
数据库服务器运行三年一直正常,最近cpu经常耗尽, 使用top -c观察,经常会大批量同时出现都是postgres用户的bind,这些bind把cpu耗尽,这时查询数据库也没有锁等待,查询pg_lock视图达到上千个锁,正常时几十个锁,另外比正常情况多了许多pg_statistics和这个表上索引的锁。
使用top -c观察,经常会大批量同时出现都是postgres用户的bind,这些bind把cpu耗尽,这时查询数据库也没有锁等待,查询pg_lock视图达到上千个锁,正常时几十个锁,另外比正常情况多了许多pg_statistics和这个表上索引的锁。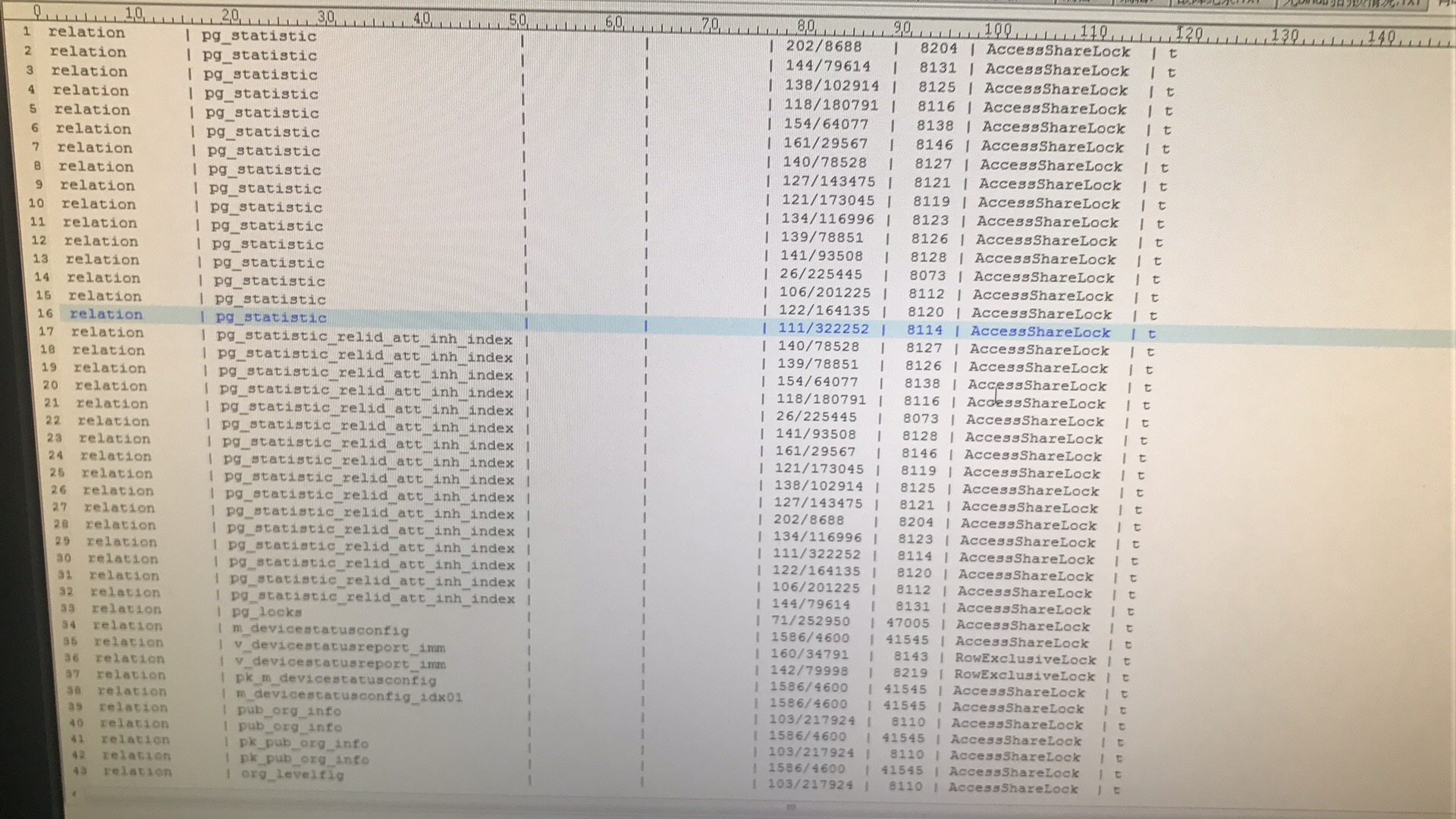 根据进程的pid查询到的sql都是操作一个相同的表,单独执行相当快.数据库所有的表使用vacuum analyze 已经分析过 问题依旧出现,请专家分析下@德哥
根据进程的pid查询到的sql都是操作一个相同的表,单独执行相当快.数据库所有的表使用vacuum analyze 已经分析过 问题依旧出现,请专家分析下@德哥
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
面对您描述的数据库服务器CPU耗尽问题,这可能是由多种因素导致的。根据您的描述,有几个关键点需要注意:
大量bind进程:通常,bind与DNS解析相关,但在这里可能是指PostgreSQL处理查询时的内部操作。如果这些操作消耗了大量CPU资源,可能是因为数据库正在执行大量复杂的查询或统计操作。
锁数量激增:pg_locks视图中锁的数量显著增加,特别是涉及到pg_statistics表和其索引上的锁,这可能意味着数据库正在进行大量的统计信息更新或者查询优化器频繁访问统计信息来制定执行计划。这在数据分布变化大、统计信息过时或查询模式改变时较为常见。
特定表的操作:所有引起高CPU使用的SQL都操作同一个表,这表明该表可能是性能瓶颈所在。可能是因为表结构设计(如缺少合适的索引)、数据分布不均、或是查询逻辑不够优化。
vacuum analyze操作后问题依旧:虽然进行了维护操作,但问题没有解决,这可能意味着问题并非单纯的数据碎片或统计信息陈旧造成。
针对上述情况,您可以尝试以下排查和优化措施:
检查慢查询日志:查看PostgreSQL的慢查询日志,找出那些频繁执行且耗时较长的SQL语句,针对性地进行优化。
分析查询计划:对于涉及大量锁和CPU消耗的查询,使用EXPLAIN (ANALYZE, BUFFERS)分析其执行计划,看是否有全表扫描、索引失效或不合理的连接方式等问题。
优化统计信息:考虑手动运行ANALYZE针对特定表,确保查询优化器能基于最新最准确的统计信息做出决策。如果自动统计收集间隔设置不当,也可能需要调整。
索引调整:确认是否需要为该表添加或优化索引,尤其是如果发现有频繁的全表扫描发生。
并发控制策略:考虑调整数据库的并发控制参数,比如max_connections、work_mem等,以及事务隔离级别,以减少锁争用。
定期维护:除了VACUUM ANALYZE,还可以考虑定期进行REINDEX操作,尤其是在索引使用频繁且数据变更大的情况下。
资源监控与限制:利用阿里云RDS PostgreSQL服务的性能洞察功能,监控数据库性能指标,及时发现并解决问题。同时,可以设置合理的资源使用限制,避免单个查询过度消耗资源。
如果以上方法仍无法有效解决问题,建议联系阿里云的技术支持团队,他们可以提供更深入的诊断和专业的解决方案。
