
为什么requests.get异常后 print url在traceback后面打印出来呢?不是应该先打印url 再打印异常栈吗? 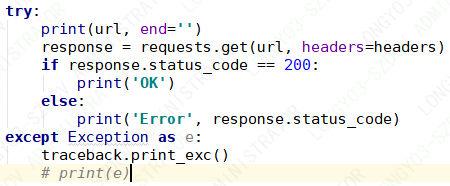
本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
1、Requests简介 Requests 是使用 Apache2 Licensed 许可证的 HTTP 库。用 Python 编写,真正的为人类着想。 python 标准库中的 urllib2 模块提供了你所需要的大多数 HTTP 功能,但是它的 API 太渣了。它是为另一个时代、另一个互联网所创建的。它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务。 总之,大家以后对urllib2库敬而远之就行了。来拥抱Requests吧。 Requests的官方文档:cn.python-requests.org/zh_CN/latest/ 通过下面方法安装requests [python] view plain copy pip install requests 2、Requests如何发送HTTP请求 非常简单,先导入requests, [python] view plain copy import requests 然后,按照下面的方法发送http的各种请求: [python] view plain copy r = requests.get('githubcom/timeline.json') r = requests.post("httpbin.org/post") r = requests.put("httpbin.org/put") r = requests.delete("httpbin.org/delete") r = requests.head("httpbin.org/get") r = requests.options("httpbin.org/get") 3、为URL传递参数 如果http请求需要带URL参数(注意是URL参数不是body参数),那么需要将参数附带到payload字典里头,按照下面的方法发送请求: [python] view plain copy import requests payload = {'key1': 'value1', 'key2': 'value2'} r = requests.get("httpbin.org/get",params=payload) print r.url 通过print(r.url)能看到URL已被正确编码: [python] view plain copy httpbin.org/get?key2=value2&key1=value1 注意字典里值为 None 的键都不会被添加到 URL 的查询字符串里。 4、unicode响应内容 [python] view plain copy import requests r = requests.get('githubcom/timeline.json') r.text 响应结果是: {"message":"Hello there, wayfaring stranger. If you're reading this then you probably didn't see our blog post a couple of years back announcing that this API would Go away: Git.io/17AROg Fear not, you should be able to get what you need from the shiny new Events API instead.","documentation_url":"developer.githubcom/v3/activity/events/#list-public-events"} Requests会自动解码来自服务器的内容。大多数unicode字符集都能被无缝地解码。请求发出后,Requests会基于HTTP头部对响应的编码作出有根据的推测。当你访问r.text之时,Requests会使用其推测的文本编码。你可以找出Requests使用了什么编码,并且能够使用r.encoding 属性来改变它 >>> r.encoding 'utf-8' 5、二进制响应内容 如果请求返回的是二进制的图片,你可以使用r.content访问请求响应体。 [python] view plain copy import requests from PIL import Image from StringIO import StringIO r = requests.get('cn.python-requests.org/zh_CN/latest/_static/requests-sidebar.png') i = Image.open(StringIO(r.content)) i.show() 6、JSON响应内容 Requests中也有一个内置的JSON解码器,助你处理JSON数据: [python] view plain copy import requests r = requests.get('githubcom/timeline.json') print r.json() r.json将返回的json格式字符串解码成python字典。r.text返回的utf-8的文本。 7、定制请求头 如果你想为请求添加HTTP头部,只要简单地传递一个 dict 给headers 参数就可以了。 [python] view plain copy import requests import json payload = {'some': 'data'} headers = {'content-type': 'application/json'} r = requests.get('githubcom/timeline.json', data=json.dumps(payload), headers=headers) print r.json() 注意,这里的payload是放到body里面的,所以params参数要使用json数据。 8、POST请求 就像上面‘定制请求头’中的例子,将payload序列化为json格式数据,传递给data参数。 9、POST提交文件 先制作一个text文件,名为‘report.txt’,内容是‘this is a file’。Requests使得上传多部分编码文件变得很简单: [python] view plain copy import requests url = 'httpbin.org/post' files = {'file': open('report.txt', 'rb')} r = requests.post(url, files=files) print r.text 返回结果是: [python] view plain copy C:\Python27\python.exe C:/Users/Administrator/PycharmProjects/flaskexample/postfile.py { "args": {}, "data": "", "files": { <strong>"file": "this is a file"</strong> }, "form": {}, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "160", "Content-Type": "multipart/form-data; boundary=a3b41a6300214ffdb55ddbc23dfc0d91", "Host": "httpbin.org", "User-Agent": "python-requests/2.7.0 CPython/2.7.9 Windows/2012Server" }, "json": null, "origin": "202.108.92.226", "url": "httpbin.org/post" } Process finished with exit code 0 10、POST提交表单 传递一个字典给 data 参数就可以了。数据字典在发出请求时会自动编码为表单形式: [python] view plain copy >>> payload = {'key1': 'value1', 'key2': 'value2'} >>> r = requests.post("httpbin.org/post", data=payload) 查看响应内容: >>> print r.text { "args": {}, "data": "", "files": {}, "form": { "key1": "value1", "key2": "value2" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "23", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.6.0 CPython/2.7.10 Windows/7" }, "json": null, "origin": "124.251.251.2", "url": "httpbin.org/post" } 11、响应状态码 使用r.status_code返回响应的状态码。 [python] view plain copy import requests r = requests.get('httpbin.org/get') print r.status_code 为方便引用,Requests还附带了一个内置的状态码查询对象: [python] view plain copy print r.status_code == requests.codes.ok 12、失败请求抛出异常 如果发送了一个失败请求(非200响应),我们可以通过 Response.raise_for_status()来抛出异常: [python] view plain copy import requests bad_r = requests.get('httpbin.org/status/404') print bad_r.status_code bad_r.raise_for_status() 返回结果是: [python] view plain copy C:\Python27\python.exe C:/Users/Administrator/PycharmProjects/flaskexample/postfile.py 404 Traceback (most recent call last): File "C:/Users/Administrator/PycharmProjects/flaskexample/postfile.py", line 5, in <module> bad_r.raise_for_status() File "C:\Python27\lib\site-packages\requests\models.py", line 851, in raise_for_status raise HTTPError(http_error_msg, response=self) <strong>requests.exceptions.HTTPError: 404 Client Error: NOT FOUND</strong> Process finished with exit code 1 如果返回码是200,则不会抛出异常,即: [python] view plain copy import requests bad_r = requests.get('httpbin.org/get') print bad_r.status_code bad_r.raise_for_status() 的返回结果是: [python] view plain copy C:\Python27\python.exe C:/Users/Administrator/PycharmProjects/flaskexample/postfile.py 200 Process finished with exit code 0 13、响应头 我们可以查看以一个Python字典形式展示的服务器响应头: 读取全部头部: [python] view plain copy r.headers 返回: { 'content-encoding': 'gzip', 'transfer-encoding': 'chunked', 'connection': 'close', 'server': 'nginx/1.0.4', 'x-runtime': '148ms', 'etag': '"e1ca502697e5c9317743dc078f67693f"', 'content-type': 'application/json' } 读取某一个头部字段: [python] view plain copy r.headers['Content-Type'] r.headers.get('content-type') 14、Cookies 得到响应中包含的一些Cookie: [python] view plain copy >>> url = 'examplecom/some/cookie/setting/url' >>> r = requests.get(url) >>> r.cookies['example_cookie_name'] 'example_cookie_value' 要想发送你的cookies到服务器,可以使用 cookies 参数: [python] view plain copy >>> url = 'httpbin.org/cookies' >>> cookies = dict(cookies_are='working') >>> r = requests.get(url, cookies=cookies) >>> r.text 返回结果: u'{\n "cookies": {\n "cookies_are": "working"\n }\n}\n' 15、重定向与请求历史 默认情况下,除了 HEAD, Requests会自动处理所有重定向。 可以使用响应对象的 history 方法来追踪重定向。 [python] view plain copy >>> r = requests.get('githubcom') >>> r.url 'githubcom/' >>> r.status_code 200 >>> r.history [<Response [301]>] 如果你使用的是GET, OPTIONS, POST, PUT, PATCH 或者 DELETE,,那么你可以通过 allow_redirects 参数禁用重定向处理: [python] view plain copy >>> r = requests.get('githubcom', allow_redirects=False) >>> r.status_code 301 >>> r.history [] 如果你使用的是HEAD,你也可以启用重定向: [python] view plain copy >>> r = requests.head('githubcom', allow_redirects=True) >>> r.url 'githubcom/' >>> r.history [<Response [301]>]
答案来源网络,供参考,希望对您有帮助
