日志服务
LogShipper功能可以便捷地将日志数据投递到 OSS、Table Store、MaxCompute 等存储类服务,配合 E-MapReduce(Spark、Hive)、MaxCompute 进行离线计算。
数仓(离线计算)
数据仓库+离线计算是实时计算的补充,两者针对目标不同:
目前对于数据分析类需求,同一份数据会同时做实时计算+数据仓库(离线计算)。例如对访问日志:
- 通过流计算实时显示大盘数据:当前PV、UV、各运营商信息。
- 每天晚上对全量数据进行细节分析,比较增长量、同步/环比,Top数据等。
互联网领域有两种经典的模式讨论:
日志服务提供模式比较偏向Lamdba Architecture。
LogHub/LogShipper一站式解决实时+离线场景
在创建Logstore后,可以在控制台配置LogShipper支持数据仓库对接。当前支持如下:
TableStore(NoSQL数据存储服务):
MaxCompute(大数据计算服务):
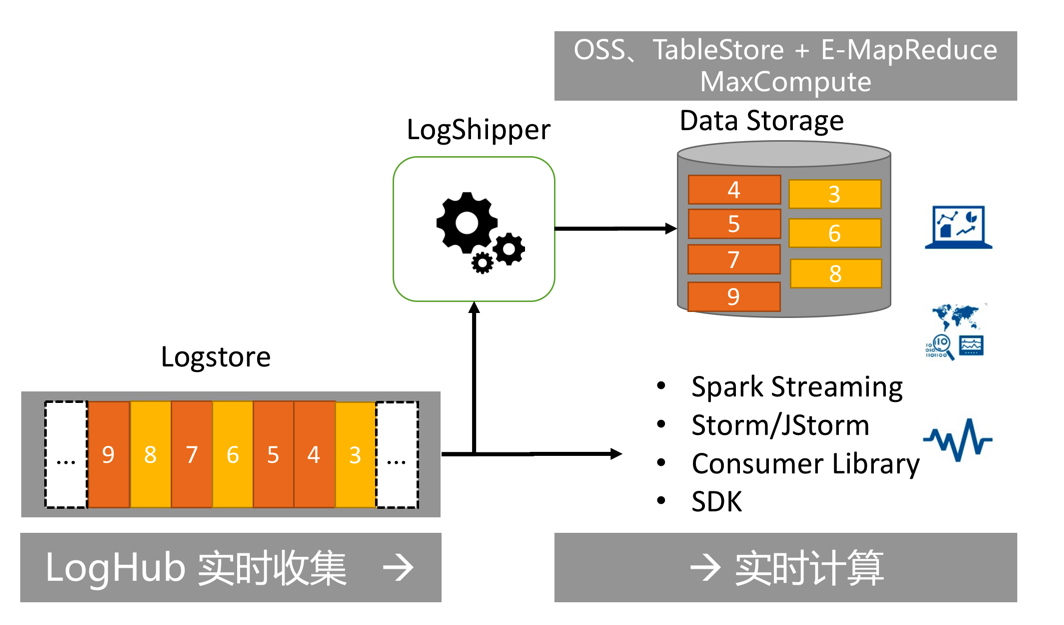
LogShipper提供如下功能:
- 准实时:分钟级进入数据仓库
- 数据量大:无需担心并发量
- 自动重试:遇到故障自动重试、也可以通过API手动重试
- 任务API:通过API可以获得时间段日志投递状态
- 自动压缩:支持数据压缩、节省存储带宽
典型场景
场景 1:日志审计
小A维护了一个论坛,需要对论坛所有访问日志进行审计和离线分析。
- G部门需要小A配合记录最近180天内用户访问情况,在有需求时,提供某个时间段的访问日志。
- 运营同学在每个季度需要对日志出一份访问报表。
小A使用日志服务(LOG)收集服务器上日志数据,并且打开了日志投递(LogShipper)功能,日志服务就会自动完成日志收集、投递、以及压缩。有审查需要时,可以将该时间段日志授权给第三方。需要离线分析时,利用E-MapReduce跑一个30分钟离线任务,用最少的成本办了两件事情。
场景 2:日志实时+离线分析
小B是一个开源软件爱好者,喜欢利用Spark进行数据分析。他的需求如下:
- 移动端通过API收集日志。
- 通过Spark Streaming对日志进行实时分析,统计线上用户访问。
- 通过Hive进行T+1离线分析。
- 将日志数据开放给下游代理商,进行其他维度分析。
通过今天LOG+OSS+EMR+RAM组合,可轻松应对这类需求。

