
可视化介绍
码栈提供的可视化编程是面向无编程经验的开发者,它提供了通过拖动的方式实现应用逻辑的功能。 开发者不需要再关注编程语法、运行环境以及复杂的API,只需要按照流程拖动滑块并将其拼接在一起即可。
预览
可视化编程界面主要分为“工具箱”、“画布区”两个部分,下面将逐一介绍其功能。
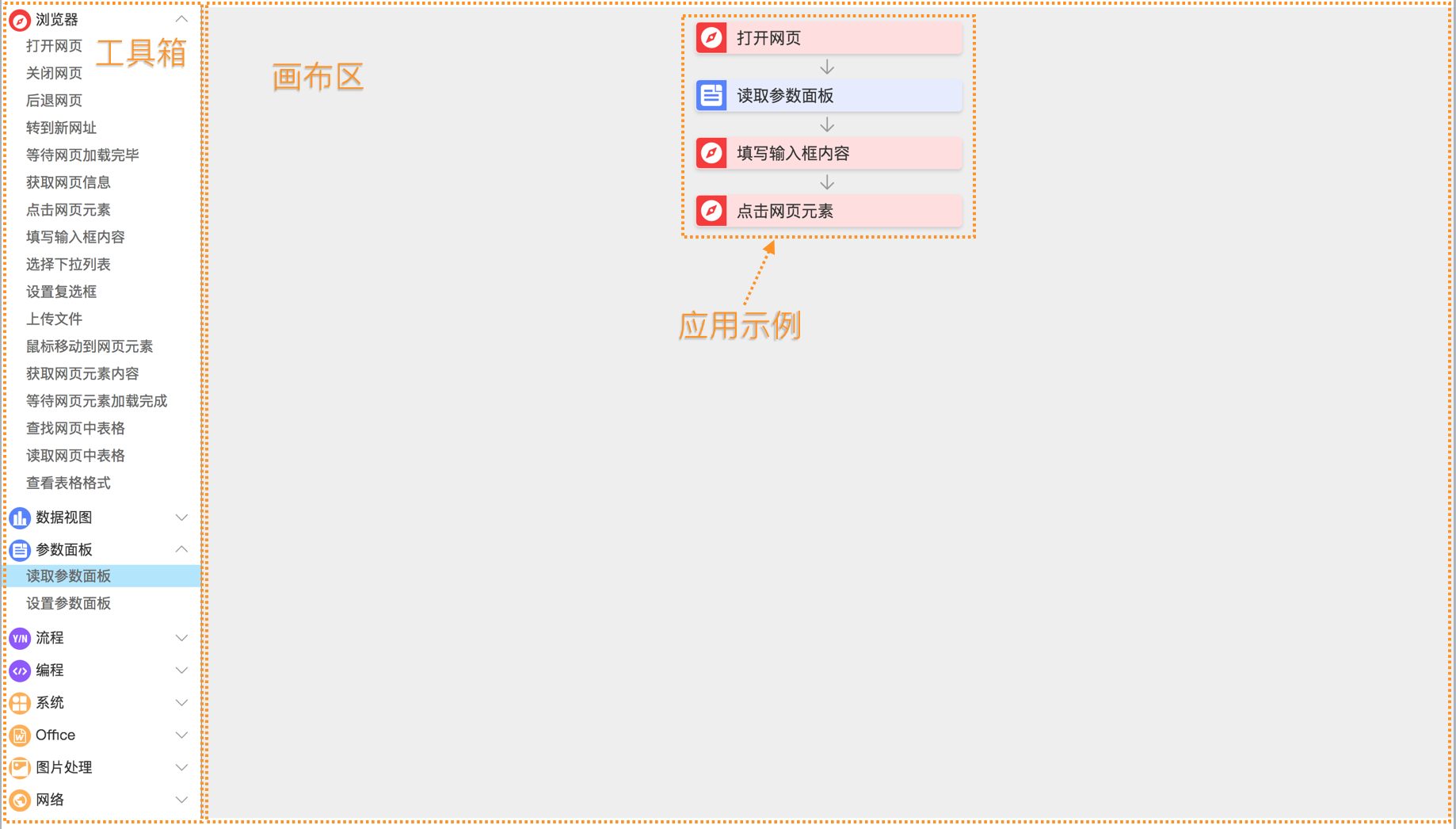
工具箱
工具箱中包含开发者可能用到的所有滑块,选中需要的滑块将其拖动到画布区即可。工具箱一般为两级菜单,第一级是分类菜单,第二级是具体的滑块。

工具箱中目前包含以下分类:

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您所描述的可视化编程界面听起来非常贴近阿里云的DataWorks产品中的数据开发功能,尽管它更专注于数据处理和分析,但其设计理念与您概述的可视化编程工具相似。下面我将基于阿里云DataWorks来解释这一概念,以帮助您更好地理解。
阿里云DataWorks是一个云端的一站式大数据开发、调度、运维管理平台,它支持无代码/低代码的可视化开发方式,特别适合没有深厚编程背景的数据分析师或业务人员使用。其核心特点包括:
拖拽式开发:DataWorks的工作流(也称为任务)设计采用了直观的图形化界面,用户可以通过拖拽操作来构建数据处理流程。这类似于您提到的“画布区”,用户可以从组件库中选择数据源、转换步骤(如过滤、聚合)、以及目标存储等组件,并在画布上连接它们以定义数据处理逻辑。
丰富的组件库:类似于您描述的“工具箱”,DataWorks提供了丰富的数据处理组件,涵盖了数据抽取(ETL)、清洗、转换、分析等多种需求。这些组件包括但不限于从各种数据库、文件系统中读取数据,执行SQL脚本,调用MapReduce、Spark等大数据计算引擎,以及将处理后的数据写入到不同的存储服务中。
参数配置与调度:每个组件或任务都支持详细的配置选项,允许用户根据实际需求定制化数据处理逻辑。同时,DataWorks还提供了强大的工作流调度能力,用户可以设定定时任务,实现自动化数据处理流程。
监控与管理:提供全面的任务运行监控、日志查看、性能分析等功能,便于用户跟踪数据处理过程,及时发现并解决问题。
协作与版本控制:支持团队协作,通过项目空间管理不同成员的权限,同时内置Git版本控制,方便代码管理和回溯。
虽然DataWorks主要聚焦于大数据处理场景,但它体现了与您描述的可视化编程理念相契合的高效、易用的开发模式,降低了技术门槛,使得非专业开发者也能快速构建复杂的数据应用。
