
对一些应用场景而言,需要实时收集公网数据 (例如,移动端、HTML 网页、PC、服务器、硬件设备、摄像头等)实时进行处理。
在传统的架构中,一般通过前端服务器 + Kafka 这样的搭配来实现如上的功能。现在
日志服务 的
loghub 功能 能够代替这类架构,并提供更稳定、低成本、弹性、安全的解决方案。
场景
公网有移动端、外部服务器、网页和设备数据进行采集。采集完成后需要进行实时计算、数据仓库等数据应用。
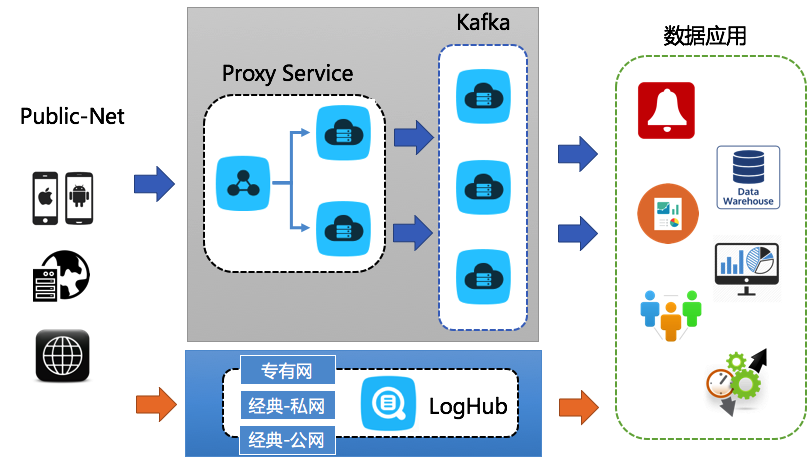
方案 1:前端服务器 + Kafka
由于 Kafka 不提供 Resful 协议,更多是在集群内使用,因此一般需要架设 Nginx 服务器做公网代理,再通过 logstash 或 API 通过 Nginx 写 Kafka 等消息中间件。
需要的设施为:
| 设施 | 数目 | 配置 | 作用 | 价格 |
| ECS 服务器 | 2 台 | 1 核 2GB | 前端机、负载均衡,互备 | 108 元/台*Month |
| 负载均衡 | 1 台 | 标准 | 按量计费实例 | 14.4 元/Month(租赁) + 0.8 元/GB (流量) |
| Kafka/ZK | 3 台 | 1 核 2GB | 数据写入并处理 | 108 元/台*Month |
| 设施 | 作用 | 价格 |
| loghub | 实时数据采集 | < 0.2 元/GB,参见 计费规则 |

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在实时收集公网数据并进行实时处理的应用场景中,如涉及移动端、HTML网页、PC、服务器、硬件设备及摄像头等数据源,传统上采用前端服务器结合Kafka的消息队列架构来实现这一需求。然而,阿里云日志服务的LogHub功能为这类应用场景提供了更为高效、经济和安全的解决方案。
由于Kafka本身不直接支持公网访问,通常需要借助Nginx作为代理,并通过Logstash或自定义API将数据转发至Kafka,增加了架构的复杂度和维护成本。
LogHub方案的优势在于: - 弹性伸缩:轻松应对从MB到PB级别的日志数据量,无需预先规划资源。 - 权限控制:提供细致的ACL(访问控制列表),确保数据的安全性。 - HTTPS支持:保障数据传输过程中的安全性。 - 日志投递免费:无缝对接数据仓库,无需额外开发工作。 - 详尽监控:提供全面的监控指标,帮助用户实时掌握系统状态。 - 丰富的SDK与集成能力:与阿里云及开源生态深度整合,简化上下游对接流程。
综上所述,对于公网数据采集的需求,LogHub相比传统的前端服务器+Kafka架构,在成本控制、操作便捷性、安全性和可扩展性方面展现出显著优势,是更优的选择。用户可通过访问日志服务主页进一步了解并体验该服务。
计费规则详情请参考阿里云官方文档。
