
阿里云 系统磁盘总读BPS 突然增长很高,导致网站502 Bad Gateway
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
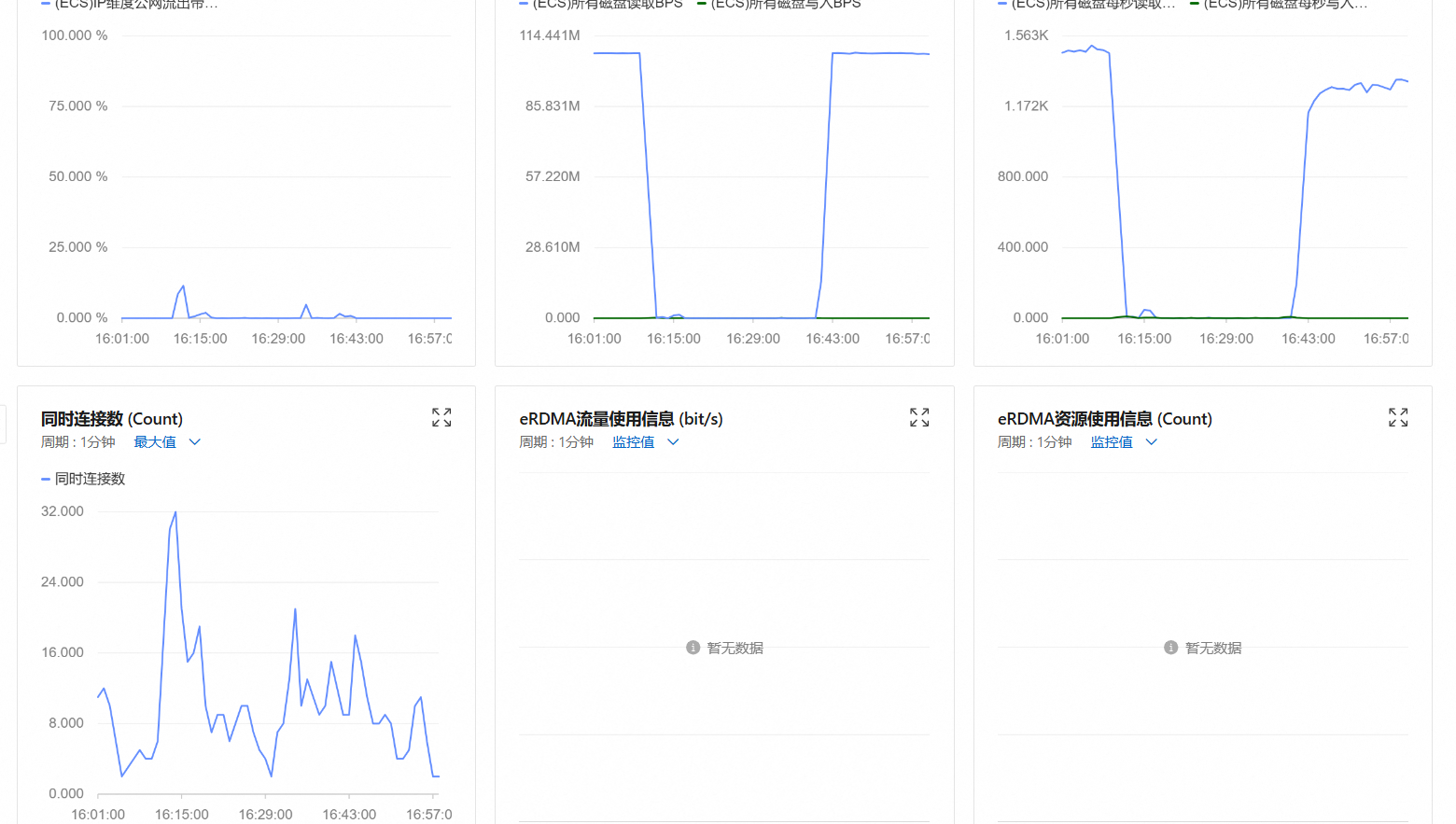
遇到同样的情况,几乎每天都会出现,而且一出现,就无法登陆系统,想查看是哪些进程在占用资源都不行,只能重启。
服务器遇到相同问题:无法远程连接,系统上所有web服务均无法正常使用,磁盘读取写入BPS和磁盘读取写入IOPS 居高不下。
服务器配置:2核2Git
先看看AI科普:
swappiness 是 Linux 内核参数,用于控制系统对交换分区(swap)的使用倾向。其取值范围是 0-100:
值越低(接近 0):系统更倾向于使用物理内存(RAM),只有在物理内存即将用完时才会使用交换分区
值越高(接近 100):系统更积极地使用交换分区,会较早地将内存页面写入交换分区
默认值通常是 60。
实际使用建议:
对于桌面系统,建议设置较低的值(如 10-30),以获得更好的系统响应性
对于服务器系统,可以根据具体应用场景调整:
如果内存充足,可以设置较低的值
如果需要处理大量数据,可以保持默认值或适当调高。
解决办法:
#查看当前 swappiness 值,默认都是0
cat /proc/sys/vm/swappiness
# 修改swappiness值,在文件末尾添加#vm.swappiness=10
vi /etc/sysctl.conf
#让配置生效
sudo sysctl -p
服务器配置:2核2Git
设置方式:将 swappiness 从 0 设置为 60;将 swap 文件设置为 4G 大小
效果:从稳定80%降为56%
找到原因了,swap设置太低造成的。系统初装的时候默认应该是1024MB,dnf运行大量占用了swap,造成磁盘堵塞。把swap提高就好了
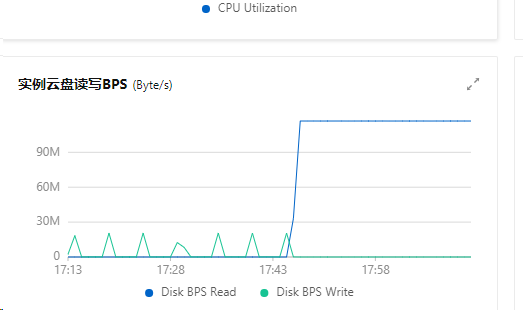
同问。
刚开始按此贴网友的建议,已经禁用了 dnf-makecache 和 dnf-makecache.timer
这两个服务。
但是后来又出现了,业务本来就不大,出现这个运维无法跟上面交待,我们需要阿里云一个交待。
我也遇到了这个情况,处理的过程这里分享一下 1. 根据时间轴检查系统日志
cat /var/log/messages
发现如下异常日志
Feb 20 22:41:12 ecs-for-tesla-001 systemd[1]: Starting dnf makecache...
Feb 20 22:41:13 ecs-for-tesla-001 dnf[4229]: AnolisOS-8 - AppStream 140 kB/s | 4.3 kB 00:00
Feb 20 22:41:13 ecs-for-tesla-001 dnf[4229]: AnolisOS-8 - BaseOS 350 kB/s | 4.3 kB 00:00
Feb 20 22:41:13 ecs-for-tesla-001 dnf[4229]: AnolisOS-8 - Extras 106 kB/s | 3.8 kB 00:00
Feb 20 22:41:13 ecs-for-tesla-001 dnf[4229]: AnolisOS-8 - PowerTools 113 kB/s | 4.2 kB 00:00
Feb 20 22:41:14 ecs-for-tesla-001 dnf[4229]: Docker CE Stable - x86_64 23 kB/s | 3.5 kB 00:00
Feb 20 22:41:14 ecs-for-tesla-001 dnf[4229]: Extra Packages for Enterprise Linux 8 - x86_64 378 kB/s | 4.7 kB 00:00
Feb 20 22:41:23 ecs-for-tesla-001 kernel: containerd invoked oom-killer: gfp_mask=0x6200ca(GFP_HIGHUSER_MOVABLE), order=0, oom_score_adj=-999
Feb 20 22:43:34 ecs-for-tesla-001 kernel: CPU: 0 PID: 1761 Comm: containerd Tainted: G OE --------- - - 4.18.0-372.16.1.an8_6.x86_64 #1
Feb 20 22:46:49 ecs-for-tesla-001 kernel: Hardware name: Alibaba Cloud Alibaba Cloud ECS, BIOS 449e491 04/01/2014
Feb 20 22:49:48 ecs-for-tesla-001 kernel: Call Trace:
Feb 20 22:51:47 ecs-for-tesla-001 kernel: dump_stack+0x41/0x60
Feb 20 22:58:09 ecs-for-tesla-001 kernel: dump_header+0x4a/0x1db
Feb 20 23:05:53 ecs-for-tesla-001 kernel: oom_kill_process.cold.32+0xb/0x10
Feb 20 23:12:21 ecs-for-tesla-001 kernel: out_of_memory+0x1bd/0x4e0
Feb 20 23:17:59 ecs-for-tesla-001 kernel: __alloc_pages_slowpath+0xbdc/0xcc0
Feb 20 23:23:14 ecs-for-tesla-001 kernel: ? __switch_to_asm+0x35/0x70
Feb 20 23:29:47 ecs-for-tesla-001 kernel: __alloc_pages_nodemask+0x2db/0x310
Feb 20 23:37:38 ecs-for-tesla-001 kernel: pagecache_get_page+0xca/0x310
Feb 20 23:42:58 ecs-for-tesla-001 kernel: Linux version 4.18.0-372.16.1.an8_6.x86_64 (mockbuild@anolis-build-01.openanolis.cn) (gcc version 8.5.0 20210514 (Anolis 8.5.0-10.0.1) (GCC)) #1 SMP Thu Jul 14 10:28:59 CST 2022
猜测是dnf后台更新缓存导致磁盘IO高导致,并且看到这里应该更新导致内存不足,系统还kill掉了我的docker容器
解决方案,卸载dnf或者关闭make-cache的动作
systemctl stop dnf-makecache.timer
systemctl disable dnf-makecache.timer
只开一个nacos镜像,一下子就读写就满了,cpu也是八九十,面板卡死,命令也没法输入,关掉服务器也是很慢,一直显示停止中
也是同样的情况,disk read 突然飙升,网站502,ssh也连不上,ECS控制台重启也重启不了,持续大概10分钟才恢复正常,请问有谁知道原因吗
我的今天也遇到这种情况。。。显示网络流量不大,没有下载大文件的可能。突然BPS就到顶了。然后所有东西都操作不了,网站也访问不了。

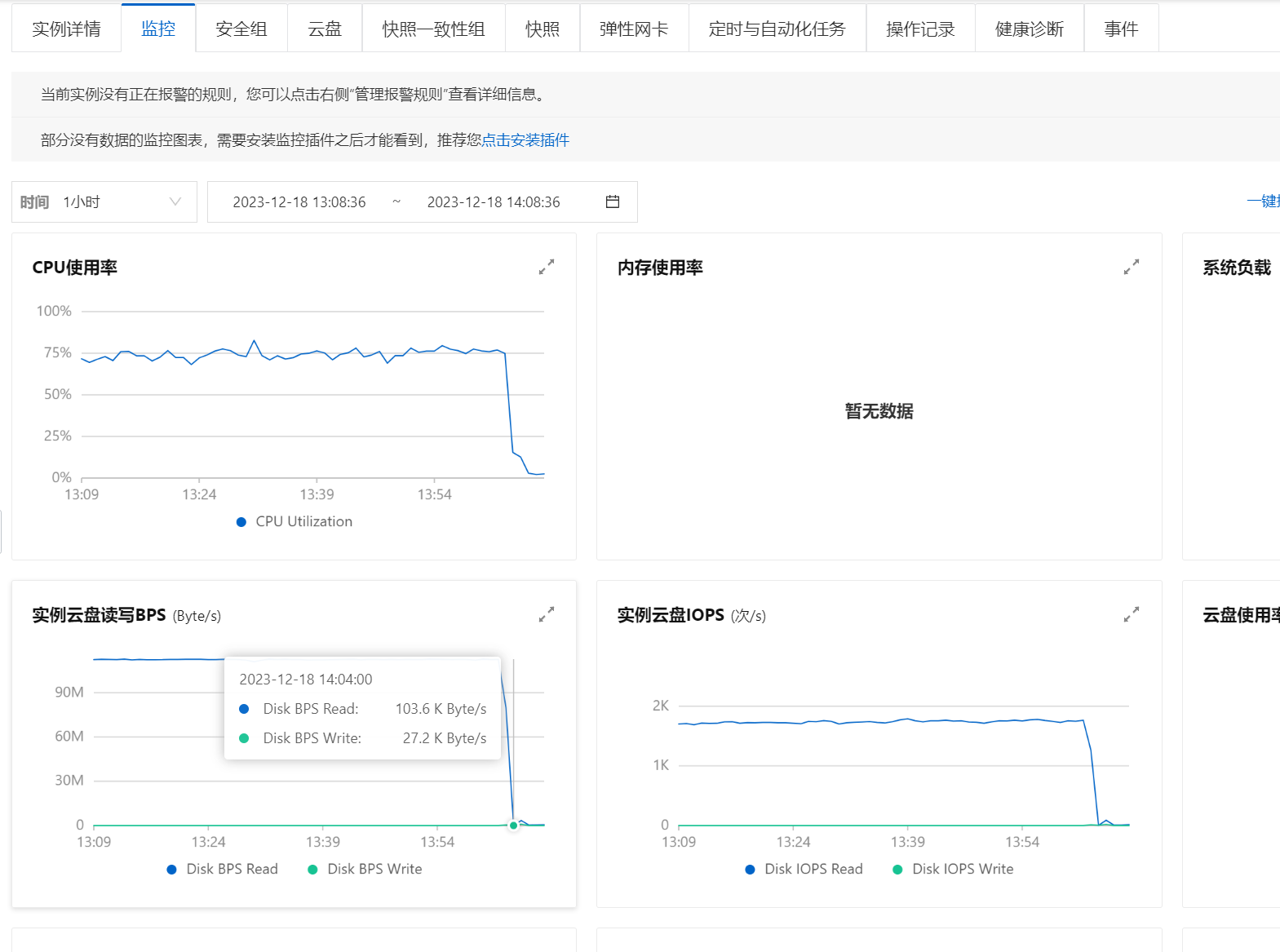
 这啥子情况,有人有解决方案吗
这啥子情况,有人有解决方案吗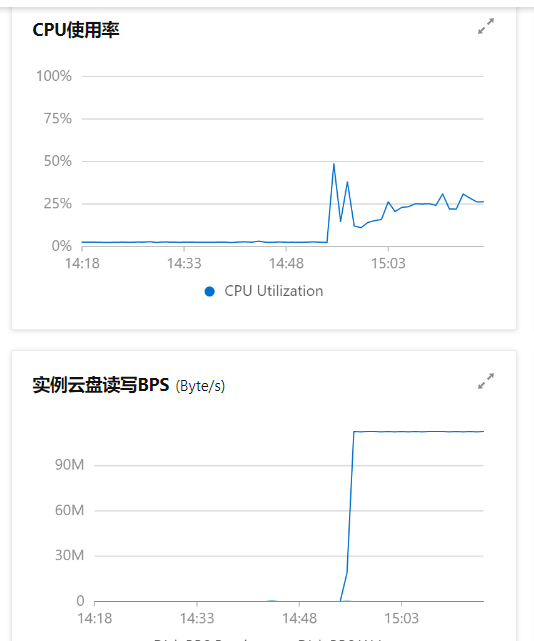 我这一周都要重启一次,每次找客服都是要授权去登陆搞,搞完过一段又这样。
我这一周都要重启一次,每次找客服都是要授权去登陆搞,搞完过一段又这样。