您可以通过大数据开发套件中的
数据集成 创建数据同步任务,对 MaxCompute 中的数据进行导入和导出操作。
前置条件
在开始数据的导入和导出操作前,您需要根据
准备阿里云账号和
购买并创建项目 中的操作,做好准备工作。
添加 MaxCompute 数据源
注意:
只有项目管理员角色才能够新建数据源,其他角色的成员仅能查看数据源。
若需要添加的数据源是当前 MaxCompute 项目,则无需进行此操作。该项目创建成功时,即在数据集成的数据源中,默认将该项目添加为数据源,数据源名为 odps_first。
操作步骤
以项目管理员身份进入 大数据开发套件管理控制台,单击 项目列表 下对应项目操作栏中的 进入工作区。
单击顶部菜单栏中的 数据集成,导航至 数据源 页面。
单击 新增数据源。
在新增数据源弹出框中填写相关配置项,如下图所示:
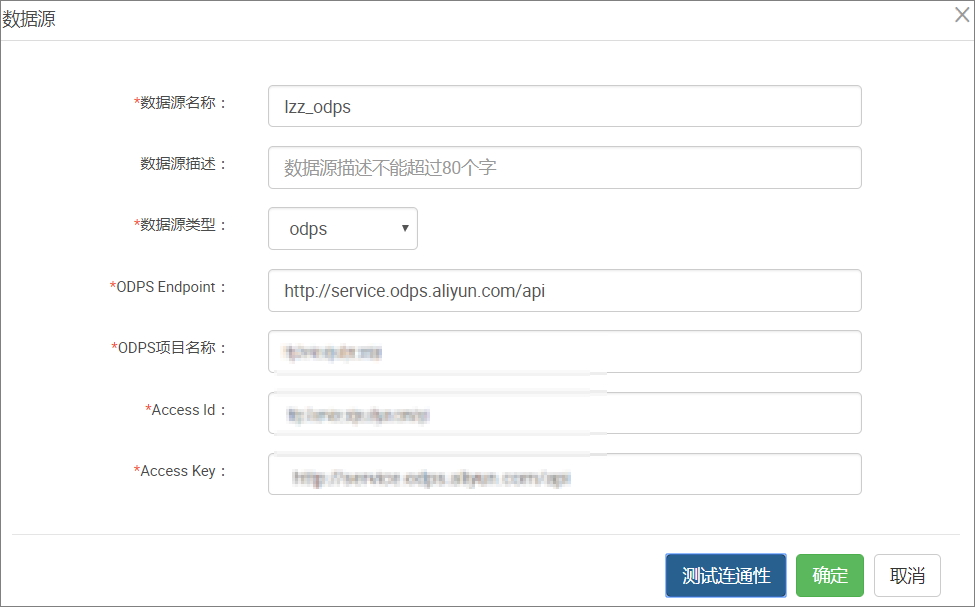
配置项说明如下:
数据源名称: 由英文字母、数字、下划线组成且需以字符或下划线开头,长度不超过 60 个字符。
数据源描述: 对数据源进行简单描述,不得超过 80 个字符。
数据源类型: 当前选择的数据源类型 MySQL。
ODPS Endpoint: 默认只读。从系统配置中自动读取。
ODPS项目名称: 对应的 MaxCompute Project 标识。
Access Id: 与 MaxCompute Project Owner 云账号对应的 AccessID。
Access Key: 与 MaxCompute Project Owner 云账号对应的 AccessKey,与 AccessID 成对使用。
单击 测试连通性。
若测试连通性成功,单击 保存 即可。
其他的数据源的配置请参见 数据源配置。
通过数据集成导入数据
以将 MySQL 的数据导入到 MaxCompute 中为例,您可以通过
向导模式 和
脚本模式 两种方式配置同步任务。
向导模式配置同步任务
新建向导模式的同步任务,如下图所示:
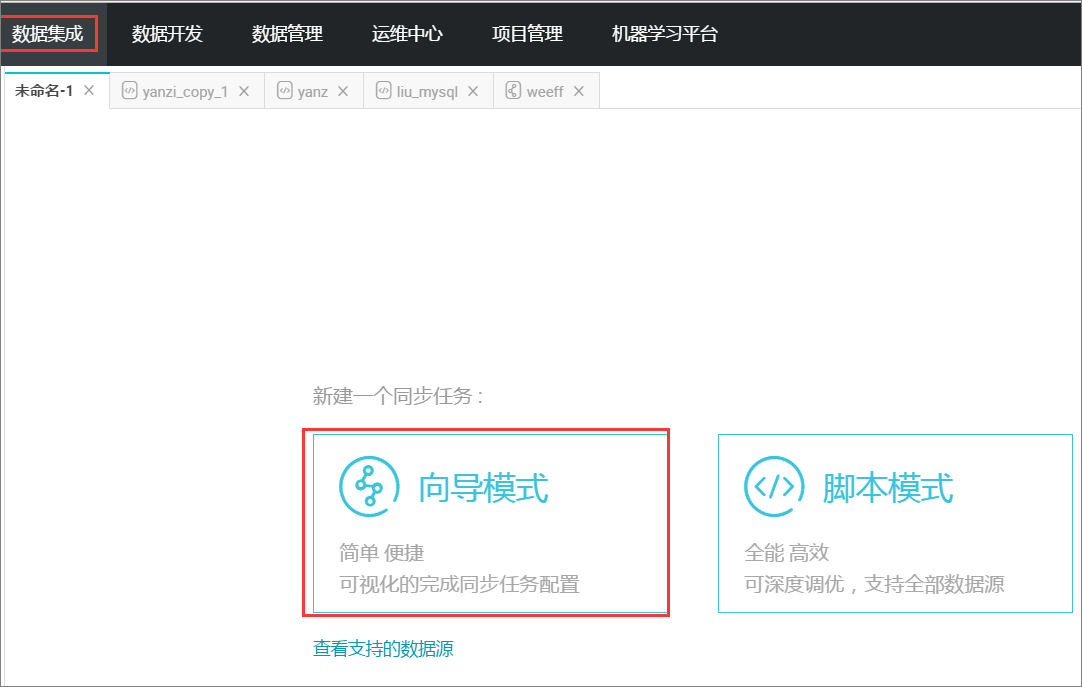
选择来源。
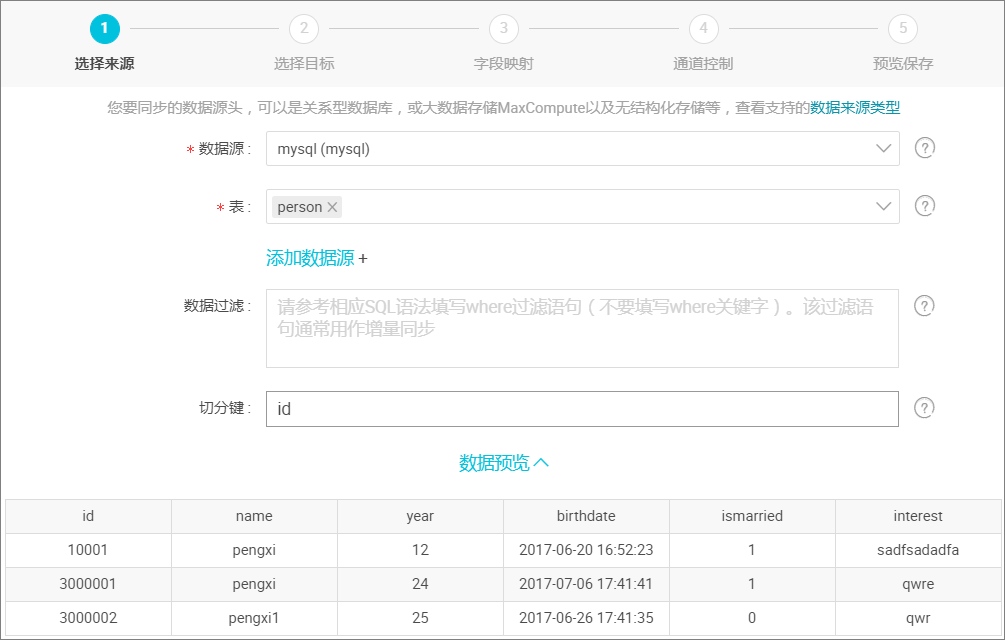
选择 MySQL 数据源及源头表 mytest,数据浏览默认是收起的,选择后单击 下一步,如下图所示:
选择目标。
目标即 MaxCompute(原 ODPS),表可以是提前创建,也可以在此处单击 快速建表,如下图所示:
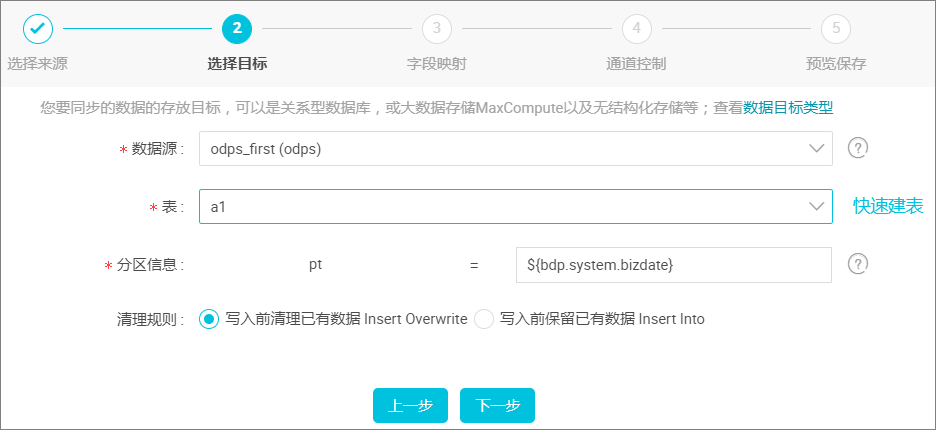
配置项说明:
分区信息:必须指定到最后一级分区。例如:把数据写入一个三级分区表,必须配置到最后一级分区,例如 pt=20150101,type=1,biz=2。非分区表无此项配置。
清理规则:
写入前清理已有数据:导数据之前,清空表或者分区的所有数据,相当于 insert overwrite。
写入前保留已有数据:导数据之前不清理任何数据,每次运行数据都是追加进去的,相当于 insert into。
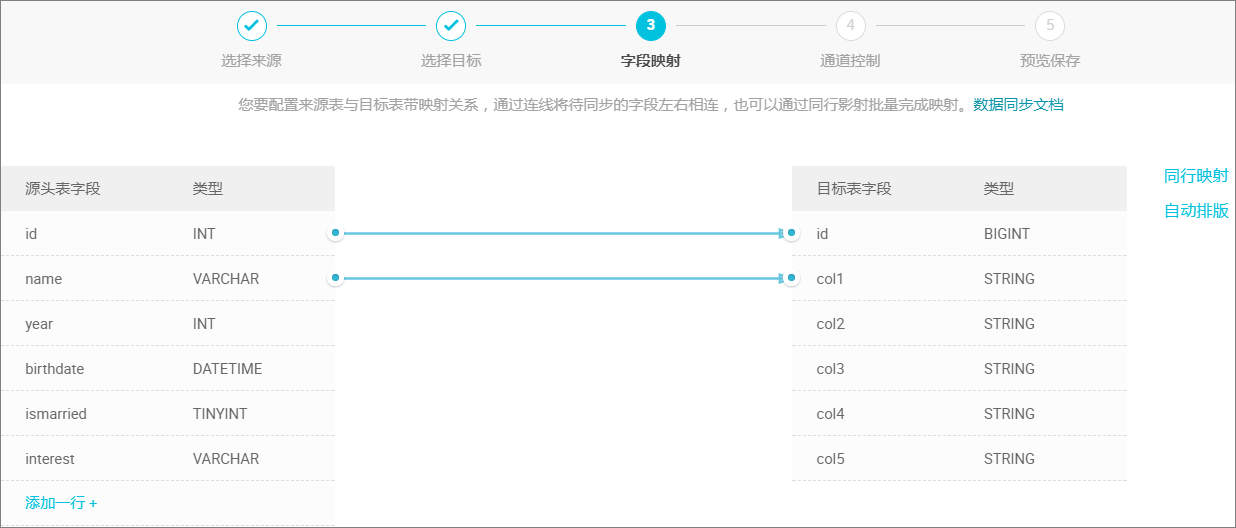
映射字段。
选择字段的映射关系。需对字段映射关系进行配置,左侧 源头表字段 和右侧 目标表字段 为一一对应的关系:
通道控制。
单击 下一步,配置作业速率上限和脏数据检查规则。如下图所示:
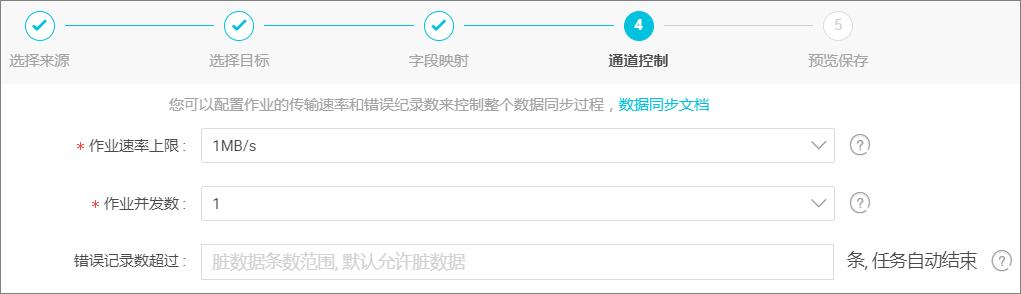
配置项说明:
作业速率上限:是指数据同步作业可能达到的最高速率,其最终实际速率受网络环境、数据库配置等的影响。
作业并发数:从单同步作业来看,作业并发数*单并发的传输速率=作业传输总速率。
当作业速率上限已选定的情况下,应该如何选择作业并发数?
如果您的数据源是线上的业务库,建议您不要将并发数设置过大,以防对线上库造成影响。
如果您对数据同步速率特别在意,建议您选择最大作业速率上限和较大的作业并发数。
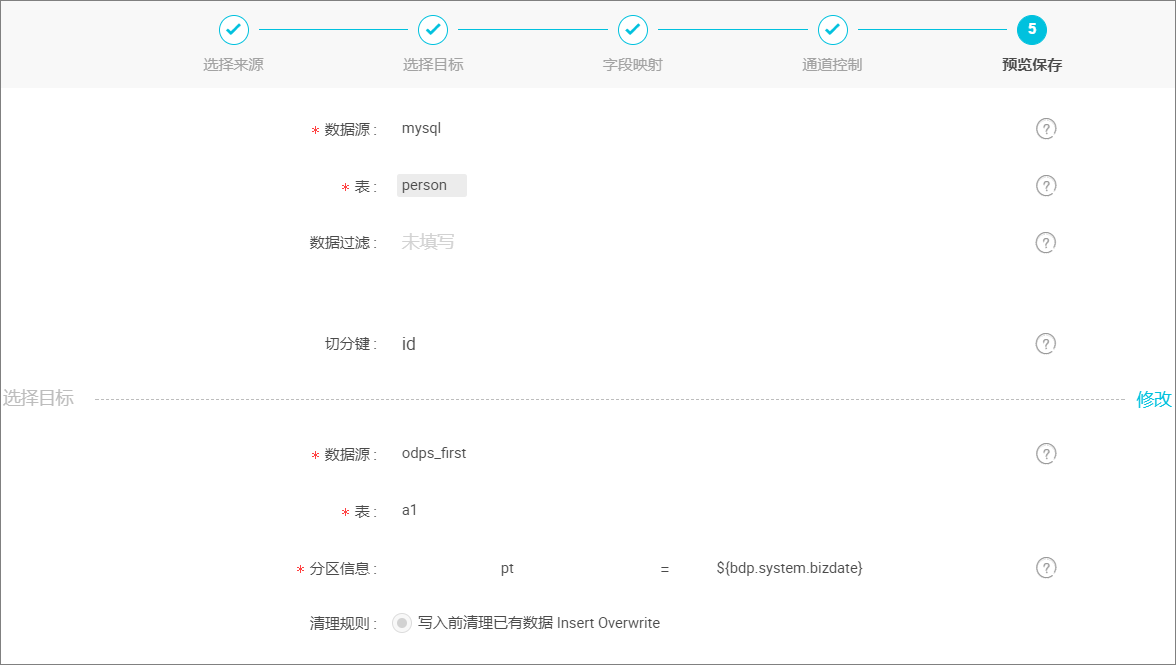
预览保存。
完成上述配置后,上下滚动鼠标可查看任务配置,如若无误,单击 保存,如下图所示:
 运行同步任务
直接运行同步任务
运行同步任务
直接运行同步任务
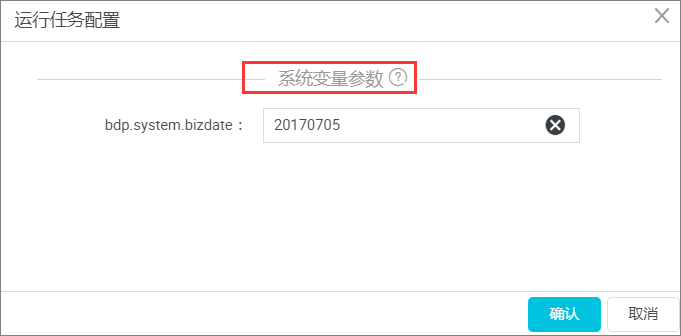
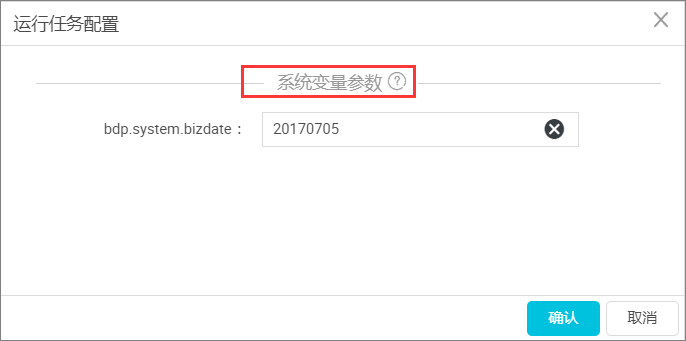
只有在同步任务设置了系统变量参数,在运行时才会自动弹出弹框配置参数变量。如下图所示:
运行同步任务日志情况,如下图所示:
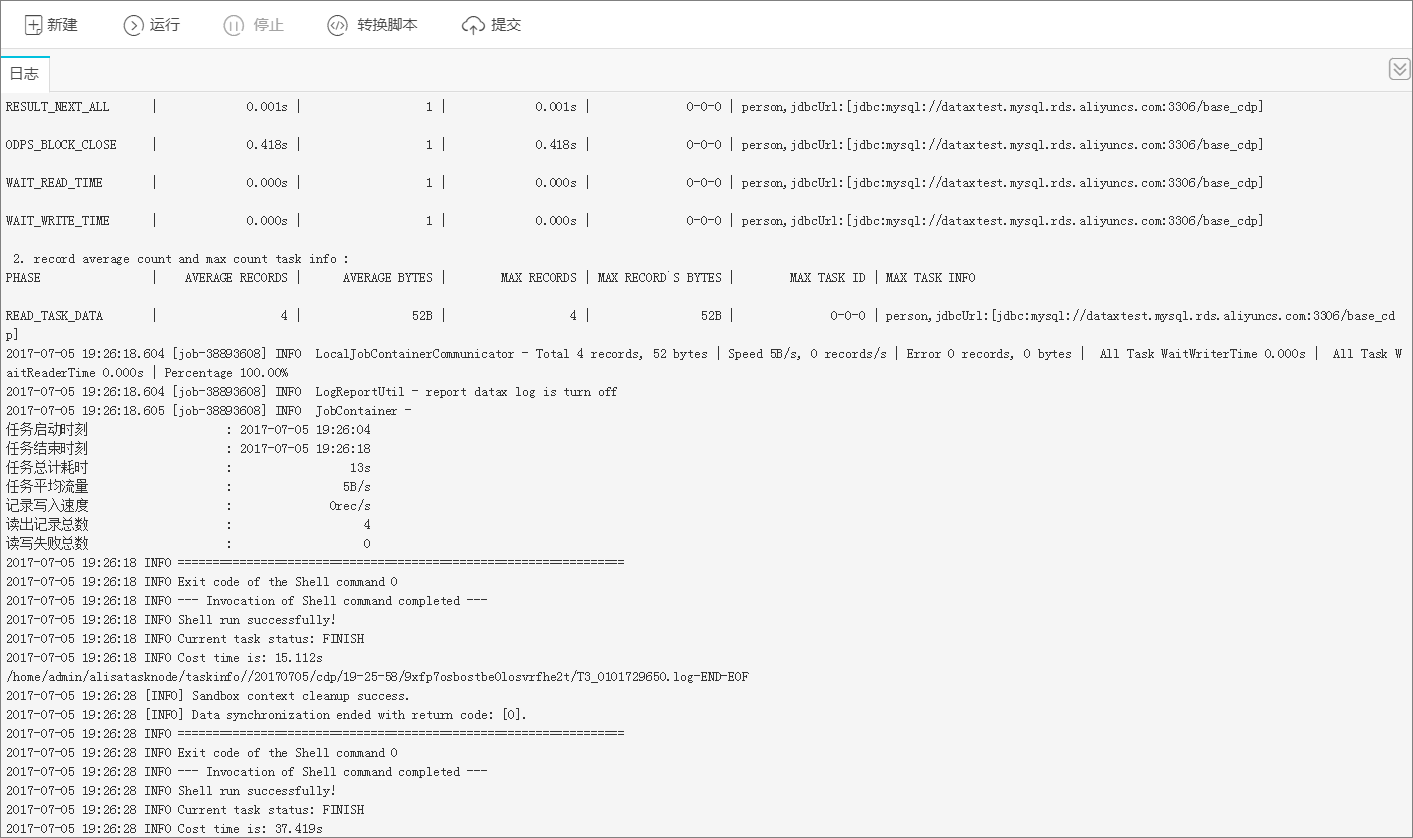
同步任务保存后,直接单击
运行,任务便会立刻运行。您也可以单击
提交,将同步任务提交到大数据开发套件的调度系统中,调度系统会按照配置属性在从第二天开始自动定时执行,相关调度的配置请参见
调度配置介绍。
脚本模式配置同步任务
您可参考以下脚本进行配置同步任务操作,其他配置与任务运行同
向导模式 方式。
- {
- "type": "job",
- "version": "1.0",
- "configuration": {
- "reader": {
- "plugin": "mysql",
- "parameter": {
- "datasource": "mysql",
- "where": "",
- "splitPk": "id",
- "connection": [
- {
- "table": [
- "person"
- ],
- "datasource": "mysql"
- }
- ],
- "connectionTable": "person",
- "column": [
- "id",
- "name"
- ]
- }
- },
- "writer": {
- "plugin": "odps",
- "parameter": {
- "datasource": "odps_first",
- "table": "a1",
- "truncate": true,
- "partition": "pt=${bdp.system.bizdate}",
- "column": [
- "id",
- "col1"
- ]
- }
- },
- "setting": {
- "speed": {
- "mbps": "1",
- "concurrent": "1"
- }
- }
- }
- }
通过数据集成导出数据
以将 MaxCompute 的数据导出到 MySQL 中为例,您可以通过
向导模式 和
脚本模式 两种方式配置同步任务。
新建向导模式同步任务
新建向导模式的同步任务,如下图所示:
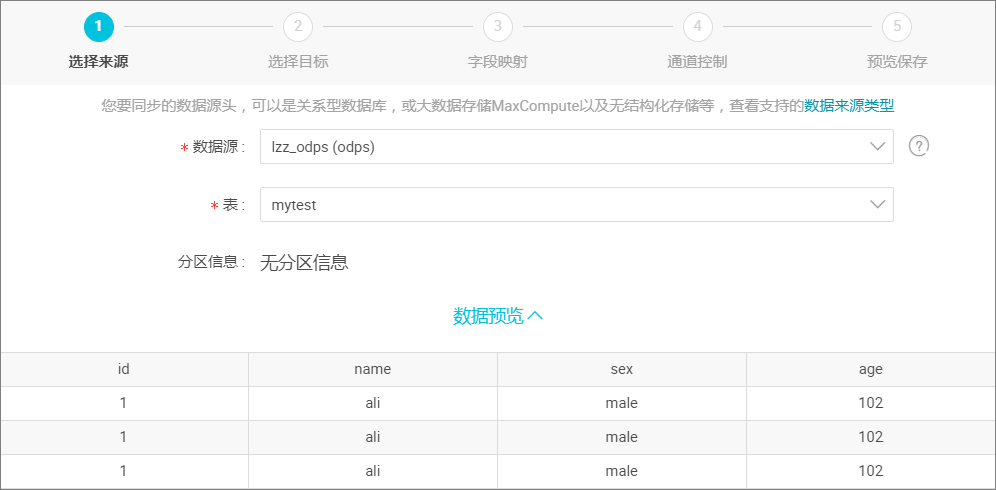
选择来源。
选择 MaxCompute(原 ODPS)数据源及源头表 mytest,数据浏览默认是收起的,选择后单击 下一步,如下图所示:
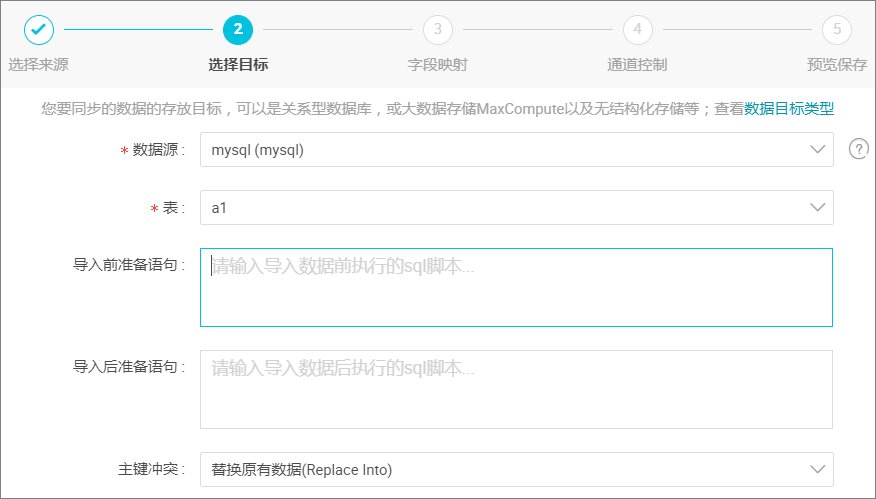
选择目标。
选择 MySQL 数据源及目标表 a1,选择后单击 下一步,如下图所示:
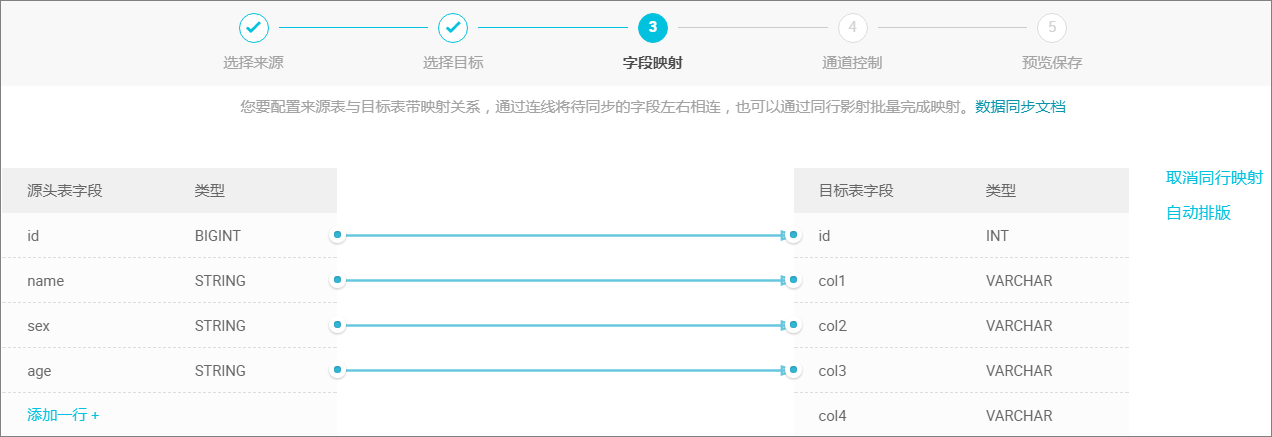
映射字段。
单击 下一步,选择字段的映射关系。需对字段映射关系进行配置,左侧 源头表字段 和右侧 目标表字段 为一一对应的关系。
通道控制。
单击 下一步,配置作业速率上限和脏数据检查规则。如下图所示:
配置项说明:
作业速率上限:指数据同步作业可能达到的最高速率,其最终实际速率受网络环境、数据库配置等的影响。
作业并发数:从单同步作业来看,作业并发数*单并发的传输速率=作业传输总速率。
当作业速率上限已选定的情况下,应该如何选择作业并发数?
如果您的数据源是线上的业务库,建议您不要将并发数设置过大,以防对线上库造成影响。
如果您对数据同步速率特别在意,建议您选择最大作业速率上限和较大的作业并发数。
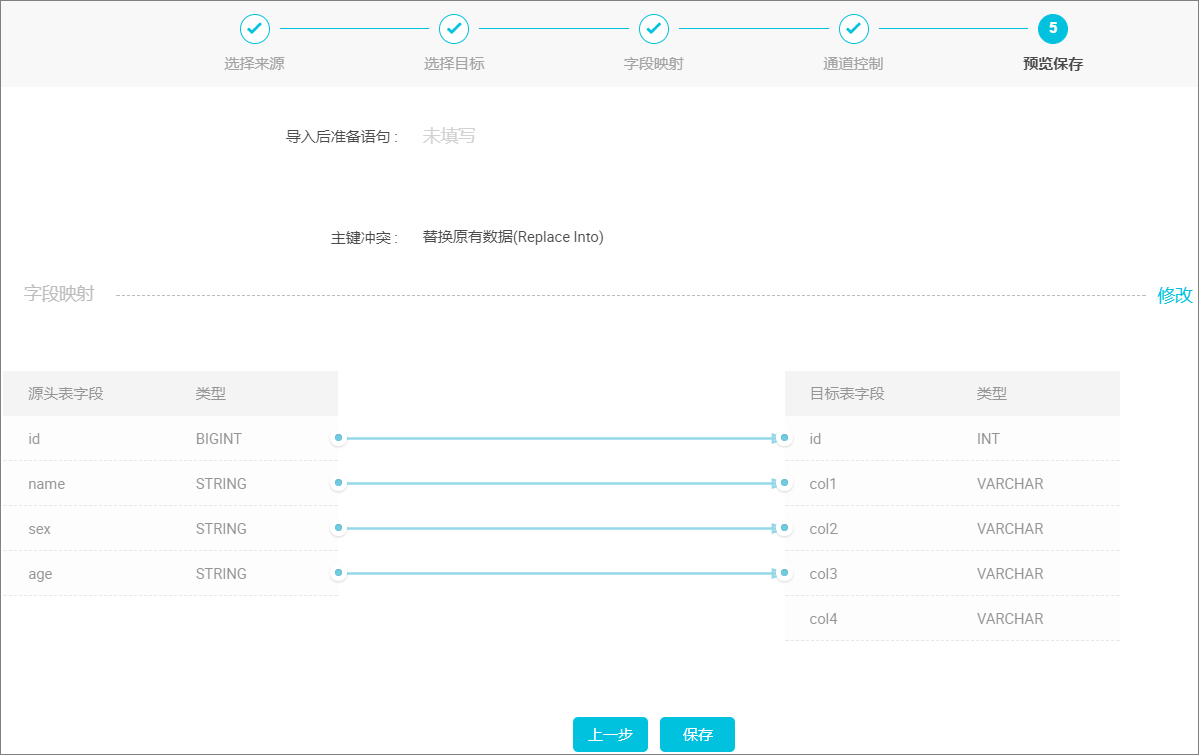
预览保存。
完成上述配置后,上下滚动鼠标可查看任务配置,如若无误,单击 保存,如下图所示:
 提交数据同步任务
直接运行同步任务
提交数据同步任务
直接运行同步任务
直接运行同步任务,运行日志如下图所示:

同步任务保存后,直接单击
运行,任务便会立刻运行。您也可以单击
提交,将同步任务提交到大数据开发套件的调度系统中,调度系统会按照配置属性在从第二天开始自动定时执行,相关调度的配置请参见
调度配置介绍。
脚本模式配置同步任务
您可参考以下脚本进行配置同步任务操作,其他配置与任务运行同
向导模式 方式。
- {
- "type": "job",
- "version": "1.0",
- "configuration": {
- "reader": {
- "plugin": "odps",
- "parameter": {
- "datasource": "zz_odps",//数据源的名称,建议都添加数据源后进行同步
- "table": "mytest",//数据来源的表名
- "partition": "",分区信息
- "column": [
- "id",
- "name",
- "sex",
- "age"
- ]
- }
- },
- "writer": {
- "plugin": "mysql",
- "parameter": {
- "datasource": "mysql",//数据源的名称,建议都添加数据源后进行同步
- "table": "a1",
- "preSql": [],//导入前准备语句
- "postSql": [],//导入后准备语句
- "writeMode": "replace",//主键冲突配置
- "column": [
- "id",
- "col1",
- "col2",
- "col3"
- ]
- }
- },
- "setting": {
- "speed": {
- "mbps": "1",//一个并发的速率上线是1MB/S
- "concurrent": "1"//并发的数目
- }
- }
- }
- }
参考文档

