MaxCompute 提供多种数据导入导出方式,如下所示:
Tunnel 命令导入数据
准备数据
假设您已准备本地文件 wc_example.txt,本地存放路径为 D:\odps\odps\bin,内容如下:
- I LOVE CHINA!
- MY NAME IS MAGGIE.I LIVE IN HANGZHOU!I LIKE PLAYING BASKETBALL!
创建 MaxCompute 表
您需要把上面的数据导入到 MaxCompute 的一张表中,所以需要创建 MaxCompute 表:
- CREATE TABLE wc_in (word string);
执行 tunnel 命令
输入表创建成功后,可以在 MaxCompute 客户端输入 Tunnel 命令进行数据的导入,如下所示:
- tunnel upload D:\odps\odps\bin\wc_example.txt wc_in;
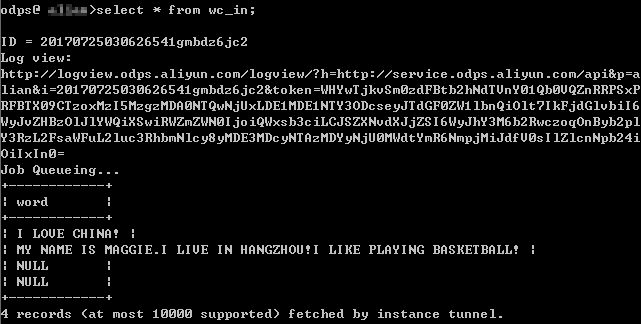
执行成功后,查看表 wc_in 的记录,如下所示:
注意:
有关 Tunnel 命令的更多详细介绍,例如:如何将数据导入分区表等,请参见 Tunnel 操作。
当表中含有多个列时,可以通过 -fd 参数指定列分隔符。
Tunnel SDK
下文将通过场景示例,为您介绍如何利用 Tunnel SDK 上传数据。
场景描述
上传数据到 MaxCompute,其中,项目空间为 odps_public_dev,表名为 tunnel_sample_test,分区为 pt=20150801,dt=hangzhou。
操作步骤
创建表,添加分区,SQL 语句如下所示:CREATE TABLE IF NOT EXISTS tunnel_sample_test(- id STRING,
- name STRING)
- PARTITIONED BY (pt STRING, dt STRING); --创建表
- ALTER TABLE tunnel_sample_test
- ADD IF NOT EXISTS PARTITION (pt='20150801',dt='hangzhou'); --添加分区
创建 UploadSample 的工程目录结构,如下所示:
- |---pom.xml
- |---src
- |---main
- |---java
- |---com
- |---aliyun
- |---odps
- |---tunnel
- |---example
- |---UploadSample.java
目录说明:
pom.xml:maven 工程文件。
UploadSample:Tunnel 源文件。
编写 UploadSample 程序。代码如下所示:
- package com.aliyun.odps.tunnel.example;
- import java.io.IOException;
- import java.util.Date;
- import com.aliyun.odps.Column;
- import com.aliyun.odps.Odps;
- import com.aliyun.odps.PartitionSpec;
- import com.aliyun.odps.TableSchema;
- import com.aliyun.odps.account.Account;
- import com.aliyun.odps.account.AliyunAccount;
- import com.aliyun.odps.data.Record;
- import com.aliyun.odps.data.RecordWriter;
- import com.aliyun.odps.tunnel.TableTunnel;
- import com.aliyun.odps.tunnel.TunnelException;
- import com.aliyun.odps.tunnel.TableTunnel.UploadSession;
- public class UploadSample {
- private static String accessId = "####";
- private static String accessKey = "####";
- private static String tunnelUrl = "http://dt.odps.aliyun.com";
- private static String odpsUrl = "http://service.odps.aliyun.com/api";
- private static String project = "odps_public_dev";
- private static String table = "tunnel_sample_test";
- private static String partition = "pt=20150801,dt=hangzhou";
- public static void main(String args[]) {
- Account account = new AliyunAccount(accessId, accessKey);
- Odps odps = new Odps(account);
- odps.setEndpoint(odpsUrl);
- odps.setDefaultProject(project);
- try {
- TableTunnel tunnel = new TableTunnel(odps);
- tunnel.setEndpoint(tunnelUrl);
- PartitionSpec partitionSpec = new PartitionSpec(partition);
- UploadSession uploadSession = tunnel.createUploadSession(project,
- table, partitionSpec);
- System.out.println("Session Status is : "
- + uploadSession.getStatus().toString());
- TableSchema schema = uploadSession.getSchema();
- RecordWriter recordWriter = uploadSession.openRecordWriter(0);
- Record record = uploadSession.newRecord();
- for (int i = 0; i < schema.getColumns().size(); i++) {
- Column column = schema.getColumn(i);
- switch (column.getType()) {
- case BIGINT:
- record.setBigint(i, 1L);
- break;
- case BOOLEAN:
- record.setBoolean(i, true);
- break;
- case DATETIME:
- record.setDatetime(i, new Date());
- break;
- case DOUBLE:
- record.setDouble(i, 0.0);
- break;
- case STRING:
- record.setString(i, "sample");
- break;
- default:
- throw new RuntimeException("Unknown column type: "
- + column.getType());
- }
- }
- for (int i = 0; i < 10; i++) {
- recordWriter.write(record);
- }
- recordWriter.close();
- uploadSession.commit(new Long[]{0L});
- System.out.println("upload success!");
- } catch (TunnelException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
注意:
这里省略了 accessId 和 accesskey 的配置,实际运行时请换上您自己的 accessId 以及 accessKey。
配置 pom.xml 文件。如下所示:
- <?xml version="1.0" encoding="UTF-8"?>
- <project xmlns="http://maven.apache.org/POM/4.0.0"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <modelVersion>4.0.0</modelVersion>
- <groupId>com.aliyun.odps.tunnel.example</groupId>
- <artifactId>UploadSample</artifactId>
- <version>1.0-SNAPSHOT</version>
- <dependencies>
- <dependency>
- <groupId>com.aliyun.odps</groupId>
- <artifactId>odps-sdk-core</artifactId>
- <version>0.20.7-public</version>
- </dependency>
- </dependencies>
- <repositories>
- <repository>
- <id>alibaba</id>
- <name>alibaba Repository</name>
- <url>http://mvnrepo.alibaba-inc.com/nexus/content/groups/public/</url>
- </repository>
- </repositories>
- </project>
编译与运行。
编译 UploadSample 工程,如下所示:
- mvn package
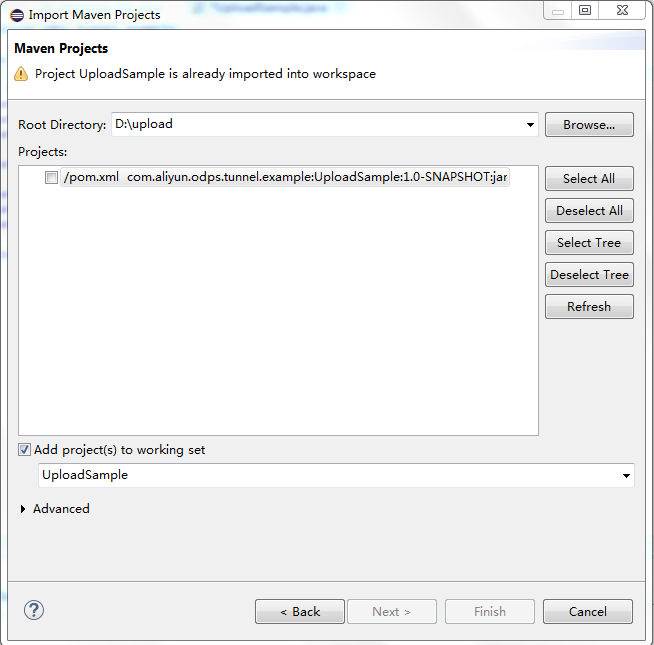
运行 UploadSample 程序,这里使用 eclipse 导入 maven project:
右击 java 工程 并单击 Import->Maven->Existing Maven Projects 设置如下:
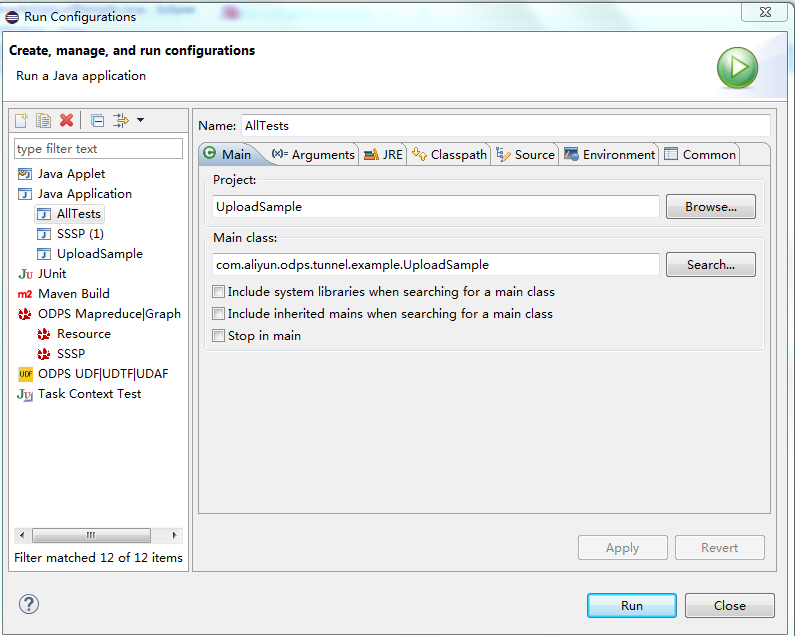
右击 UploadSample.java 并单击 Run As->Run Configurations,如下所示:
单击 Run 运行成功,控制台显示如下: Session Status is : NORMAL- upload success!
查看运行结果。
您在客户端输入如下语句,即可查看运行结果。
- select * from tunnel_sample_test;
显示结果如下:
- +----+------+----+----+
- | id | name | pt | dt |
- +----+------+----+----+
- | sample | sample | 20150801 | hangzhou |
- | sample | sample | 20150801 | hangzhou |
- | sample | sample | 20150801 | hangzhou |
- | sample | sample | 20150801 | hangzhou |
- | sample | sample | 20150801 | hangzhou |
- | sample | sample | 20150801 | hangzhou |
- | sample | sample | 20150801 | hangzhou |
- | sample | sample | 20150801 | hangzhou |
- | sample | sample | 20150801 | hangzhou |
- | sample | sample | 20150801 | hangzhou |
- +----+------+----+----+
注意:
其他导入方式
除了通过客户端及 Tunnel Java SDK 导入数据,阿里云数加数据集成、开源的Sqoop、Fluentd、Flume、LogStash 等工具都可以进行数据导入到 MaxCompute,具体介绍请参见
数据上传下载-工具介绍。

