
Pentaho Data Integration(又称Kettle)是一款非常受欢迎的开源ETL工具软件。分析型数据库支持用户利用Kettle将外部数据源写入实时写入表中。
Kettle的数据输出程序并未为分析型数据库进行过优化,因此写入分析型数据库的速度并不是很快(通常不超过700 rec/s),不是特别适合大批量数据的写入,但是对于本地文件上传、小数据表等的写入等场景是非常合适的。
我们以导入本地excel文件为例,首先在分析型数据库中建立对应结构的实时写入表。然后用户可在
http://community.pentaho.com/projects/data-integration/ 上下载kettle软件,安装运行后,新建一个转换。
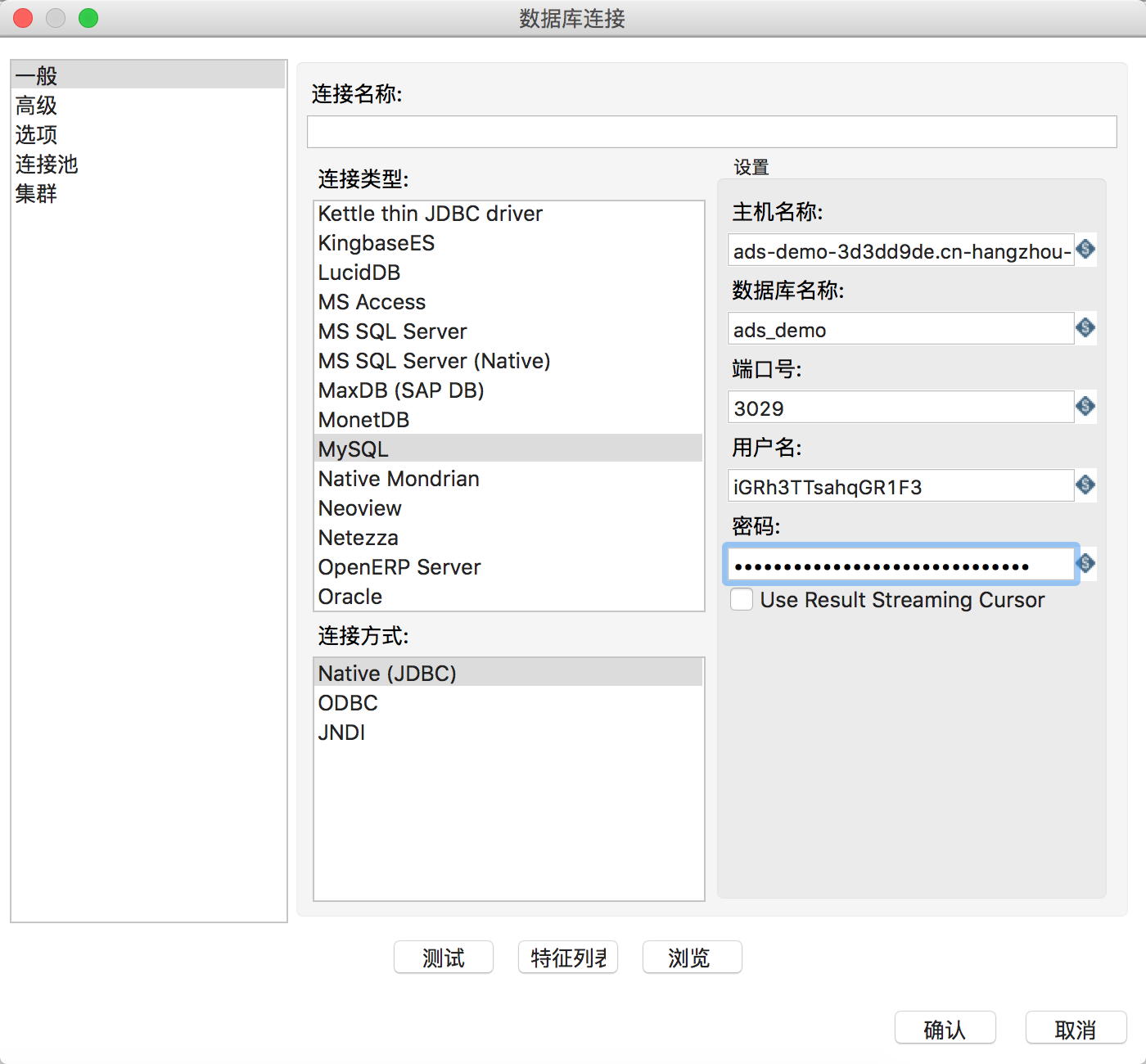
在该转换的DB连接中新建一项,连接类型选择MySQL,连接方式使用Native(JDBC)。主机名填写分析型数据库的连接域名,端口号填写链接端口号,用户名和密码填写access key信息,并去掉”Use Result Streaming Cursor”选项,如下图所示:
然后在kettle中,核心对象的“输入”中找到Excel输入拖拽到工作区,浏览并增加需要导入的Excel文件,根据实际需要设置工作表、内容、字段等选项卡,之后点击预览记录来查看输入的数据是否符合要求。
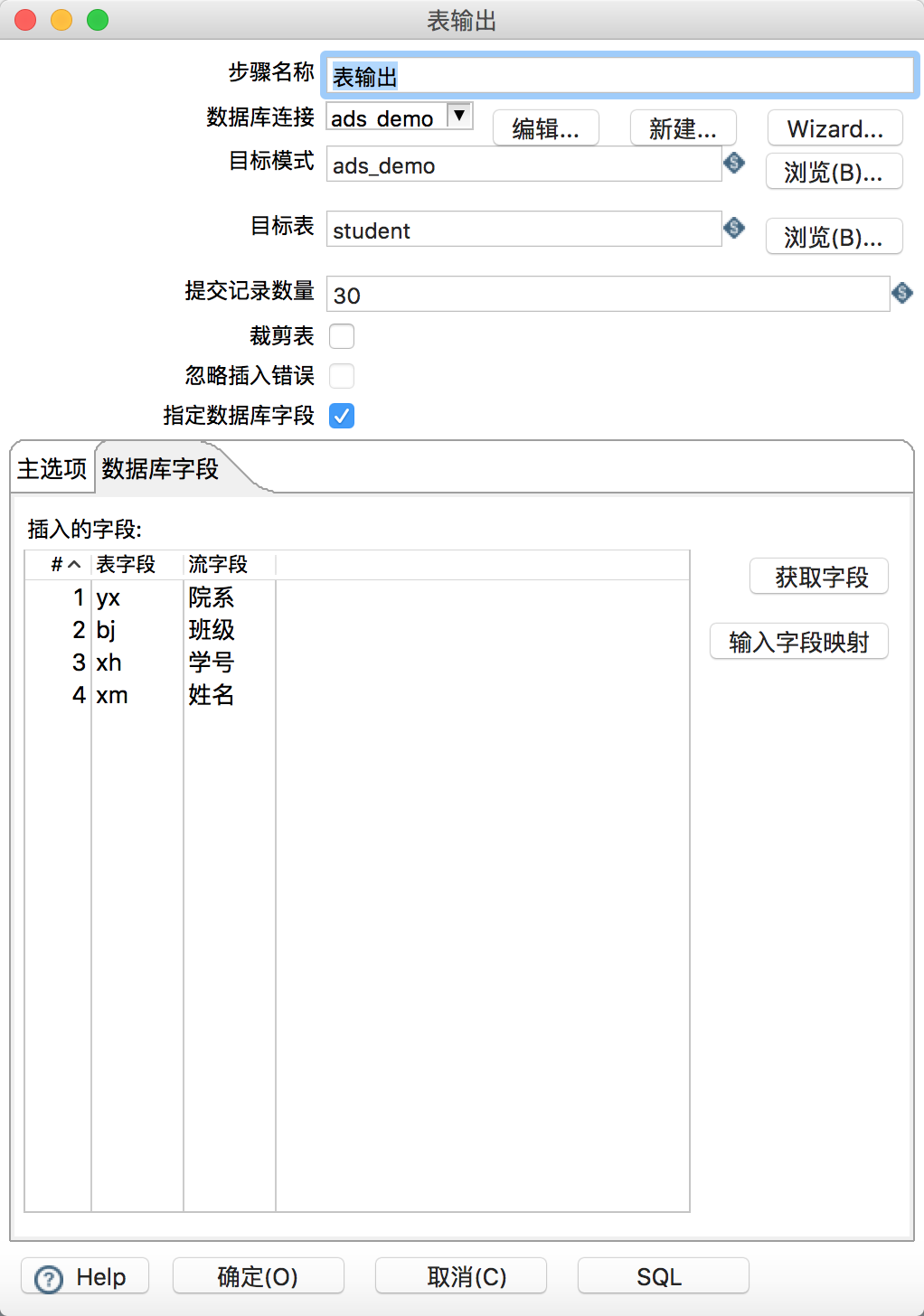
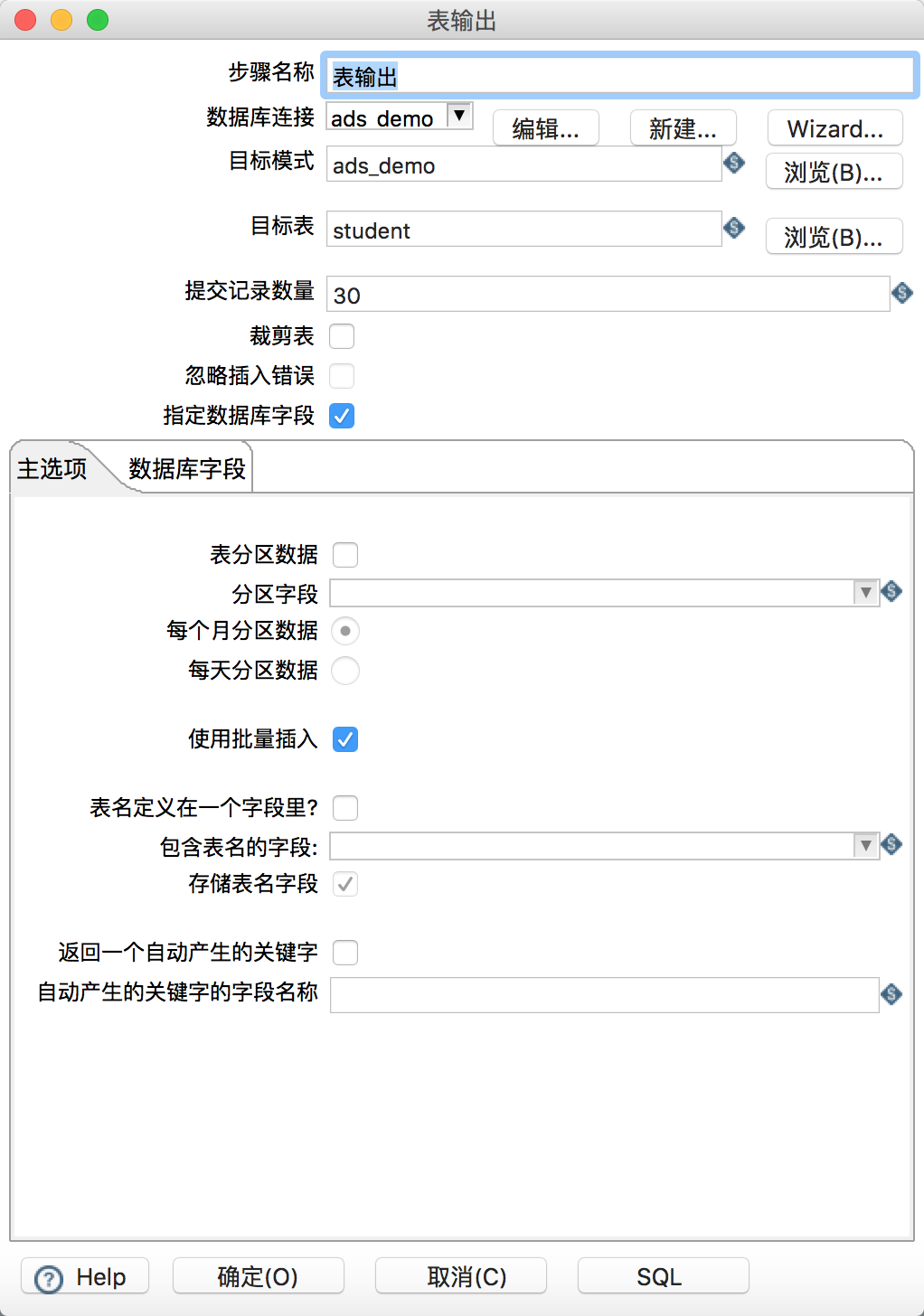
之后在核心对象的输出中找到表输出拖入工作区。新建一个从Excel输入指向表输出的连线。然后在表输出的属性中,手工填写目标模式(数据库名)、目标表名,暂不支持浏览功能。提交记录数量建议设置在30左右。选择“指定数据库字段”和“使用批量插入”,在数据库字段选项卡中点击获取字段和输入字段映射,映射excel文件的列与ads表的列名的映射关系,全部配置结束后如下:
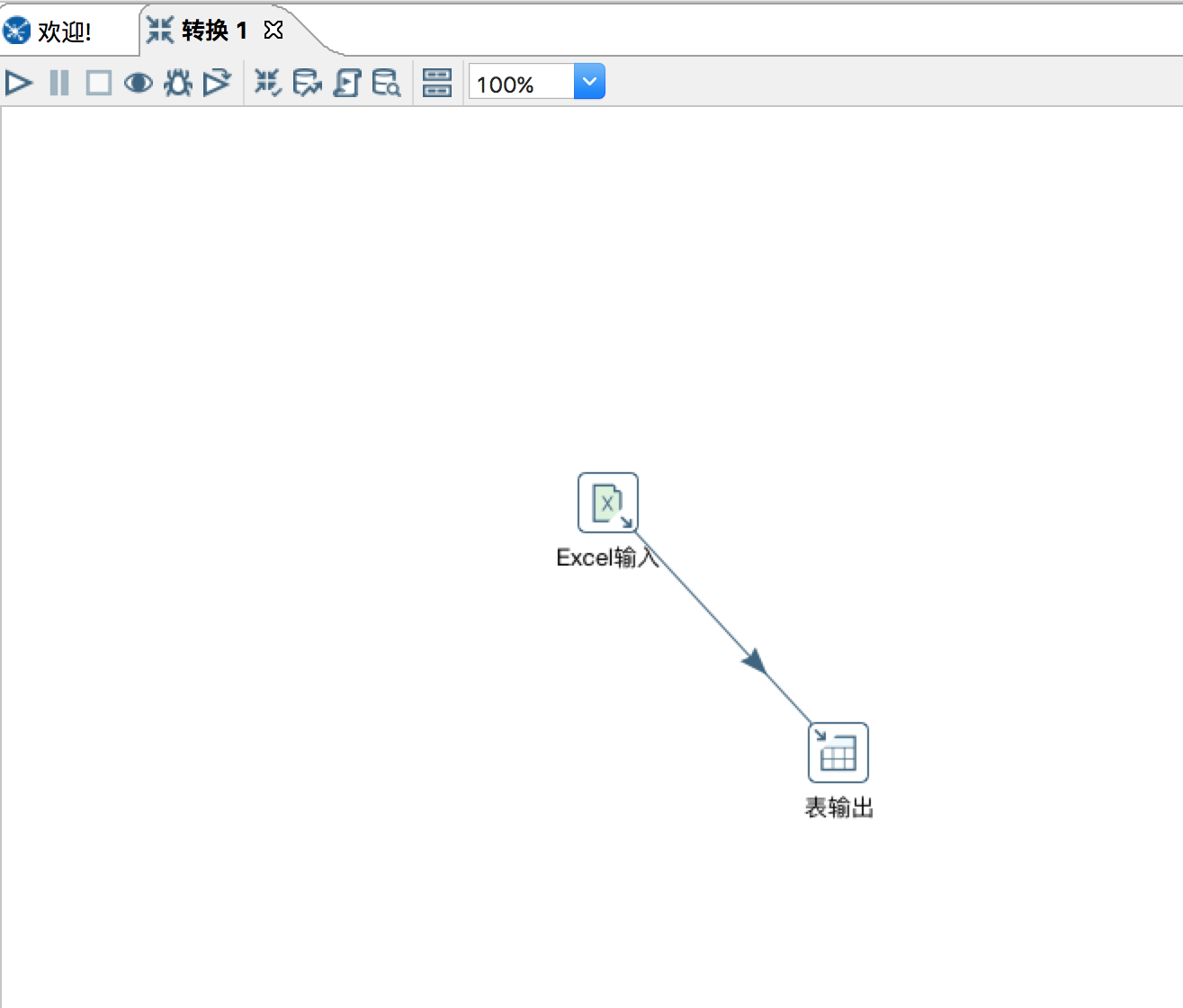
之后便可单击白色三角箭头运行这个转换,观察运行日志和运行状态即可。
Kettle拥有非常强大的过滤、数据格式转换、清洗、抽取等功能,更多的使用详情请参考Kettle官方文档。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您已经详细描述了如何使用Pentaho Data Integration (Kettle)将本地Excel文件导入阿里云分析型数据库(如AnalyticDB)的过程。这里补充一些可能对您有帮助的建议和注意事项,以进一步优化数据导入流程和性能:
批量插入优化:您已提到使用“使用批量插入”,这是提高写入速度的关键设置。根据实际测试情况,可以尝试调整提交记录数量参数,找到最适合当前数据量和网络环境的最佳值。有时候增加这个值(比如到500或1000)可能会进一步提升效率,但需注意不要超出系统或网络的处理能力。
并发执行:Kettle支持转换的并行执行。如果您的Excel文件很大或者需要导入多个文件,可以通过设计多个转换任务,并利用Kettle的作业功能来并行运行这些转换,从而显著提高整体导入速度。
JDBC驱动优化:确保使用了阿里云分析型数据库推荐的JDBC驱动版本,并检查驱动配置是否有进一步优化的空间,例如调整连接池大小、超时时间等。
数据预处理:在Kettle中进行必要的数据清洗、过滤和格式转换,减少不必要的数据冗余,可以有效提升导入效率。例如,提前去除空值、重复数据,或者在写入前完成数据类型转换。
资源监控:在执行大规模数据导入时,密切监控分析型数据库及Kettle服务器的CPU、内存和磁盘I/O使用情况,确保没有资源瓶颈影响导入性能。
分批导入策略:对于非常大的Excel文件,考虑先将其分割成多个小文件,然后逐个导入。这样不仅可以降低单次操作的风险,还可以更灵活地调整和优化导入策略。
网络优化:如果数据源与目标数据库不在同一区域,考虑网络延迟对性能的影响。尽可能让数据源和目标数据库处于同一地域或相近的网络环境中,以减少网络传输时间。
阿里云DataWorks集成:如果您是阿里云用户,也可以考虑使用阿里云DataWorks作为ETL工具,它提供了与阿里云各数据库服务深度集成的能力,可能提供更优的导入性能和更便捷的操作体验。
结合以上建议,您可以进一步探索和优化Kettle与阿里云分析型数据库之间的数据导入流程,以达到更高的效率和稳定性。
