
Table Store Stream 是一个数据通道,用于获取 Table Store 表中的增量数据。您可以使用 Table Store Stream API 来获取这些修改内容。增量数据的重要性不言而喻,有了增量数据,可以进行增量数据流的实时增量分析、数据增量同步等。
原理
表格存储作为一款分布式 NoSQL 数据库,当有写操作(包括 put,delete,update)传入时,会把对应的修改记录存放在表格存储的 commit log 中,同时数据库也会定期做 checkpoint,旧的 commit 日志会被清除。
开启 Stream后,日志文件会被保存。在设置的保存期限内,可以通过 Stream 提供的通道读取这些增量数据。
由于表格存储的分区特性,同一分区的操作会共享一个 commit log,所以获取增量数据也是按照分区维度获取。
开启 Stream 时,会生成一个当前日志偏移量(即 iterator)并记录下来。用户可以通过 GetShardIterator 接口获取当前分区的 iterator,在后续读取该分区增量数据时传入这个 iterator,Stream 通道就可以知道从哪一行日志记录开始返回增量内容。返回增量内容的同时,Stream 也会返回一个新的偏移量,用于后续的读取。整个过程可以类比我们分页读取数据,iterator 就是分页的偏移量。
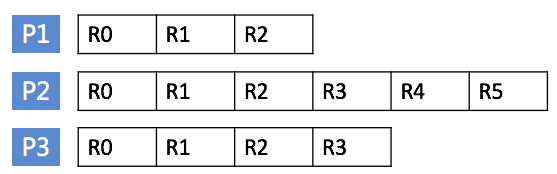
例如,我们有顺序地生成一批数据库日志文件,如下所示:

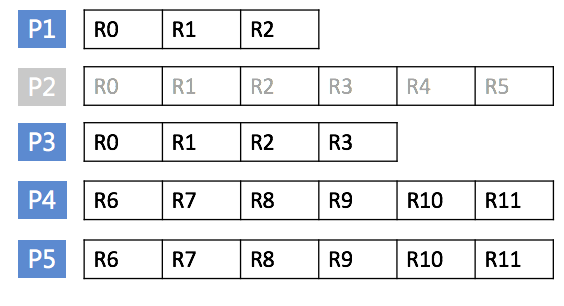
当我们在文件 A,第 3 行开始开启 Stream,则这个 iterator 就可以用来标识文件 A 的第 3 行。读取数据时传入这个 iterator,就能读到从上图中第三个操作 pk3 开始的后续修改操作。
Stream API 也提供了接口关闭这个数据通道。当用户再次开启时,Stream 会根据本次开启时间的日志偏移量重新生成一个当前分区的 iterator,我们可以用这个 iterator 读取该分区当前时间点之后的增量数据。
由于写操作会发生在同一个主键上,为了确保数据的一致性,对同一个主键的写操作需要顺序读取。然而,在读取增量数据之前,我们并不知道在哪些主键上发生了修改,所以读取增量数据的接口按照分区 id 来划分。用户可以通过罗列当前表下的所有分区来读取整张表的增量数据。Stream 通道会保证同分区内的写操作是顺序返回的,即,只要在同一分区内按照顺序读取,就可以保证相同主键的数据的一致性。如果持续读取所有分区的 Stream 数据,也就确保了整张表的增量数据都被会被读取到。
用户可以在创建表的时候开启 Stream,或者通过 UpdateTable 来开启或者关闭 Stream。当有一个 put,update 或者 delete 操作发生,一条修改记录会被写入 Stream,数据包含用户修改行的主键以及修改内容。
[backcolor=transparent]注意:
- 每个修改记录在 Stream 中存在且仅存在一次。
- 在每一个 shard 内,Stream 按照用户的实际操作顺序进行修改。但是不同 shard 的数据,不保证顺序。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
