
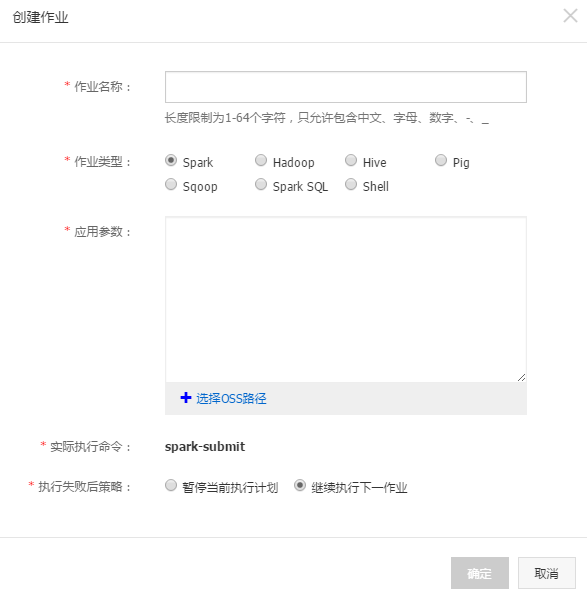
要运行一个计算任务,首先需要定义一个作业,其步骤如下:
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
从您的描述中,可以看出您已经对阿里云E-MapReduce(EMR)的作业创建流程有了较为清晰的理解。下面我将根据您提供的信息,进一步解释和补充一些关键点,以帮助您更好地利用阿里云EMR服务进行计算任务的部署与管理。
登录控制台:首先,通过阿里云官网登录到E-MapReduce控制台,选择对应的服务区域(Region),确保作业部署在正确的地理位置。
创建作业:点击“创建作业”,进入作业配置页面,开始定义作业的各项参数。
填写作业详情:
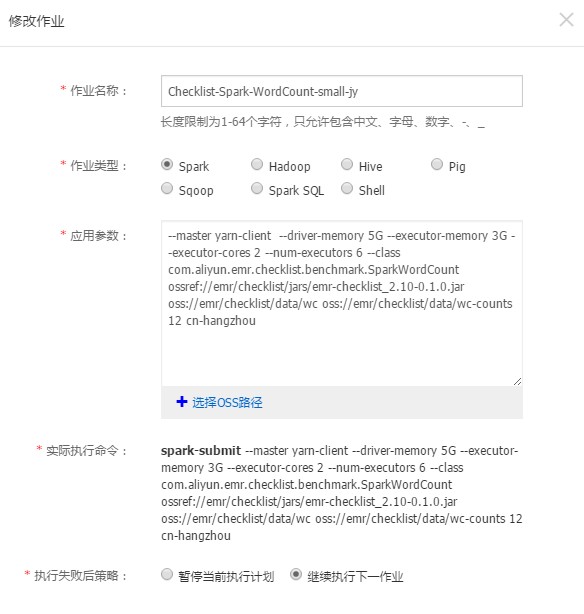
oss://和ossref://协议指定OSS上的资源。实际执行命令预览:系统会根据您的配置自动生成将在ECS上执行的实际命令,便于调试和直接在集群中手动执行。
失败策略:设定作业执行失败后的处理方式,是暂停整个计划等待人工干预,还是继续执行后续作业,以适应不同的业务场景需求。
oss://:用于直接访问OSS存储中的数据,作业执行时直接读写这些远程路径下的数据,适用于大规模数据处理场景,无需将数据下载到本地。
ossref://:提供了一种便捷的方式,允许用户指定OSS上的资源(如jar包或依赖文件),EMR会在作业执行前自动下载这些资源到集群节点的本地存储中,并替换命令行中的路径为本地路径。这种方式适合需要频繁用到某些代码或资源包的场景,减少了手动上传文件的操作,但需注意不要引用过大的文件,以免影响集群性能或导致作业失败。
ossref://时,确保下载的资源大小适中,避免因资源过大导致的下载时间过长或集群资源紧张问题。通过遵循上述指南,您可以高效地在阿里云E-MapReduce平台上设计、部署和管理各种大数据处理作业,充分利用云计算的弹性与效率优势。
