
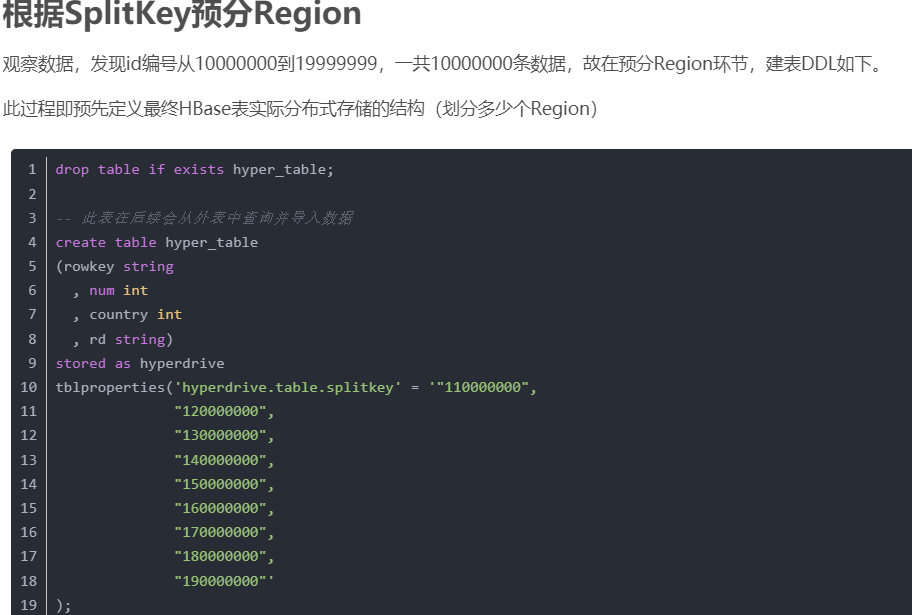
hdfs数据批量加载到hbase除了mr跑bulkload,才有上图的sql bulkload嘛?
本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
HDFS数据批量加载到HBase,除了使用MapReduce(MR)执行BulkLoad外,还有其他几种方法可以实现高效的数据导入。虽然直接提到的"SQL BulkLoad"在HBase中并不存在,因为HBase本身不是基于SQL的数据库,但这里可以理解为用户可能是在寻找类似SQL Bulk Insert那样高效的数据加载机制。以下是几种可行的方法:
MapReduce BulkLoad (HBase native bulk load): 这是最常见的方法,通过编写MapReduce作业来准备HFile(HBase的存储文件格式),然后直接加载到HBase表中。这种方法适用于大规模数据集的高效导入。
HBase Bulk Load Tool: HBase提供了一个命令行工具hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles,用于将事先生成好的HFiles加载到表中。这个工具可以在MapReduce作业生成HFiles后使用,提供了比直接使用API插入更高效的方式。
Apache Phoenix: 虽然HBase本身不支持SQL,但Apache Phoenix作为HBase上的SQL层,提供了类似于SQL的Bulk Load功能。你可以使用Phoenix的UPSERT ALL语句配合批量提交来实现大量数据的快速导入。这种方式下,Phoenix会自动优化写入路径,提高效率。
Spark Bulk Load: 利用Apache Spark进行数据处理和转换,然后通过Spark的HBase连接器或直接生成HFiles的方式来执行Bulk Load操作。Spark提供了比MapReduce更高的处理速度,适合大数据量的场景。
Hadoop DistCp + ConvertToSequenceFile + BulkLoad: 可以先使用DistCp将HDFS中的数据复制到Hadoop的SequenceFile格式,然后通过MapReduce作业或者其它工具将其转换为HFile格式,最后执行Bulk Load。这种方法适合于数据源已经是HDFS文件的情况。
选择哪种方法取决于你的具体需求、数据规模、现有技术栈以及对性能的要求。在阿里云上,如果你的应用部署在E-MapReduce环境中,可以利用其集成的Hadoop、HBase和Spark等服务,更加便捷地实施上述方案。
