
E-MapReduce 集群适用场景很多。简单说来,Hadoop ecosystem 以及 Spark 能够支持的场景,E-MapReduce 都可以支持。因为 E-MapReduce 本质就是 Hadoop 和 Spark 的集群服务,您完全可以将其使用的阿里云 ECS 主机视为自己专属的物理主机。以下示例列出了 E-MapReduce 使用的经典场景。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
E-MapReduce(EMR)是阿里云提供的一种大数据处理服务,它基于Hadoop和Spark生态系统,为用户提供了便捷的集群管理和数据处理能力。您提到的几个场景正是E-MapReduce能够有效支持并广泛应用于实际业务中的例子,下面我将对这些场景进行详细说明:
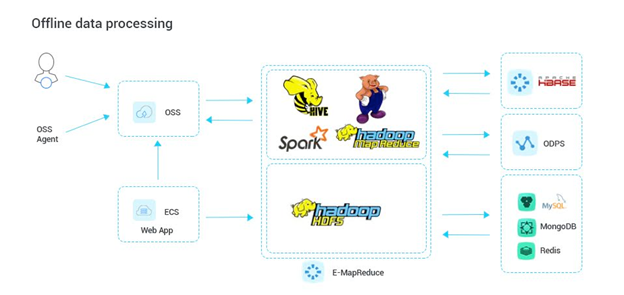
批量数据处理: 批量数据处理是指对大量静态数据集进行一次性或周期性的处理任务,如日志分析、点击流分析、用户行为分析等。E-MapReduce通过Hadoop MapReduce、Spark作业等工具,可以高效地处理这类大规模数据处理需求,实现数据的清洗、转换、聚合等操作。
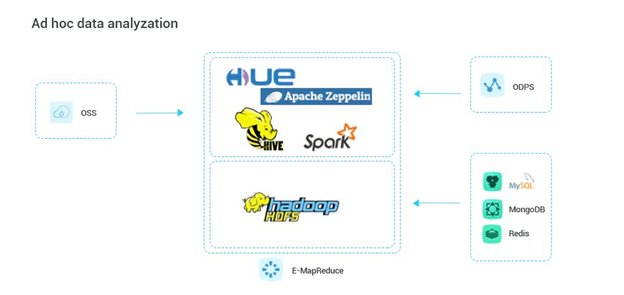
Ad hoc数据分析查询: Ad hoc查询指的是用户根据即时需要进行的灵活、非预定义的数据查询。E-MapReduce集成的Hive、Presto或Impala等技术,能够支持用户以SQL方式快速查询存储在HDFS上的海量数据,满足即席分析的需求,非常适合数据分析师进行探索性数据分析。
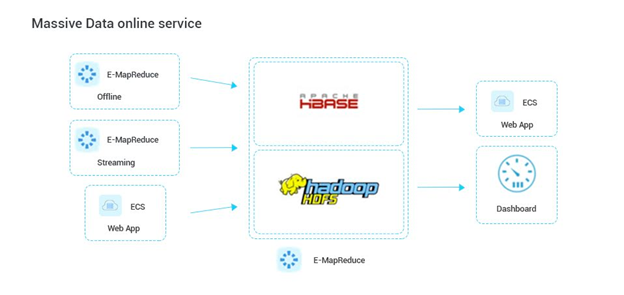
海量数据在线服务: 在线服务场景要求低延迟响应,对于需要实时或接近实时访问大数据的应用来说,E-MapReduce结合HBase、Druid等技术,可以支撑高并发、低延迟的数据读写操作,适用于实时推荐系统、实时计费系统等场景,确保数据能够迅速被应用所用。
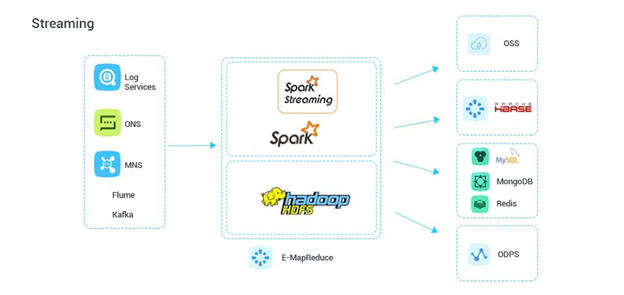
流式数据处理: 针对持续不断产生的数据流,如传感器数据、网站日志、交易记录等,E-MapReduce支持使用Apache Flink、Spark Streaming等流处理框架来实现实时数据处理与分析。这些框架能够处理高吞吐量的数据流,并能进行复杂的窗口计算、模式匹配等操作,适用于实时监控、预警系统、实时报表生成等场景。
综上所述,E-MapReduce以其灵活性、可扩展性和强大的数据处理能力,成为企业处理多样化大数据应用场景的理想选择。无论是离线批处理、交互式查询还是实时流处理,E-MapReduce都能提供稳定且高效的解决方案,帮助企业快速构建大数据处理平台。
