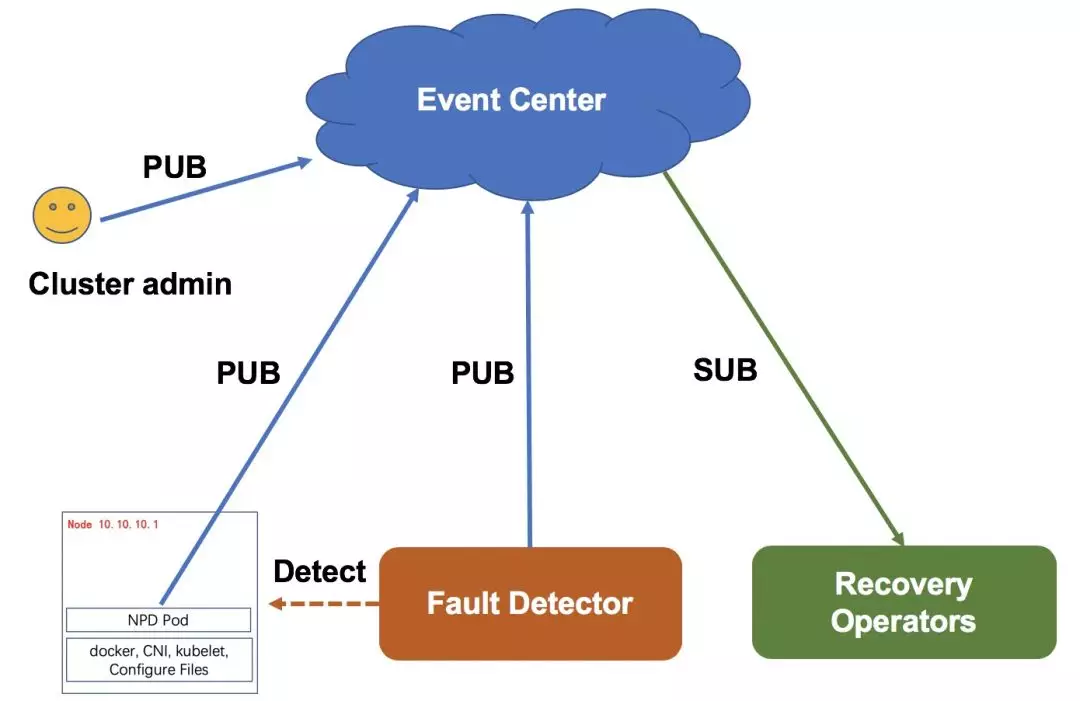
如下图所示,故障发现方面,采取 Agent 上报和监控系统主动探测相结合的方式,保证了故障发现的实时性和可靠性(Agent 上报实时性比较好,监控系统主动探测可以覆盖 Agent 异常未上报场景)。故障信息统一存储于事件中心,关注集群故障的组件或系统都可以订阅事件中心事件拿到这些故障信息。
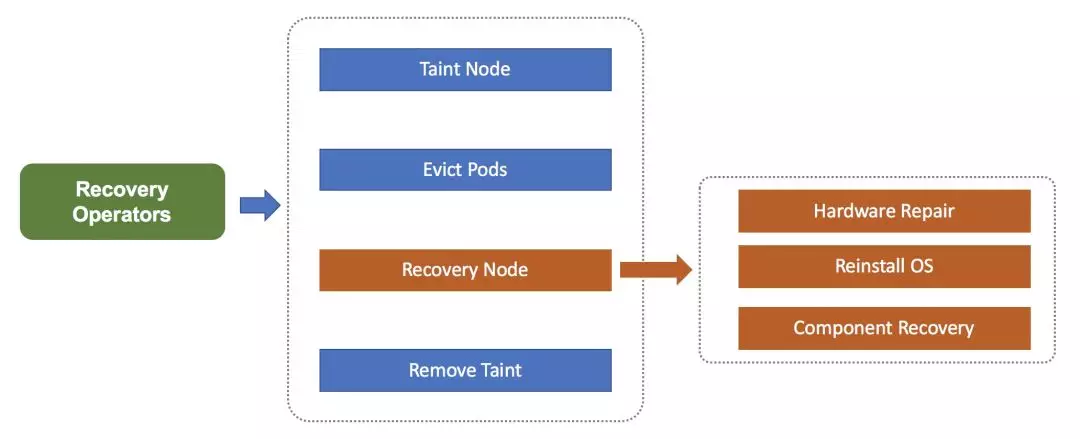
 节点故障自愈系统会根据故障类型创建不同的维修流程,例如:硬件维系流程、系统重装流程等。
节点故障自愈系统会根据故障类型创建不同的维修流程,例如:硬件维系流程、系统重装流程等。
维修流程中优先会隔离故障节点(暂停节点调度),然后将节点上 Pod 打上待迁移标签来通知 PaaS 或 MigrateController 进行 Pod 迁移,完成这些前置操作后,会尝试恢复节点(硬件维修、重装操作系统等),修复成功的节点会重新开启调度,长期未自动修复的节点由人工介入排查处理。